ORA-10877并行恢复出错,远程处理故障修复方案分享

ORA-10877错误是Oracle数据库在进行介质恢复(Media Recovery),特别是并行恢复(Parallel Recovery)过程中可能遇到的一个棘手问题,这个错误信息通常伴随着类似“Error occurred at the remote site”(在远程站点发生错误)或“failure in recovery at remote site”(远程站点恢复失败)的描述,它意味着数据库试图利用多个进程(并行)来加速数据恢复,但这个恢复过程涉及到一个“远程”环节,这个环节出了故障,导致整个恢复任务失败,这里的“远程”不一定指物理上遥远的另一台机器,在Oracle的语境下,它更常指代同一个数据库实例内,但属于不同进程或线程之间的协作通信出现了问题。
问题发生的常见场景
这个错误通常出现在以下几种情况:
- 物理备用数据库(Data Guard)的恢复:这是最常见的场景,当主数据库的日志传输到备用数据库,备用数据库需要应用这些日志以保持与主库同步(这个过程称为MRP管理恢复进程),如果备用库在应用日志时启用了并行恢复,就可能遇到ORA-10877错误,来源:Oracle Data Guard概念与管理指南中提及的恢复进程交互。
- 主数据库自身的崩溃恢复(Crash Recovery)或实例恢复:当数据库非正常关闭(如服务器断电)后重新启动时,Oracle会自动进行实例恢复,以将数据文件恢复到一致性状态,如果数据库参数设置了并行恢复,且系统资源或内部通信出现异常,也可能触发此错误,来源:Oracle数据库管理员指南中关于实例恢复的章节。
- 使用
RECOVER DATABASE命令的手动恢复:DBA在执行手动的数据库恢复操作时,如果启用了并行选项,同样可能面临此问题。
导致错误的根本原因分析

ORA-10877错误的根本原因可以归结为并行恢复过程中,“协调进程”与一个或多个“并行恢复从属进程”之间的通信或协作中断,具体可能包括:
- 资源竞争与耗尽:这是非常普遍的原因,并行恢复会消耗大量的系统资源,特别是CPU和I/O,如果系统当时负载已经很高,或者操作系统、存储系统的资源(如信号量、共享内存)不足,就可能导致某个从属进程无法正常获取资源而“卡住”或崩溃,从而向协调进程报告失败,来源:基于Oracle支持服务笔记(MOS)中类似案例的共性总结。
- 网络问题(在Data Guard环境中):对于物理备用库,虽然日志文件已经传输到备用端,但在恢复进程需要从主库获取额外信息(如归档日志的特定部分)时,如果主备库之间的网络连接出现闪断或延迟过高,也可能导致远程处理失败。
- 软件缺陷(Bug):在某些特定版本的Oracle数据库软件中,可能存在与并行恢复相关的程序缺陷,这些Bug可能导致在特定条件下,并行恢复进程无法正确处理某些类型的数据块或重做记录,进而引发ORA-10877。
- 底层存储问题:如果存储阵列出现暂时性的I/O错误,或者某个数据文件或日志文件损坏,并行恢复进程在读取这些文件时就会失败,由于是并行操作,一个进程的失败会牵连整个恢复任务。
- 参数配置不当:与并行恢复相关的初始化参数(如
RECOVERY_PARALLELISM,PARALLEL_MAX_SERVERS等)设置不合理,可能超出了系统实际的承载能力,导致进程间调度紊乱。
远程处理故障的修复方案
解决ORA-10877错误需要根据上述可能的原因进行逐项排查,以下是一个实用的排查和修复步骤分享:

-
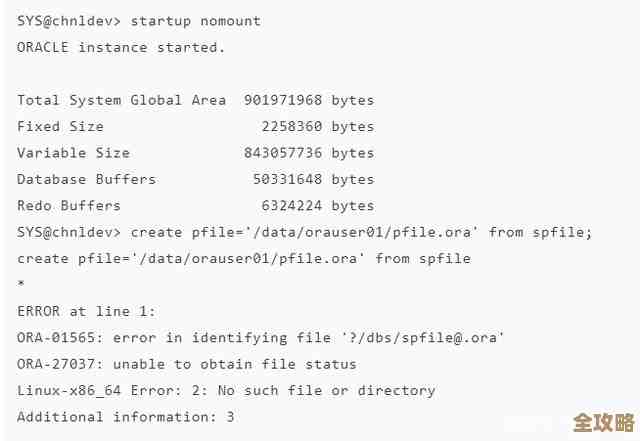
检查警报日志和跟踪文件:这是诊断任何Oracle错误的第一步,查看数据库的警报日志(alert_
.log),找到报错ORA-10877的具体时间点,在错误信息的前后,会有更详细的来自并行从属进程的跟踪文件记录,这些跟踪文件会指明是哪个进程失败了,以及失败时正在执行什么操作(正在读取哪个数据文件或归档日志),这是定位问题根源的关键线索,来源:Oracle数据库故障诊断指南的核心建议。 -
简化问题:尝试串行恢复:一个立竿见影的临时解决方案是关闭并行恢复,改为串行恢复,这可以立即判断问题是否由并行机制本身引起。
- 对于物理备用数据库,可以停止当前的恢复进程,然后以串行模式重启:
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL; ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION;(注意:第二个命令默认是串行恢复,如果要显式指定并行,需要加
USING CURRENT LOGFILE等参数,反之不加即是串行)。
- 对于主库的手动恢复,使用
RECOVER DATABASE命令时不指定并行参数。 如果串行恢复能够顺利进行,那么问题几乎可以肯定出在并行相关的环节(资源、Bug或参数)。
- 对于物理备用数据库,可以停止当前的恢复进程,然后以串行模式重启:
-
检查和调整系统资源:
- 监控系统资源:在启动并行恢复前和过程中,使用操作系统命令(如
top,vmstat,iostat在Linux/Unix上)密切监控CPU利用率、内存使用情况、磁盘I/O等待时间和网络带宽,确保系统有足够的空闲资源来支撑并行恢复带来的负载。 - 调整参数:如果资源确实紧张,可以考虑适当降低
RECOVERY_PARALLELISM的值(比如从4降到2),或者减少PARALLEL_MAX_SERVERS的数量,以减轻系统压力。
- 监控系统资源:在启动并行恢复前和过程中,使用操作系统命令(如
-
检查Data Guard网络连接:如果是备用库报错,使用
tnsping或sqlplus简单连接测试主备库之间的网络连通性和延迟,确保网络稳定,并且监听器工作正常。 -
检查文件完整性:
- 验证归档日志:确认从主库传输到备用库的归档日志是完整的,没有损坏,可以使用
RMAN的VALIDATE命令检查归档日志。 - 检查数据文件:使用
RMAN对涉及恢复的数据文件进行验证,排除底层存储损坏的可能性。
- 验证归档日志:确认从主库传输到备用库的归档日志是完整的,没有损坏,可以使用
-
搜寻已知Bug和应用补丁:访问Oracle官方支持网站(My Oracle Support),使用错误号ORA-10877以及你的数据库版本号(如11.2.0.4, 12.1.0.2等)和平台进行搜索,很可能你会发现这是一个已知的Bug,并且Oracle已经提供了相应的补丁程序(Patch Set Update - PSU 或 Bundle Patch),应用推荐的补丁是解决此类问题的最彻底方法,来源:Oracle官方支持网站(MOS)是查询Bug信息的唯一权威来源。
-
作为最后手段:如果以上方法均无效,且恢复必须进行,可以考虑更激进的方法,例如使用
RMAN进行基于时间点的不完全恢复,跳过有问题的重做记录(这会导致数据丢失,必须谨慎评估!),或者重建备用数据库。
处理ORA-10877错误需要一个系统性的排查思路,从查看日志开始,通过简化配置、检查资源、验证环境稳定性,再到搜寻官方修复方案,逐步缩小范围,最终找到并解决根本原因。
本文由帖慧艳于2026-01-15发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/81222.html