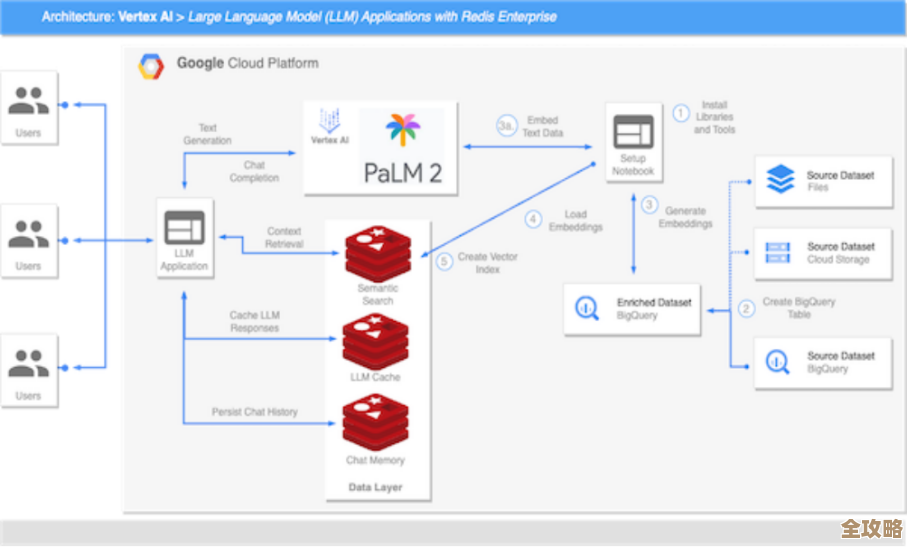
Oracle里汉字长度到底咋算,怎么解决那些长度不准的问题

关于Oracle数据库里汉字长度到底怎么算,以及如何解决由此引发的长度不准问题,这确实是很多开发者,尤其是涉及中文应用开发的同行们经常掉进去的一个“坑”,问题的核心根源在于Oracle数据库提供了两种主要的字符长度计算方式,如果你不清楚它们之间的区别,或者数据库的字符集设置,就很容易出现字段长度定义“看起来够用”,实际却报“值太大”错误的情况。
我们必须搞清楚Oracle计算字符串长度的两种基本方法:LENGTH 和 LENGTHB。
LENGTH函数计算的是字符串的字符个数,无论这个字符是英文字母、数字,还是一个汉字,在LENGTH函数眼里,它们都算作一个单位,你执行 SELECT LENGTH('你好AB') FROM dual;,返回的结果是4,因为“你”、“好”、“A”、“B”一共是4个字符,这种方式非常直观,和我们日常理解的“字数”是一样的。
而LENGTHB函数计算的是字符串的字节数,字节数就和我们数据库的字符集编码方式强相关了,对于中文环境,最常见的字符集是ZHS16GBK和AL32UTF8。
- 在
ZHS16GBK字符集下,一个英文字符(如A、B、1、2)占用1个字节,而一个汉字通常占用2个字节,同样执行SELECT LENGTHB('你好AB') FROM dual;,在GBK字符集的数据库里,结果是 2(你) + 2(好) + 1(A) + 1(B) = 6个字节。 - 在
AL32UTF8(UTF-8)字符集下,情况更复杂一些,一个英文字符仍然占用1个字节,但一个汉字的字节数可能是3个字节(绝大多数常用汉字)甚至更多,同样的字符串'你好AB',在UTF-8字符集的数据库里,LENGTHB的结果很可能是 3(你) + 3(好) + 1(A) + 1(B) = 8个字节。
“长度不准”的问题是如何产生的呢?
问题就出在我们定义数据库表字段时指定的长度约束上,当我们使用VARCHAR2(10)这样的语法时,这个“10”到底指的是10个字符还是10个字节呢?这在Oracle的不同版本和配置下是有区别的。
根据Oracle官方文档(如《Oracle Database SQL Language Reference》)的说明,在Oracle 12c及以后的版本中,有一个叫做MAX_STRING_SIZE的数据库参数,如果这个参数是默认的STANDARD,那么VARCHAR2(10)和CHAR(10)默认表示的是字节长度,但如果将MAX_STRING_SIZE设置为EXTENDED,那么VARCHAR2(10)默认表示的就是字符长度了。
这个默认行为的差异是导致问题的罪魁祸首,假设你的数据库是Oracle 19c,MAX_STRING_SIZE是默认的STANDARD,你创建了一个字段:address VARCHAR2(10),你的本意是允许存放10个汉字的地名,但事实上,这个字段允许的最大长度是10个字节,在UTF-8字符集下,10个字节最多只能存放3个汉字(3*3=9字节),存第4个汉字(需要3字节)时就会超过10字节的限制,从而抛出“ORA-12899: 值对于列 ... 过大”的错误,这时你就会感到困惑:“我明明定义的是长度10,怎么存4个字就不行了?”——这就是因为长度单位是字节,不是字符。
如何解决这些令人头疼的长度不准问题?
解决之道就在于“明确指定”,避免依赖数据库的默认行为,以下是几种直接有效的方法:
-
最推荐的方法:在定义表字段时显式指定长度语义 这是最一劳永逸的做法,Oracle允许你在定义字段时明确指明长度单位。
- 使用字符长度:
VARCHAR2(10 CHAR) - 使用字节长度:
VARCHAR2(10 BYTE)
如果你希望字段能容纳10个汉字,那么无论数据库的字符集和默认设置如何,你都应该使用
VARCHAR2(10 CHAR),这样,这个字段就能稳稳地存放10个汉字、10个英文或者任意组合,只要总字符数不超过10个即可,这种方式让表结构的设计意图非常清晰,避免了环境迁移或参数变更带来的潜在风险。 - 使用字符长度:
-
在程序中进行长度校验时,使用正确的函数 有时候问题不出在数据库层面,而出在我们的应用程序代码里,你在Java代码中用
String.length()方法(该方法计算字符数)来判断一个中文字符串是否超长,而你的数据库字段是用字节长度定义的,这就会导致判断失误。- 如果你的数据库字段定义为
VARCHAR2(10 BYTE),那么在程序中进行长度校验时,应该将字符串转换为数据库对应的字节编码(如UTF-8)后,计算其字节数。 - 如果字段定义为
VARCHAR2(10 CHAR),那么直接用字符串的字符数(如Java的String.length())来判断就可以了。 保持应用层和数据库层的校验逻辑一致至关重要。
- 如果你的数据库字段定义为
-
查询和调整数据库的字符集及默认长度语义 为了从根本上理解当前环境的行为,你可以查询数据库的相关配置。
- 查看字符集:
SELECT * FROM nls_database_parameters WHERE parameter = 'NLS_CHARACTERSET';这会告诉你数据库的字符集是ZHS16GBK还是AL32UTF8等。 - 查看默认长度语义:你可以通过查询数据字典
USER_TAB_COLUMNS中的CHAR_LENGTH和DATA_LENGTH字段来推断已有字段的定义,如果CHAR_LENGTH等于DATA_LENGTH,且字符集是多字节的,那这个字段很可能是按字节定义的,更直接的是,在定义新字段时,坚持使用第1点的方法,就不需要关心默认是什么了。 - 修改默认长度语义(需谨慎):在会话级或系统级,可以通过
ALTER SESSION SET nls_length_semantics = CHAR;来改变当前会话或系统的默认行为,但这通常不推荐,因为它会影响所有后续未显式指定单位的VARCHAR2和CHAR定义,可能对现有代码或其它应用造成意外影响,最好的实践还是在每个字段定义时写清楚。
- 查看字符集:
总结一下
Oracle汉字长度的“坑”主要源于字节长度和字符长度的混淆,解决这个问题的钥匙就是显式指定,记住这个黄金法则:在设计表结构时,只要涉及可能存储多字节字符(如中文、日文、韩文)的字段,一律使用VARCHAR2(N CHAR)来定义,这样,你关心的就是直观的“字符数”,而不是需要心算的“字节数”,从而彻底避免因字符集差异和数据库默认设置导致的种种长度不准问题。

本文由雪和泽于2026-01-18发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/83102.html