字节跳动在云上搞大规模Spark Shuffle,折腾出一套挺有意思的演进方案

根据“DataFunTalk”平台发布的文章《字节跳动云原生 Spark 历史服务器演进》以及“字节跳动技术团队”官方公众号发布的《字节跳动 Spark 支持万卡模型推理实践》等资料,我们可以一窥字节跳动在云上处理大规模Spark Shuffle时,所经历的那段“折腾”出有意思方案的历程。
第一阶段:当“经典”遇上“云原生”,Shuffle成了拦路虎
Spark的核心计算模型是MapReduce,而Shuffle(混洗)是连接Map阶段和Reduce阶段的关键步骤,就是Map任务把中间结果写出来,Reduce任务再拉取自己需要的数据,在传统的、使用物理机的数据中心里,Shuffle数据通常被写在计算节点本地的硬盘上,这种方式简单直接,但问题也很明显:如果某个存有Shuffle数据的节点出故障了,或者Reduce任务被调度到一个离数据很远的节点上,网络传输就会成为瓶颈。
当字节跳动开始将大规模Spark作业迁移到云上,特别是拥抱以Kubernetes为代表的“云原生”环境时,这些问题被急剧放大了,云环境的特点是资源高度池化、弹性伸缩、按需使用,但同时也意味着计算节点是“短暂”的(可能随时被创建或销毁)和“无状态”的,把关键的Shuffle数据写在本地磁盘上,风险极高:
- 稳定性噩梦:如果某个节点突然宕机或被回收,它上面存储的所有Shuffle数据就丢失了,这会导致上游大量的Map任务不得不重新计算,严重影响作业效率,甚至导致作业失败。
- 资源浪费:为了等待Reduce任务来读取,Map任务完成后,其所在的节点和磁盘资源不能立刻释放,必须一直保留着,这在强调弹性和资源利用率的云环境下,是极大的成本浪费。
- 存储与计算耦合:云的优势是存储和计算可以分离,各自独立扩展,而本地Shuffle却把两者紧紧绑在一起,限制了调度的灵活性。
第二阶段:初试牛刀,引入外部存储系统
面对这些问题,字节跳动的工程师们首先想到的自然是“把Shuffle数据存到别处去”,他们引入了高性能的外部分布式存储系统,比如Ceph对象存储或HDFS。
这个方案直接解决了数据可靠性和存储计算耦合的问题,Shuffle数据被持久化到高可用的存储集群中,单个计算节点的失效不再会导致数据丢失;计算节点也真正实现了无状态,可以随时被回收,资源利用率大幅提升。
新的问题接踵而至:性能,Shuffle过程会产生海量的小文件(通常是几十KB到几MB),而像Ceph这样的对象存储,其设计初衷是为了存储大文件,对于海量小文件的读写性能并不理想,延迟很高,这导致Shuffle的读写速度成为整个Spark作业的瓶颈,拖慢了所有任务的执行,这就好比用一辆专门运货的大卡车去送快递,虽然一趟能拉很多,但频繁地停车、装一件小包裹、再开车,效率极其低下。
第三阶段:另辟蹊径,自研Remote Shuffle Service (RSS)
既然通用的外部存储不适用,字节跳动的团队决定“折腾”一套专门为Shuffle场景定制的方案,他们设计并实现了名为Remote Shuffle Service (RSS) 的系统。
RSS的核心思想是:构建一个专属于Shuffle的、高性能、可扩展的“数据交换中心”,这个方案有意思的地方在于它的架构:
- 专用集群:RSS是一个独立部署的服务集群,不与计算任务混部,它由一组Shuffle Server(混洗服务器)构成,专门负责接收、存储和提供Shuffle数据。
- 对计算节点透明:对于Spark的Executor(执行器)它们感知不到后端的复杂变化,Map任务不再是写入本地磁盘,而是通过网络直接推送到RSS集群;Reduce任务也是从RSS集群拉取数据,这个过程对Spark引擎本身是透明的。
- 针对性优化:RSS针对Shuffle数据“写一次、读多次”、海量小文件的特点做了大量优化,它会在内存中对来自多个Mapper的小文件数据进行缓冲和合并,最终形成更大的数据块再落盘,极大地减轻了磁盘I/O压力,它也采用了更高效的网络通信协议。
引入RSS后,效果立竿见影,它既具备了外部存储方案的优点(数据可靠、计算存储分离),又通过专用设计克服了性能瓶颈,作业的稳定性和资源利用率得到了保障,同时Shuffle性能相比直接使用对象存储有了数量级的提升。
第四阶段:持续演进,拥抱“存算分离”更深层次的优势
RSS的成功让字节跳动在大规模Spark on Cloud Native的道路上迈出了关键一步,但他们没有止步于此,而是继续深化这套方案的“有意思”之处。
他们进一步利用了存算分离架构带来的调度灵活性,由于Shuffle数据被安全地托管在RSS中,Spark的Driver(调度器)在调度Reduce任务时,可以完全不用考虑数据的位置,真正做到全局最优的资源调度,可以更激进地使用Spot实例(抢占式实例,价格便宜但可能被随时回收)来运行任务,即使这些实例中途被回收,也只需重新调度任务到新实例上并从RSS拉取数据即可,不会有数据丢失的风险,从而实现了大幅的成本优化。
字节跳动在云上大规模Spark Shuffle的演进,是一个典型的从“遇到痛点”,到“尝试通用方案”,再到“自研定制化方案”,并最终“享受架构红利”的过程,这套从实践中“折腾”出来的Remote Shuffle Service方案,巧妙地平衡了云原生环境的弹性、成本与大数据计算框架的性能、稳定性需求,成为支撑其内部超大规模数据分析和机器学习任务的关键基础设施。

本文由畅苗于2026-01-16发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/82079.html
相关文章
-

容器要快又稳,别忘了这些关键点,不然容易出问题
-
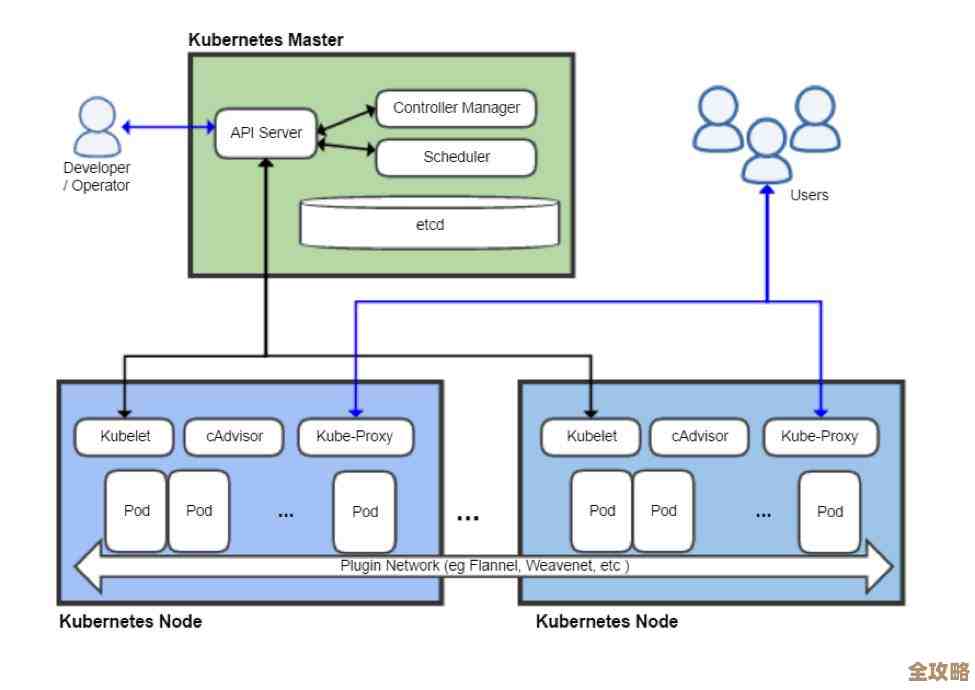
Kubernetes调度器到底怎么挑选节点和安排任务的那些事儿
-

租个MSSQL数据库,商业数据处理其实没那么难,轻松搞定需求真方便
-
PostgreSQL用着用着突然invalid_grant_operation报错了,远程怎么快速修复这故障呢
-
MySQL报错MY-012846和ER_IB_MSG_1021,远程帮忙修复故障全过程分享
-

MySQL报错4047,提示ER_WARN_SQL_AFTER_MTS_GAPS问题,远程帮忙修复故障方案
-
ORA-55468报错,规则库找不到或者没权限,远程帮你解决问题
-
ORA-00153 XA库内部错了,Oracle报错怎么远程修复处理指南