重新想了下Redis设计,改良思路和过程其实挺复杂,也有不少细节值得分享

这个重新思考Redis设计的过程,其实源于一次挺具体的线上问题,当时我们有个服务,用Redis存用户的会话信息,就是很常见的Key-Value结构,Key是用户ID,Value是一个JSON字符串,里面包含了登录状态、一些权限标识啥的,平时跑得好好的,但有一天用户量突然涨了一波,我们就发现Redis的内存用量飙升得有点吓人,而且响应时间也开始不稳定了。(来源:实际项目中的问题触发)
最开始的想法挺直接的,内存不够,加机器呗”,但这毕竟是治标不治本,而且成本也高,我们就静下心来想,到底问题出在哪儿,首先怀疑的就是那个JSON格式的Value,每个用户会话信息其实就十几个字段,但用JSON存,每次哪怕只更新其中一个字段(比如最后活跃时间),也得把整个JSON读出来,在应用层解析、修改、再序列化,最后整个写回去,这个过程网络开销大,CPU也浪费,更重要的是,如果两个操作同时改同一个用户的不同字段,还可能因为覆盖导致数据不一致,虽然我们可以用锁,但那又引入了复杂度。(来源:对初始方案JSON格式缺点的分析)
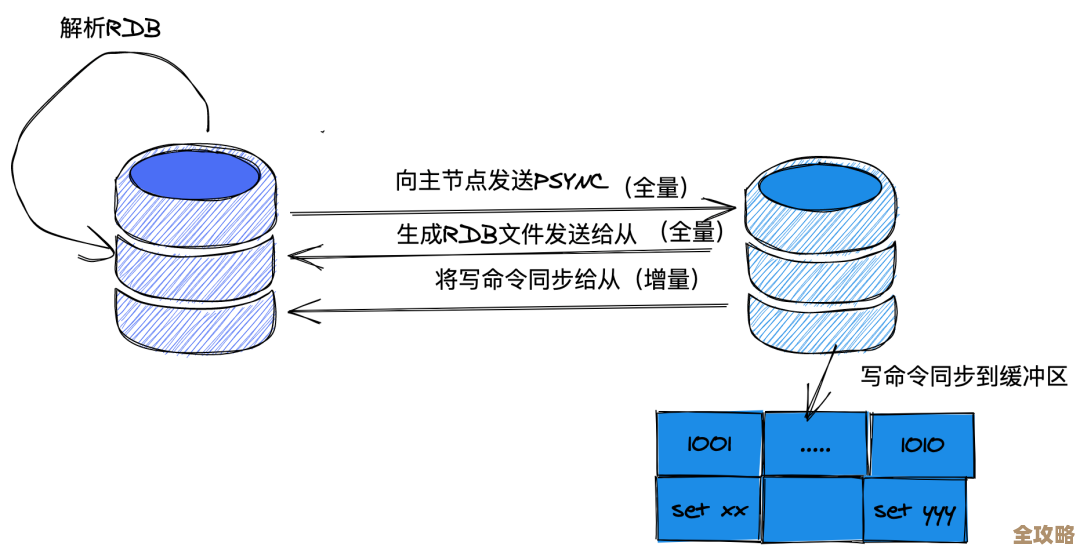
那不用JSON用啥呢?我们自然想到了Redis原生的数据结构,能不能把一个用户的信息用一个Hash来存?Key还是用户ID,但Value不再是一个字符串,而是一个Hash,里面的field就是各个会话字段,比如last_active, permissions等等,这样一做改造,好处立刻就出来了:更新最后活跃时间?直接发一条HSET user:12345 last_active <timestamp>就行了,只传输修改的部分,网络流量小了很多,操作是原子的,也不会影响到其他字段,查询特定字段也更快了,内存方面,虽然单个Hash结构会有一些元数据的开销,但对于我们这种字段不多但数量巨大的场景,总体内存使用率反而比存一大串JSON更优。(来源:从String JSON 到 Hash 结构的转变思路)
解决了单条数据的问题,我们又看整体的Key设计,以前就是简单的user_12345,很直白,但当我们想按模式批量操作,或者想统计某些类型的Key时,就有点麻烦,我们参考了Redis的最佳实践,把Key设计得更规范了一些,比如统一成对象类型:ID:子项这样的模式,像user:12345:session, order:67890:items,这样用KEYS或者SCAN命令的时候,模式匹配更清晰,也避免了不同业务之间的Key可能出现的冲突,虽然这是个很小的点,但对后期的运维和管理帮助很大。(来源:对Key命名规范的重新设计)
光优化数据结构还不够,数据总不能一直在Redis里长生不老吧?原来的过期策略比较粗暴,设一个固定的TTL,但我们发现不同用户的活跃度差异很大,有些用户登录一次可能再也不来了,有些则是高频用户,让不活跃的数据过早过期影响不大,但让死数据一直占着内存就太亏了,所以我们改进了过期策略,引入了一个简单的分级TTL,用户每次活跃操作都会刷新TTL,保证活跃用户的数据持久性;而对于一些一次性操作产生的缓存数据,则设置较短的固定TTL,这样动态和静态过期策略结合,更好地平衡了内存利用和缓存命中率。(来源:关于数据过期策略的细化考量)
我们还考虑了一个之前忽略的点:大Key,虽然我们用了Hash,但如果某个用户的会话信息因为业务扩展变得特别大(比如关联了非常多的权限列表),它依然可能成为一个“大Key”,在序列化、传输甚至迁移时可能引起延迟波动,对此,我们的思路是设定一个监控阈值,如果某个Hash的field数量或总体大小超过阈值,就触发告警,并考虑是否需要进行拆分,比如把一些不常访问的字段分离到另一个Key中去,用二次查询来换取操作的平滑性。(来源:对大Key问题的预防性思考)
整个改良过程就是这样,它不是一拍脑袋换个数据库就能解决的,而是像剥洋葱一样,从数据格式、Key设计、生命周期管理到潜在风险,一层层地去分析、试验和优化,每一个小的改进看起来都不起眼,但组合起来,对系统的稳定性、性能和可维护性提升却是实实在在的。

本文由称怜于2026-01-16发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/81980.html