MySQL异步复制读失败报错怎么修复远程处理经验分享

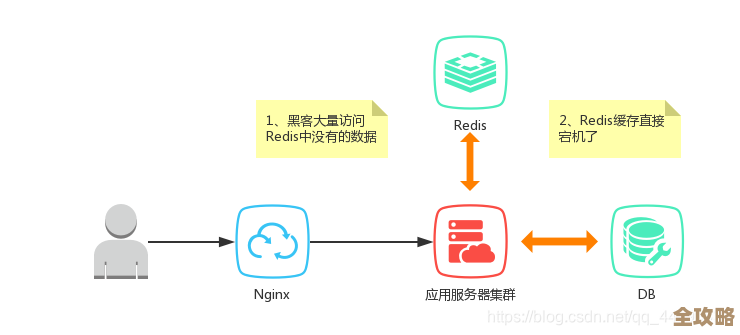
我之前在维护一个电商网站的后台时,就遇到过MySQL主从复制读失败的问题,当时的情况是,用户在后台查询订单数据时,经常会遇到页面卡住或者直接报错,提示查询失败,这个问题是间歇性出现的,时好时坏,给客服和运营团队带来了很大的麻烦,因为我们把读请求(比如查询订单、统计报表)都分配到了从库上,以减轻主库的压力,所以一旦从库出问题,这些功能就全受影响了。
第一步:先别慌,搞清楚报错到底是什么
当收到报警后,我第一件事就是登录到那台出问题的从库服务器上,查看MySQL的错误日志,这是最直接的信息来源,我记得当时日志里反复出现类似 “Could not execute Read_rows event” 或者 “Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND” 这样的错误信息,就是从库在根据主库传过来的日志,试图更新自己数据的时候,找不到要更新的那行数据了,这就好比主库说“把张三的年龄改成30岁”,但从库的名单里根本找不到“张三”这个人,于是从库就懵了,复制进程就停在那里报错。

第二步:分析原因,为什么从库会“丢数据”
根据网上一些技术社区像“开源中国”和“Stack Overflow”上很多人的经验分享,这种错误通常意味着主从库之间的数据已经不一致了,可能的原因有几种:
- 有人手贱在从库写了数据:这是最常见的原因之一,比如某个运维同学为了临时修复一个问题,直接连上从库手动修改或删除了一条数据,但主库并不知道这个操作,之后主库同步过来的修改指令就会因为找不到数据而失败。
- 复制延迟导致的数据差异:如果主库的写入压力非常大,从库可能因为性能跟不上而产生延迟,在这种延迟期间,如果主库上删除了某条数据,而从库还没来得及同步这条数据,之后主库又同步过来一个针对这条已删除数据的更新操作,从库也会找不到数据。
- 软件BUG或非正常关机:极少数情况下,可能是MySQL本身的bug,或者服务器突然断电导致从库的复制信息或数据文件损坏。
我当时首先排除了第3点,因为服务器运行稳定,重点怀疑是前两点,于是我去询问了团队里的其他成员,果然,前几天有一个同事为了快速处理一个脏数据,确实直接在从库上执行过一个删除操作,问题根源大概率就在这里。

第三步:制定修复策略,怎么把数据同步回来
知道原因后,修复的目标就很明确:让从库的数据和主库重新变得一致,当时我考虑了几个方案,这些方案在“阿里云开发者社区”的文档里也有类似的描述:
- 手动修补数据(治标不治本):对于只是少量几条数据不一致的情况,最快捷的办法是手动处理,我可以根据报错信息,找到缺失的那条数据的主键ID,然后去主库上查询这条数据的完整内容,再在从库上执行一条INSERT语句,把数据补回去,补完之后,再在从库上执行
STOP SLAVE; START SLAVE;重启复制进程,这个方法很快,但风险是,如果不止一条数据不一致,你可能会陷入“打地鼠”的游戏,补完一个错误,又冒出另一个。 - 重新搭建从库(彻底根治):如果数据不一致的情况很多,或者不确定到底有多少数据不一致,最稳妥、最彻底的办法就是重新搭建这个从库,这个过程大致是:
- 在主库上做一个全量备份(比如用
mysqldump命令)。 - 记录下备份时主库的二进制日志位置点(Position),这个非常重要。
- 停止从库的复制进程。
- 将从库的数据清空,然后导入主库的全量备份。
- 在从库上重新设置复制关系,指定从刚才记录的那个位置点开始同步。
- 启动复制进程。
- 在主库上做一个全量备份(比如用
考虑到我们之前已经有过人为误操作,并且为了长远稳定起见,我选择了第二种方案——重新搭建从库,虽然这会导致从库有几个小时不可用(期间读请求会全部 fallback 到主库,给主库带来短暂压力),但这是一劳永逸的办法。

第四步:操作过程与注意事项
操作是在凌晨业务低峰期进行的,我严格按照步骤来:
- 通知了所有相关人员,告知维护窗口和影响。
- 在主库使用
mysqldump --single-transaction --master-data=2命令进行备份,这个命令可以保证备份数据的一致性,并且会自动在备份文件里记录下二进制日志的位置。 - 备份完成后,我仔细核对了备份文件的大小和里面的位置点信息。
- 然后登录从库,停止Slave,然后清空对应的数据库。
- 导入备份数据,这个过程花了些时间,因为数据量不小。
- 导入完成后,由于备份文件里记录了位置点,我直接使用
CHANGE MASTER TO命令重新指向主库,并指定了位置点。 - 启动Slave,并使用
SHOW SLAVE STATUS\G命令密切监控Seconds_Behind_Master参数,看到这个值逐渐变为0,说明同步延迟已经追上,复制恢复正常。
经验总结与后续预防
这次远程处理让我深刻体会到:
- 权限隔离是关键:事后,我们严格限制了开发和生产环境对从库的写权限,原则上禁止任何人在从库执行写操作,如果需要处理数据,必须走流程在主库操作。
- 监控报警不能少:必须设置对从库复制状态(Slave_IO_Running, Slave_SQL_Running)和复制延迟(Seconds_Behind_Master)的监控,一旦出现异常能第一时间发现。
- 定期校验数据一致性:可以考虑使用 Percona 的 pt-table-checksum 这类工具,定期检查主从数据是否一致,防患于未然。
- 要有完整的备份和恢复预案:这次经历也相当于一次恢复演练,证明了我们的备份是有效的。
处理MySQL复制错误,核心思路就是“定位错误 -> 分析原因 -> 选择策略 -> 谨慎操作 -> 总结预防”,虽然过程有点紧张,但成功解决问题后,对整个系统的理解也更深了一层。
本文由度秀梅于2026-01-18发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/82958.html