怎么用MSSQL搞定链接服务器,效率和稳定都得考虑下

链接服务器这个功能,就像是给MSSQL数据库开了一扇通往外部数据世界的窗户,通过这扇窗户,你的数据库可以直接查询和操作存放在其他地方的数据,比如另一个SQL Server数据库、Oracle、MySQL,甚至Excel文件,它的核心目的是为了方便地进行跨数据源的联合查询,这扇窗户如果开得不好,或者风太大(数据量大),就容易导致屋里(主服务器)又冷(性能差)又不安全(不稳定),怎么开好这扇窗户是关键。
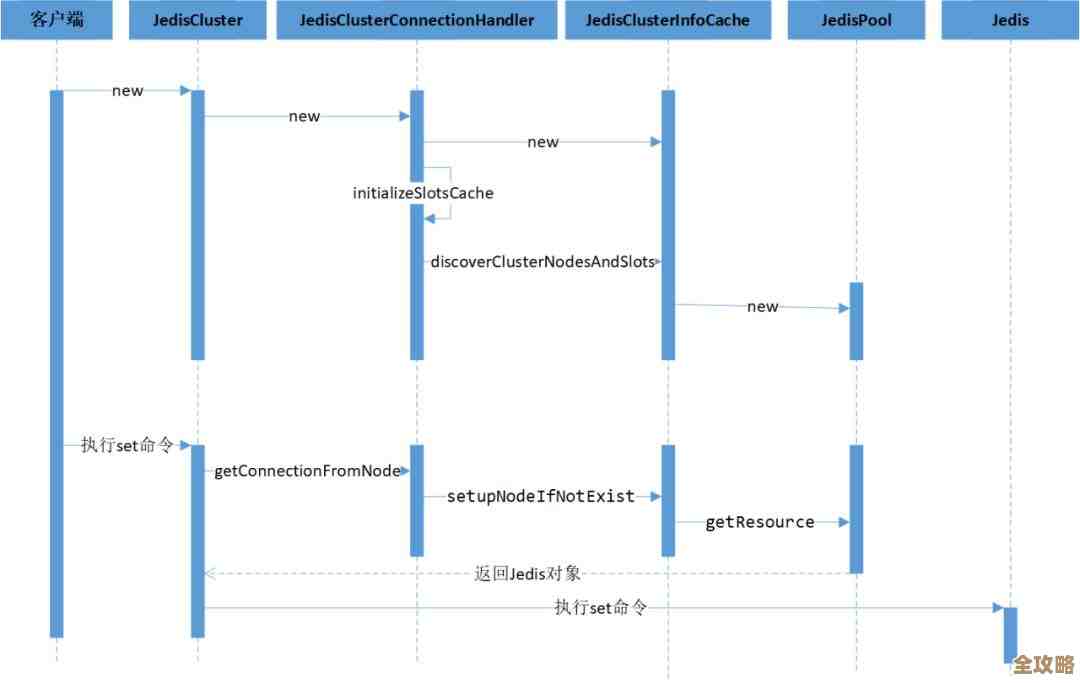
第一步:建立链接服务器(把窗户装上)
建立链接服务器本身并不复杂,最直接的方法是使用系统存储过程sp_addlinkedserver,你想连接到一个远端的SQL Server数据库,可以这么写:(来源:Microsoft Learn - sp_addlinkedserver文档)
EXEC sp_addlinkedserver
@server = 'MyRemoteServer', -- 给你这个链接服务器起个简单好记的名字
@srvproduct = '', -- 对于SQL Server,这个可以留空
@provider = 'SQLNCLI', -- 提供程序,SQLNCLI是用于SQL Server的较新OLE DB提供程序
@datasrc = '192.168.1.100\SQLEXPRESS'; -- 远端数据库的实际地址,可以是IP、机器名+实例名窗户装上了,但还没权限进去,所以接下来要配置登录信息,使用sp_addlinkedsrvlogin:(来源:Microsoft Learn - sp_addlinkedsrvlogin文档)
EXEC sp_addlinkedsrvlogin
@rmtsrvname = 'MyRemoteServer',
@useself = 'FALSE', -- 不使用当前登录的凭据去连接远程服务器
@locallogin = NULL, -- 对所有本地登录都应用这个规则
@rmtuser = 'remote_username', -- 远端数据库的用户名
@rmtpassword = 'remote_password'; -- 远端数据库的密码完成这两步后,理论上你就可以在你的数据库里用四部分名称来查询远端数据了:[链接服务器名].[数据库名].[架构名].[表名]。SELECT * FROM MyRemoteServer.MyRemoteDB.dbo.Customers。
如果只做到这里,很可能很快就会遇到效率和稳定性的问题,直接进行大量数据的查询,尤其是在网络条件不佳的情况下,可能会拖垮你的主服务器。
第二步:核心要点——如何兼顾效率与稳定性

这才是真正的重点,装窗户容易,但让窗户既通风又不进蚊子,需要些技巧。
-
*只取所需,切忌“SELECT ”* 这是最重要的一条原则,通过链接服务器查询,每一行数据都需要经过网络传输,如果你只需要三列数据,却用了`SELECT `(意味着查询所有列),会白白浪费大量的网络带宽和等待时间,一定要明确写出你需要的列名。(来源:普遍的性能优化实践)
-
把数据“请进来”处理,而不是“跑出去”计算 这是一个关键思维转变,看两个例子:
- 错误示范(跑出去):
SELECT COUNT(*) FROM MyRemoteServer.MyRemoteDB.dbo.BigTable WHERE Status = 'Active'这个查询会让远端服务器把整个BigTable表中所有Status为'Active'的行都通过网络发送到你的主服务器,然后由主服务器来计数,如果符合条件的行有上百万,网络传输就成了灾难。 - 正确示范(请进来):
EXEC ('SELECT COUNT(*) FROM BigTable WHERE Status = ''Active''') AT MyRemoteServer这个查询是直接把命令SELECT COUNT(*) ...发给远端服务器执行,远端服务器在本地完成计数这个繁重的计算工作,只将最终结果(一个简单的数字)通过网络传回来,效率天差地别,这里使用了EXEC ... AT语法来在远程服务器上执行命令。
- 错误示范(跑出去):
-
善用OPENQUERY进行“推送”查询
OPENQUERY是另一个实现“请进来”思想的强大工具,它允许你将一个完整的查询语句作为一个字符串发送到链接服务器执行。(来源:Microsoft Learn - OPENQUERY文档)SELECT * FROM OPENQUERY(MyRemoteServer, 'SELECT ID, Name FROM Customers WHERE CreateDate > ''20230101''')这样做的好处是,查询的过滤条件(WHERE CreateDate > '20230101')和列选择(只选ID, Name)都是在远端服务器上完成的,只有结果集被传输回来,这比SELECT ID, Name FROM MyRemoteServer...Customers WHERE ...这种写法更可靠,因为后一种写法有时可能由于查询优化器的判断,导致部分过滤操作被拉回主服务器执行,造成性能问题。
-
用于频繁操作的小结果集 链接服务器最适合的场景是查询那些需要实时关联、但数据量本身不大(比如几千行以内)的维度表或配置表,你的主数据库有订单表,但客户主数据存放在另一个专门的CRM数据库中,你可以通过链接服务器实时查询客户信息来关联显示订单详情,因为每次查询可能只关联几十个客户ID,数据量很小。
-
避免用于高频、大批量的ETL操作 如果你需要定期将另一个数据库的百万级数据同步过来,链接服务器直接进行
INSERT ... SELECT ...通常不是好主意,网络不稳定可能导致长时间锁表甚至任务失败,对于这种场景,更稳定的做法是使用SQL Server集成服务(SSIS)等专业的ETL工具,或者至少在远端服务器上先将大数据量导出为文件,再通过更高效的方式传输和加载。 -
连接池与超时设置 频繁地打开和关闭到远程服务器的连接本身也有开销,确保你的OLE DB提供程序支持连接池(通常默认是开启的),这样可以复用连接,如果查询复杂或远端服务器慢,可能会遇到超时错误,你可以通过查询提示或设置远程查询超时选项(
remote query timeout)来调整,但要谨慎,设得太长可能让问题被隐藏。 -
监控与故障排查 要关注性能计数器中与链接服务器相关的指标,如“Network Interface\Bytes Total/sec”来看网络压力,当查询慢时,使用SQL Server Profiler或扩展事件来跟踪到底哪个环节耗时,是远程执行慢还是网络传输慢,清晰的监控是保障稳定的前提。
用MSSQL搞定链接服务器,核心思想是“最小化网络传输”,把链接服务器当作一个只能通过小件物品的传送门,而不是可以随意穿梭的大门,通过OPENQUERY或EXEC ... AT将查询逻辑尽可能推到远端数据源执行,只让最终需要的小结果集通过网络,明确它的适用场景——实时、小数据量的跨源关联查询,而对于大数据量的同步任务,则应寻求更专业的工具和方法,这样才能在享受跨库查询便利的同时,保住主服务器的效率和整体系统的稳定性。
本文由帖慧艳于2026-01-16发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/81825.html