Redis缓存数据量爆炸后,怎么优化才不崩溃,聊聊大规模缓存那些事儿

58沈剑的架构师成长之路系列技术分享)
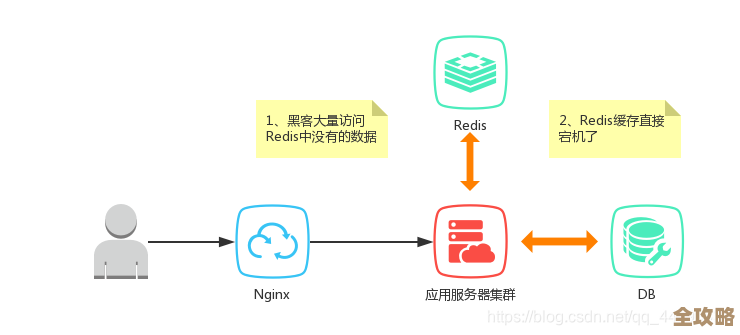
Redis这东西用着用着数据量就上来了,一不小心就占了几十G甚至几百G内存,这时候很多问题就冒出来了,机器内存眼看要撑爆,响应速度变慢,时不时还给你来个超时或者直接宕机,面对这种缓存数据量爆炸的情况,不能硬扛,得有点章法。

第一招,先得搞清楚内存都被谁吃了。 (来源:58同城缓存治理实践)你不能光看着总内存使用量干着急,得深入进去看,用Redis自带的命令,redis-cli --bigkeys,能快速扫一遍,找出哪些Key特别大,占地方最多,有时候可能就是那么几个大Key(比如一个巨大的List或者Hash)把内存啃掉了一大半,除了大Key,还得看看有没有“热Key”,就是被访问得特别频繁的Key,它们虽然不一定大,但压力集中,容易成为瓶颈,把这些“问题分子”找出来,是优化的第一步。
第二招,对症下药,处理掉这些大Key和热Key。 (来源:新浪微博热点数据缓存方案)找到了大Key,就好办了,如果是没必要存这么大的,就想办法拆,比如一个存了十万条用户评论的List,能不能按时间或者按页码拆成多个小Key?这叫大Key拆分,对于热Key,一个思路是复制多份,分散压力,比如给Key名字加个后缀变成多个相同的副本,这叫热Key备份,另一个更常见的办法是使用本地缓存,在应用服务器本地(比如用Guava Cache或Caffeine)也存一份热点数据,这样大部分请求根本不用走到Redis,压力自然就降下来了。

第三招,设定合理的过期时间,让数据能“自动消失”。 (来源:淘宝缓存架构设计心得)别把所有数据都设置成永不过期,除非是绝对必要的基础数据,大部分业务数据都是有生命周期的,给不同的数据设置不同的TTL(生存时间),让不常用的数据能及时被清理掉,甚至可以设置一个随机范围的过期时间,避免大量Key在同一时刻失效,导致缓存雪崩(瞬间所有请求都砸到数据库上),让缓存数据有进有出,形成流动,内存才不会被塞满。
第四招,考虑数据分片,把鸡蛋放到多个篮子里。 (来源:Redis官方集群方案)单台机器的内存总是有限的,当数据量真的非常大时,就必须把数据分散到多台Redis服务器上,也就是分片(Sharding),可以用Redis Cluster这种官方集群方案,它自动帮你把数据分到不同的实例上,也可以用像Codis这样的代理中间件,对应用层透明,分片之后,每台机器只存一部分数据,压力分摊了,容量也自然扩大了,这是应对海量数据的根本办法之一。
第五招,果断淘汰没用的数据。 (来源:美团缓存系统演进)Redis本身有内存淘汰策略,当内存不够用时,它会根据你的配置决定扔掉哪些数据,默认可能是noeviction(不淘汰,直接报错),这在生产环境很危险,通常我们会根据业务特点选择,比如allkeys-lru(淘汰最近最少使用的Key)或者volatile-lru(只淘汰设置了过期时间的Key中最近最少使用的),选对淘汰策略,相当于给Redis加了一个安全阀,内存快满时能主动释放空间,保证服务不会完全崩溃。
别忘了监控和报警。 (来源:各大互联网公司运维经验)光有策略不行,得时刻知道Redis的健康状况,内存使用率、Key数量、慢查询、命中率这些核心指标一定要监控起来,设置好报警阈值,比如内存使用超过80%就发告警,这样能给你留出反应时间来处理,而不是等服务器真的宕机了才发现。
面对Redis数据量爆炸,不是没辙,从分析内存使用入手,重点治理大Key热Key,用好过期时间和淘汰策略,在必要时进行数据分片,再配上完善的监控,就能让大规模缓存系统平稳运行,不至于崩溃,这些都是在实际业务踩坑中总结出来的实在办法。

本文由度秀梅于2026-01-18发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/82962.html