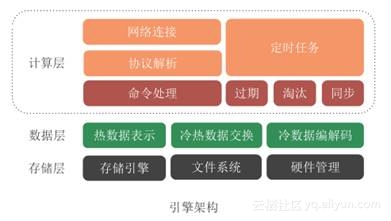
数据库数据混淆到底怎么避免才靠谱,防止出错的那些事儿

关于数据库数据混淆怎么才能有效避免,并且防止在操作过程中出错,这事儿确实让很多开发和运维人员头疼,咱们今天就不讲那些高大上的理论,直接聊点实在的,怎么一步步把它做踏实了。
最核心的一点,你得把“生产环境”和“测试/开发环境”彻底隔离开,这事儿听起来像是老生常谈,但很多出错的根源恰恰就在这里,根据很多团队踩坑的经验(例如一些知乎技术分享和CSDN博客上工程师的自述),绝对不能允许开发或测试人员为了图省事,直接连接生产数据库进行调试或功能验证,物理隔离是最佳实践,意思是测试环境用的数据库服务器就应该是一套完全独立的、数据是伪造出来的系统,心理上的隔离同样重要,要在团队里形成一种共识和纪律:碰生产库的数据是一件非常严肃、需要严格审批的事情。
测试环境需要的“像真的一样”的数据从哪里来呢?这就引出了第二个关键点:使用专门的、靠谱的数据混淆工具来生成测试数据,你不能简单地把生产数据拷贝一份到测试库,那样隐私和安全风险太大了,这里说的混淆,不是简单地把人名换成“张三”“李四”,把电话号码改成“13800138000”这种一眼假的数据,这种低级混淆不仅没啥用,还容易让测试人员产生误判。

靠谱的混淆工具(例如一些开源工具如Faker或商业数据脱敏平台)应该能做到以下几点:第一,保持数据的格式和关联性,身份证号码不仅要看起来像真的,前六位的地区码、中间的生日码和最后一位的校验码都应该符合规则;用户的注册时间和最后一次登录时间要有一个合理的先后顺序;用户ID和订单里的用户ID必须能对应上,不能出现订单找不到用户的情况,如果混淆后数据关联断了,那测试业务逻辑就毫无意义了,第二,对敏感信息进行不可逆的脱敏,真实的手机号可以通过算法变成另一个符合规则的、但无法反推回原号码的虚假号码;邮箱地址的域名可以保留,但用户名部分要替换掉,核心原则是“看起来真,查起来假”。
第三,建立一个清晰、可重复的混淆流程,并且尽量自动化,不能每次需要测试数据时,都靠人工手动执行一堆SQL脚本来“折腾”数据,这样极易出错,理想的做法是,编写自动化的数据混淆脚本或使用工具的调度功能,这个流程可以是这样:定期(比如每周)从生产环境备份中抽取数据 -> 自动运行已经验证过的混淆脚本 -> 将处理好的“干净”数据灌入测试环境,整个流程最好有日志记录,能清晰地看到每次混淆处理了哪些表、多少数据、有没有报错,这样一来,即使出了问题,也容易回溯和排查。

第四,权限管理要抠得细一点,在生产数据库上,遵循“最小权限原则”,意思是,给开发、测试、甚至是运维人员的数据库账户,权限要刚刚好够用,绝对不能给“ALL PRIVILEGES”这种超级权限,负责报表的开发人员可能只需要只读(SELECT)权限;需要定期清理数据的运维脚本,可能只需要授予对特定几个表和字段的删除(DELETE)或更新(UPDATE)权限,权限收得越紧,误操作的可能性就越低,对高风险操作(比如DROP TABLE, TRUNCATE TABLE)要格外警惕,可以考虑在数据库层面设置限制,或者要求必须由更高权限的DBA来执行。
第五,操作规范和安全意识不能少,技术手段再完善,人也可能犯错,要养成一些好的习惯,在执行任何对数据有修改的SQL语句前,先默默地加上BEGIN;开启一个事务,执行完先SELECT一下看看结果是不是你想要的,确认无误后再COMMIT;提交,万一不对劲,立马ROLLBACK;回滚,这条简单的纪律能救很多人的命,像Navicat、DBeaver这类数据库管理工具,通常会有“执行前确认”或“限制影响行数”的选项,把这些安全选项都打开。
别忘了备份这个“后悔药”,即使上面所有环节都做到了,也不能保证万无一失,对生产环境数据库进行定期备份,并确保备份数据是可用的,这是最后一道防线,在对生产数据做任何大的变更之前,额外做一次临时备份,是个非常稳妥的做法。
避免数据混淆出错,靠的不是某个单点的神奇技术,而是一套组合拳:环境隔离是前提,专业工具是手段,自动流程是保障,精细权限是约束,操作规范是习惯,定期备份是底线。 把这些事儿一件件落实,虽然不能保证100%不出问题,但绝对能把风险降到非常低的、可接受的水平。 参考了多位一线工程师在知乎、CSDN、开源中国等社区的技术实践分享,以及像《MySQL管理之道》等书籍中关于数据安全的最佳实践建议)
本文由瞿欣合于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/82397.html