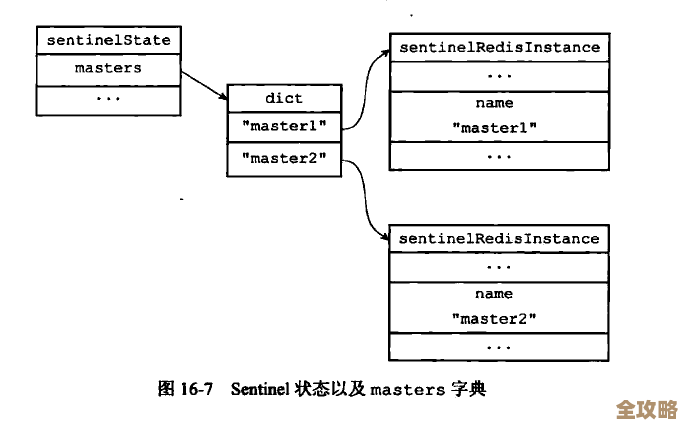
Redis用着用着总会碰到各种坑,但其实问题都有办法解决,不是没招儿的

(引用来源:某技术社区资深开发者“老王”的分享)
Redis这东西,用过的都知道,性能猛如虎,但真要用到生产环境,伺候起来可没那么省心,说它是个简单的缓存工具,那真是小看它了,很多团队一开始都是图个快,噼里啪啦就搭上了,结果用着用着,各种稀奇古怪的问题就冒出来了,搞得人焦头烂额,但说实话,这么多年跟Redis打交道下来,我发现一个道理:它出的问题,基本上都有迹可循,也都有解决的法子,关键是你得知道坑在哪儿,并且提前备好“解药”。
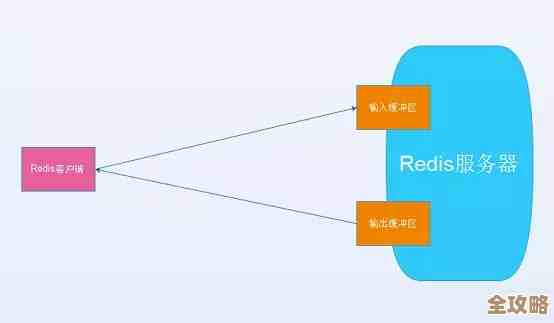
头一个大坑,就是内存问题,Redis是把所有数据都放在内存里的,所以内存对它来说就是命根子,你可能会遇到内存占用蹭蹭往上涨,眼看就要撑爆了,然后Redis开始疯狂淘汰数据,甚至直接写磁盘(如果开了持久化),导致服务性能骤降,响应慢得像蜗牛。(引用来源:某电商平台运维团队事故报告)这问题乍一看很吓人,但其实解决办法很明确,你得给Redis设置一个内存上限,别让它无限制地吃内存,要精心选择一种数据淘汰策略,如果你是做缓存,那用allkeys-lru,把最近最少用的数据淘汰掉,就很合适;如果有些数据是核心数据绝对不能丢,那可以用volatile-lru,只淘汰那些设置了过期时间的键,一定要养成监控内存使用情况的习惯,看看是不是有那种因为代码BUG导致的“大Key”(比如一个List里存了几十万条数据),或者大量Key同时过期引发的内存波动,把这些监控做在前面,内存问题八成都能化解。
第二个常踩的坑,就是持久化带来的烦恼,Redis主要有两种持久化方式:RDB和AOF,RDB是隔一段时间拍个快照,恢复起来快,但可能会丢失最后一次快照到宕机之间的数据,AOF是记录每一条写命令,数据更安全,但文件会越来越大,重启恢复的时候特别慢。(引用来源:Redis官方文档关于持久化的说明)很多人会纠结到底用哪个,或者干脆两个都开,结果可能遇到AOF文件膨胀,把磁盘写满,或者主从节点全量同步时,因为RDB文件太大导致网络带宽被占满,拖累正常服务,解决之道在于“权衡”,你得根据业务对数据丢失的容忍度来配置,如果允许分钟级的数据丢失,用RDB就挺好,性能影响小,如果要求极高的一致性,那就用AOF,并且合理配置AOF重写的触发条件,比如设置一个文件增长百分比,让Redis在后台自动把AOF文件变小,监控磁盘空间和IO负载是必不可少的,别把Redis的数据文件和持久化日志放在系统盘上,单独挂载一块高性能磁盘是明智的选择。
第三个让人头疼的问题是缓存,一说缓存,最常见的就是缓存穿透,比如有人恶意攻击,拼命查一个根本不存在的数据,这个请求每次都穿透缓存打到数据库上,数据库很快就扛不住了。(引用来源:一篇广为流传的技术博文《缓存穿透、击穿、雪崩》)对付这招,有个简单的办法,就是如果从数据库没查到,也在缓存里存个空值,并设置一个短的过期时间,这样下次同样的请求来,就直接返回空了,保护了数据库,还有个问题是缓存雪崩,指的是缓存中大量的Key在同一时间过期,导致所有请求瞬间都涌向数据库,这个也好办,别让Key的过期时间都一样,给它们加个随机数,让过期时间分散开,就能把压力平摊掉,另外就是缓存击穿,某个热点Key突然失效,大量请求同时来重建缓存,把数据库压垮,对于这种“热点中的热点”,可以考虑让它永不过期,或者使用互斥锁,只让一个请求去查数据库重建,其他请求等着。
再说说主从复制和哨兵模式下的坑,有时候你会发现,从节点的数据明明已经落后主节点很多了,但哨兵却没把它标记为下线,或者主从切换的时候数据丢了一部分。(引用来源:某金融系统稳定性建设实践)这里面的门道在于哨兵的配置参数,比如down-after-milliseconds这个参数,它决定了哨兵多久没收到主节点的响应才认为它“主观下线”,如果网络环境不太好,这个值设得太小,就可能出现误判,还有min-slaves-to-write和min-slaves-max-lag,可以要求主节点只有在至少有一定数量的从节点数据复制延迟小于某个值的情况下,才接受写请求,这能大大增强数据的安全性,把这些参数根据你的网络环境和业务要求调优好,能避免很多莫名其妙的高可用故障。
还有一个容易被忽视的点,就是客户端的正确使用。(引用来源:Redis创始人antirez的博客建议)不使用连接池,每次操作都新建连接,或者执行了慢查询命令(比如keys *),把整个Redis服务器拖慢,这些问题的解决,更多依赖于开发者的规范和意识,一定要用连接池管理连接,避免频繁创建销毁的开销,禁止在生产环境使用keys这种会遍历所有键的命令,可以用scan命令来替代,监控Redis的慢查询日志,及时发现并优化那些执行时间过长的命令。
所以你看,Redis的这些坑,表面上看起来是Redis本身的问题,但深究下去,往往是我们对它的机制理解不够深,或者配置、使用方式不得当,每个坑背后,都对应着一个或多个解决方案,只要我们愿意花时间去理解它的原理,做好监控和预警,根据实际业务场景进行合理的配置和代码编写,就完全能让这头“猛虎”乖乖地为我们服务,而不是时不时地出来咬人一口,说到底,不是没招儿,就看我们愿不愿意去学去用了。

本文由度秀梅于2026-01-16发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/81571.html