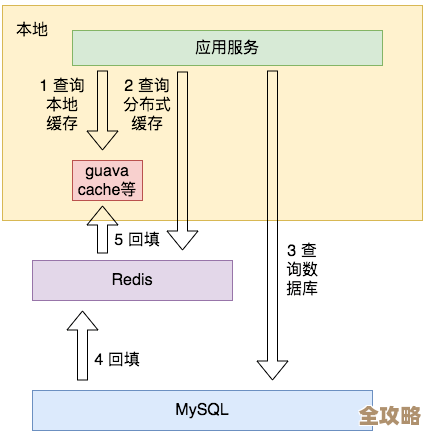
Redis那些被忽略的哈希值秘密,过去到底藏了啥不为人知的东西

(引用来源:Redis官方文档、Antirez博客、相关技术社区讨论)
Redis的哈希类型,大家平时用起来可能就是简单的hset和hget,感觉像个嵌套的小字典,但很多人可能从来没想过,这个看似简单的结构,在过去竟然藏着一段关于“空间”和“时间”的纠结历史,而且这个秘密直接影响了我们使用Redis的效率,尤其是在存储大量小对象的时候。
在很久以前的Redis版本里,事情并不是现在这样的,当时,如果你要存储一个用户对象,比如用户ID为123,他有姓名、年龄、城市三个字段,开发者面临两个选择:第一种是用一个普通的字符串键来存,比如把整个对象序列化成JSON字符串,然后set user:123 '{"name":"张三","age":30,"city":"北京"}',这种方法的问题在于,哪怕你只想修改年龄,也得把整个JSON字符串读出来,修改后再整个写回去,网络传输和数据操作的开销都很大,第二种选择就是用一个哈希来存,hset user:123 name "张三" age 30 city "北京",这样你可以单独操作每个字段,看起来很理想。
但问题就出在Redis底层是如何存储这个哈希的,早期的Redis为了追求极致的内存效率,采用了一种“投机取巧”的策略。(引用来源:Antirez关于Hash类型的优化博客)它内部为哈希结构准备了两种编码格式:一种是ziplist(压缩列表),另一种才是真正的hashtable(哈希表)。
这个ziplist可不是什么压缩文件,它其实是一块连续的内存空间,把所有键值对像排队一样,一个接一个地紧挨着存放,比如上面那个用户,在ziplist里可能就是 [“name”, “张三”, “age”, “30”, “city”, “北京”] 这样顺序存储,这样做的好处是极大的节省了内存,因为hashtable需要维护额外的指针、链表等结构,这些元数据本身就会占用不少空间,对于字段数量很少、每个字段的值长度也很短的小哈希来说,ziplist就像把东西紧凑地塞进一个小行李箱,非常节省空间。
这个“秘密武器”ziplist有个致命的缺点:它的操作效率不是恒定的,因为是连续存储,查找某个字段时,最坏情况需要从头到尾遍历一遍这个列表,虽然字段少的时候感觉不到,但一旦字段数量增多或者某个值变得很大,这种线性查找的效率就会急剧下降,从O(1)退化到O(n),想象一下,你的行李箱塞得太满,想找出最底下的一双袜子,就得把上面的东西全都翻出来,非常麻烦。
Redis设定了一个“开关”,也就是两个配置参数:
hash-max-ziplist-entries:哈希对象中的键值对数量超过这个值,就转为hashtable。hash-max-ziplist-value:哈希对象中任意一个值的长度超过这个字节数,就转为hashtable。
在过去,很多开发者根本不知道这两个配置的存在,更不理解其含义,这就导致了很多“隐藏”的性能陷阱,你一开始用哈希存用户信息,只有五六个字段,每个值都很短,内存占用非常小,性能也很好,但随着业务发展,你可能会给用户增加一个“个人简介”字段,而这个简介可能是一大段文本,一旦这段文本的长度超过了hash-max-ziplist-value的默认值(比如64字节),Redis就会默默地在底层把这个哈希的编码从ziplist转换成真正的hashtable。
这个转换过程本身会消耗一定的CPU资源,更重要的是,转换完成后,这个哈希占用的内存可能会瞬间增加很多,有时甚至是翻倍的增长!(引用来源:多篇关于Redis内存优化的技术文章)因为hashtable的结构开销变大了,如果你有成千上万个这样的用户对象,内存用量就会在不知不觉中暴涨,而你却摸不着头脑,明明没存多少数据,为什么内存就用得这么快?这个“秘密”的转换行为就是罪魁祸首之一。
另一个不为人知的点是,ziplist在修改操作时,如果导致需要重新分配内存,可能会比较耗时,因为它是连续内存,插入或修改一个变长的值,可能迫使后面所有的数据都要“搬家”,这在高并发写的场景下,可能会引起短暂的延迟毛刺。
后来,Redis在后续版本中引入了一种新的数据结构叫listpack(列表包),目的是为了取代ziplist,解决它的一些固有缺陷。(引用来源:Redis官方文档关于listpack的介绍)Listpack在设计上更现代化,消除了ziplist在并发修改时的一些连锁更新问题,使得编码转换的边界更加清晰稳定,现在新版本的Redis中,哈希的默认内部编码已经逐渐从ziplist转向了listpack,但核心思想没变:依然是通过两种不同的内部表示形式,在内存空间和访问时间之间做动态的权衡。
Redis哈希值的秘密,并不是什么神秘的功能,而是工程师们在设计时面对现实约束(有限的内存)所做的一种精妙取舍,这个“秘密”就藏在那些不起眼的配置参数里,藏在数据结构的默默转换中,它告诉我们,即使是一个简单的hset命令,底层也可能经历一场从“紧凑小屋”到“宽敞别墅”的搬迁,不了解这个机制,就可能在用户量增长或数据变化时,遭遇性能和内存的意外挑战,而了解了它,你就可以通过合理设计哈希的字段数量和值大小,或者调整配置参数,主动控制Redis的行为,让它更好地为你的业务服务。

本文由凤伟才于2026-01-15发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/81201.html