用Redis各种语句拼一拼,解决那些看着复杂的问题,写法也分享下

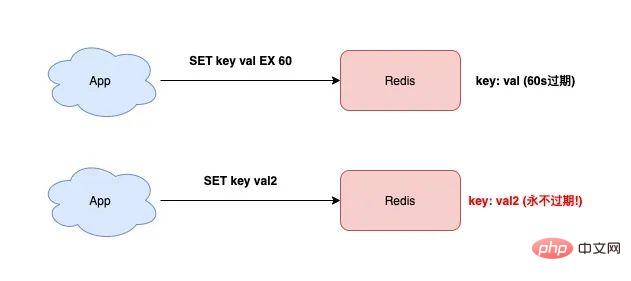
用SETNX和EXPIRE拼凑分布式锁
来源:这是Redis最经典的用法之一,几乎每个系统都会用到。
问题场景:很多台机器上的多个进程,要同时去修改数据库里的同一条用户数据,如果直接去改,很可能产生数据错乱,我们需要一个锁,保证同一时间只有一个进程能操作。
单看Redis命令,没有直接叫“LOCK”的命令,但我们能用现有的命令拼出来。
-
核心命令:SETNX 这个命令的意思是“SET if Not eXists”,只有当这个key不存在时,它才会设置成功,并返回1,如果key已经存在,设置就失败,返回0,这就像你去抢一个公共厕所,门把手上的牌子(key)如果没人拿(不存在),你就能拿到(SETNX返回1)并锁上门,如果牌子已经被拿走了(key存在),你就得在外面等着(SETNX返回0)。
-
写法步骤:
- 抢锁:
SETNX lock:user_id_123 my_secret_valuelock:user_id_123是锁的名字,我们把它和要操作的用户ID绑定。my_secret_value是一个随机生成的唯一字符串,比如可以用UUID,为什么要这个?后面会解释。
- 如果上面命令返回1,恭喜你,抢到锁了!但光抢到还不行,万一抢到锁的进程突然挂掉了,锁就永远不被释放,成“死锁”了,所以紧接着要:
- 设置锁的过期时间:
EXPIRE lock:user_id_123 10这表示10秒后,这个锁会自动过期被Redis删除,这样即使进程挂掉,锁最终也会释放,避免了死锁。
- 然后你就可以安心地去修改数据库了。
- 操作完成后,需要释放锁,释放锁不是简单用
DEL key吗?这里有个坑:你不能删别人的锁,比如进程A抢到锁,但操作超时了(超过10秒),锁被Redis自动释放,此时进程B抢到了锁,进程A这时执行完,如果直接DEL,就把进程B的锁给删了,所以删除前要检查这个锁是不是还是自己当初设置的那个,这就用到我们存的my_secret_value了。 - 安全释放锁(使用Lua脚本保证原子性):
if redis.call("GET", KEYS[1]) == ARGV[1] then return redis.call("DEL", KEYS[1]) else return 0 end- 这段脚本的意思是:先检查当前锁的值是否还是我当初设置的那个随机字符串
my_secret_value,如果是,才删除它;如果不是,说明锁已经不属于我了,直接返回。
- 这段脚本的意思是:先检查当前锁的值是否还是我当初设置的那个随机字符串
- 抢锁:
你看,一个完整的分布式锁,就是用SETNX、EXPIRE、GET、DEL这几个基础命令,再配合Lua脚本拼凑出来的,在更新的Redis版本中,可以直接用 SET key value NX EX 10 一条命令完成步骤1和3,更简单。
用ZSET和STRING拼凑延迟队列
来源:处理需要定时或延迟执行的任务,比如下单15分钟后检查是否支付。
问题场景:用户下单后,如果15分钟没支付,订单要自动关闭,你不能真的在程序里写个Thread.sleep(15 * 60 * 1000),这太浪费资源了,我们需要一个队列,能把任务“延迟”一段时间再执行。
Redis没有现成的延迟队列数据结构,但用有序集合(ZSET)可以很方便地实现。
-
核心命令:ZADD 和 ZRANGEBYSCORE
ZSET的每个元素都有一个分数(score),我们可以把“任务的执行时间戳”作为分数。
-
写法步骤:

- 投递延迟任务:
- 当用户下单时,计算15分钟后的时间戳(比如是1648888800)。
- 执行:
ZADD order:delay_queue 1648888800 order_id_10086 - 这里,
order:delay_queue是队列名,分数1648888800是执行时间,值order_id_10086是订单号。
- 有一个独立的进程(轮询器)不停地检查这个ZSET:
- 获取到期任务:
ZRANGEBYSCORE order:delay_queue 0 1648888700 WITHSCORES LIMIT 0 1- 这个命令的意思是:找出分数在0到当前时间戳(比如1648888700)之间的元素。
LIMIT 0 1表示每次只取1个。 - 如果找到了,比如找到了
order_id_10086,说明这个订单到支付检查时间了。
- 这个命令的意思是:找出分数在0到当前时间戳(比如1648888700)之间的元素。
- 处理任务:
轮询器把这个订单ID交给业务逻辑去处理(检查支付状态,未支付则关闭订单)。
- 从队列中移除已处理任务:
ZREM order:delay_queue order_id_10086防止被重复处理。
- 投递延迟任务:
这里有个细节,如果直接用ZRANGEBYSCORE获取并删除,不是原子操作,可能一个任务被两个轮询进程同时拿到,解决方法可以是用Lua脚本把“查询”和“删除”绑在一起原子执行,或者用更保险的方式:用ZRANGEBYSCORE拿到任务后,不直接删,而是把它塞进另一个普通的List队列(使用LPUSH),再由消费者从List里取走处理,这样即使多个轮询器同时拿到了同一个任务,也只有一个能成功塞进List(借助SETNX的思维),保证了任务不被重复消费。
用HYPERLOGLOG拼凑大数据量UV统计
来源:需要统计网站或文章的每日独立访客数(UV),数据量巨大,要求高性能且内存占用小。
问题场景:一篇爆款文章,一天有上千万人访问,如果用传统的SET来存每个访问者的ID(比如用户ID或IP),然后对SET求元素个数(SCARD),虽然准确,但内存消耗巨大,可能一个SET就几百MB。
这时候就可以用Redis的HyperLogLog(HLL)数据结构,它是个“估计算法”,特点是:占用内存极小(每个HLL只需要约12KB内存),能接受海量数据,并给出一个误差率很低(约0.81%)的近似估值。
-
核心命令:PFADD 和 PFCOUNT

PFADD用于添加元素。PFCOUNT用于统计基数(不重复元素个数)。
-
写法步骤:
- 用户访问时,记录一下:
PFADD uv:article:20240527 user_id_xxxuv:article:20240527是key,表示2024年5月27日这篇文章的UV集合。user_id_xxx是用户的唯一标识,你甚至可以放IP地址。
- 无论你这一天添加了几千万次,这个key占用的内存都稳定在12KB左右。
- 在当天结束时(或任何需要看数据的时候),统计UV:
PFCOUNT uv:article:20240527命令会返回一个近似值,12,345,678,这个数字可能和真实值有不到1%的误差,但在大多数业务场景(比如大数据看板、趋势分析)下是完全可接受的。
- 用户访问时,记录一下:
这种用空间换精度的思想,在处理海量数据时非常有用,如果你需要合并多天的数据(比如统计一周的UV),还可以用PFMERGE命令把7个HLL合并成一个。
用BITMAP拼凑用户签到功能
来源:App里常见的每日签到,需要记录用户连续签到了多少天。
问题场景:记录用户每个月是否签到,签到为1,未签到为0,如果用一个SET或LIST来存每天的签到状态,同样很浪费。
Redis的位图(BITMAP)本质上是STRING,但它允许你按位(bit)来操作,一个bit只有0或1两个状态,极其节省空间。
-
核心命令:SETBIT, GETBIT, BITFIELD
SETBIT设置某一位的值。GETBIT获取某一位的值。BITFIELD可以更复杂地操作多个位,比如一次设置多个值,或者进行自增。
-
写法步骤:
- 用户签到时:
SETBIT sign:user_id_123:202405 27 1sign:user_id_123:202405是key,表示用户123在2024年5月的签到记录。27是偏移量,代表这个月的第27天。1表示签到。
- 检查某天是否签到:
GETBIT sign:user_id_123:202405 27,返回1则表示已签。 - 统计本月签到次数:
BITCOUNT sign:user_id_123:202405,这个命令会直接计算出这个key里所有“1”的个数,也就是签到总天数。 - 计算连续签到天数(稍微复杂点): 这个没有直接命令,需要客户端程序从当天开始,用
GETBIT逐天向前检查,直到遇到0为止,虽然要循环,但因为bit操作非常快,效率依然很高。
- 用户签到时:
通过这几个例子能看到,Redis的强大不在于它有多少种复杂的数据结构,而在于它提供的这些基础命令(String, Hash, List, Set, ZSet, 以及 HyperLogLog, Bitmap, GEO等)像乐高积木一样,可以通过各种巧妙的组合(经常需要Lua脚本保证原子性),去解决那些看起来五花八门的业务难题,关键是要理解每个命令的特性和它们能组合出的模式。
本文由太叔访天于2026-01-19发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/83733.html