Redis读写分离怎么搞才能又快又稳,性能提升其实没那么难

关于Redis读写分离如何做得又快又稳,其实核心在于理解其原理并避开一些常见的坑,这事情说难也不难,只要思路对了,效果是立竿见影的。
我们得搞清楚为什么要做读写分离。

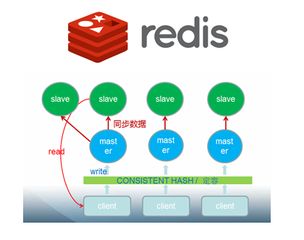
Redis本身速度已经非常快了,但在一些极端场景下,比如超高并发的电商秒杀、热门社交媒体的热点话题,所有的请求——既有写操作(发帖、扣库存)也有大量的读操作(浏览帖子、查看商品)——都压到同一台Redis服务器上,这台机器的CPU、内存和网络带宽可能就会成为瓶颈,读写分离的核心思想就是“分摊压力”,我们把写请求只发给唯一的一个主节点(Master),而把大量的读请求分散到多个从节点(Slave)上去,这样,主库专心处理写命令,从库专心服务读查询,从而实现水平扩容,提升系统的整体吞吐量。
具体怎么“搞”呢?最基本的一步就是搭建主从复制架构。

根据“Redis开发与运维”这本书里的说明,这个过程其实不复杂,你首先需要部署多个Redis实例,可以是在不同服务器上,也可以在同一台服务器的不同端口上,在每个从节点的配置文件(redis.conf)中,通过一行简单的配置 replicaof <masterip> <masterport>(旧版本可能是 slaveof)指定主节点的地址和端口,启动后,从节点会自动连接到主节点,并发起一次全量数据同步,之后主节点执行的任何写命令,都会近乎实时地异步同步给所有从节点,这样,一个最基本的主从集群就搭建好了,你的应用程序只需要配置一个支持读写分离的客户端,将写请求指向主节点,读请求以轮询或其他策略分发到从节点即可。
光搭起来还不够,要“稳”和“快”,还得在以下几个方面下功夫:

-
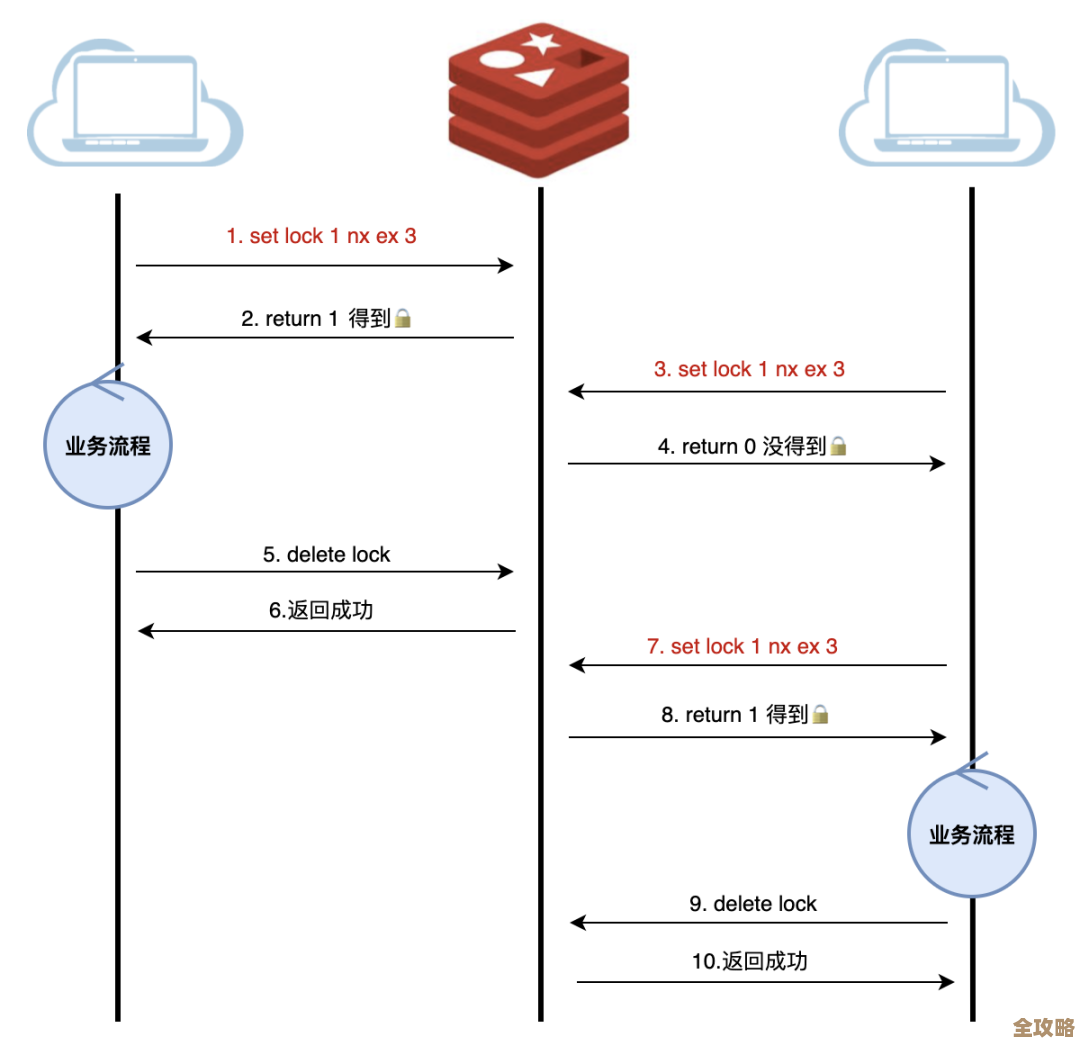
警惕数据不一致的“坑”:这是读写分离架构下最常遇到的问题,因为主从之间的数据同步是异步的,当主节点写完数据后,命令传播到从节点并执行会有一个极短的延迟(毫秒级),在绝大多数情况下这没问题,但如果你的应用场景要求“写后立即读”且必须读到最新数据(比如用户刚发布帖子后立刻跳转到详情页),这时如果读请求被分发到了一个尚未同步完成的从节点,用户就会看不到刚发的帖子,这就产生了数据不一致,解决办法有两种:一是对于这类有强一致性要求的读请求,直接将其强制发往主节点读取(俗称“强制读主”);二是可以监控主从复制的偏移量,但这种方式对应用侵入性较大,一般首选第一种。
-
处理好从节点的“慢”问题:从节点并不是越多越好,每个从节点在连接主节点进行全量同步时,主节点需要生成RDB快照并通过网络传输,这个过程会消耗主节点大量的CPU和网络IO,如果频繁发生(比如从节点宕机重启),反而会影响主节点的稳定性,正如“Redis设计与实现”中提到的,从节点在接收到主节点的RDB文件后,需要清空自身旧数据,然后加载RDB文件,这个加载过程是阻塞的,在此期间从节点无法提供服务,如果你的数据量非常大,这个加载时间会很长,导致该从节点长时间不可用,要确保从节点的硬件配置(尤其是磁盘IO速度)不能太差,并且要避免在业务高峰期进行增加从节点或从节点重启等操作。
-
别忘了读写分离不是万能的,主节点依然是单点:读写分离只解决了读压力的扩展问题,但写压力仍然集中在一个主节点上,如果写操作过于频繁,主节点还是会扛不住,主节点一旦宕机,虽然可以通过哨兵(Sentinel)或集群(Cluster)模式自动选举新的主节点,但在故障切换期间,整个系统会有短暂的不可写状态,对于写压力也巨大的场景,可能需要考虑使用Redis Cluster模式,它能在多个主节点间分摊数据(即分片),同时每个分片内部又可以有自己的从节点做读写分离,从而实现读写能力的全面扩展。
-
监控,监控,还是监控:一个稳定的系统离不开完善的监控,你需要密切关注几个关键指标:主从节点的内存使用率、网络输入输出流量、延迟(latency),尤其是主从之间的复制延迟(replication lag),一旦发现某个从节点的延迟持续增高,就意味着它可能快跟不上主节点的节奏了,需要及时排查原因(是否是机器负载过高、网络带宽不足等)。
让Redis读写分离又快又稳的关键在于:正确搭建主从架构是基础,深刻理解并规避异步复制带来的数据不一致风险是保证“稳”的前提,合理规划从节点数量与配置、避免其反向影响主节点是保证“快”的要点,同时清醒认识到读写分离的局限性,并辅以全方位的监控,才能真正让这个架构发挥出最大的威力,性能提升确实没那么难,关键在于细节的把控。
本文由度秀梅于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/82416.html