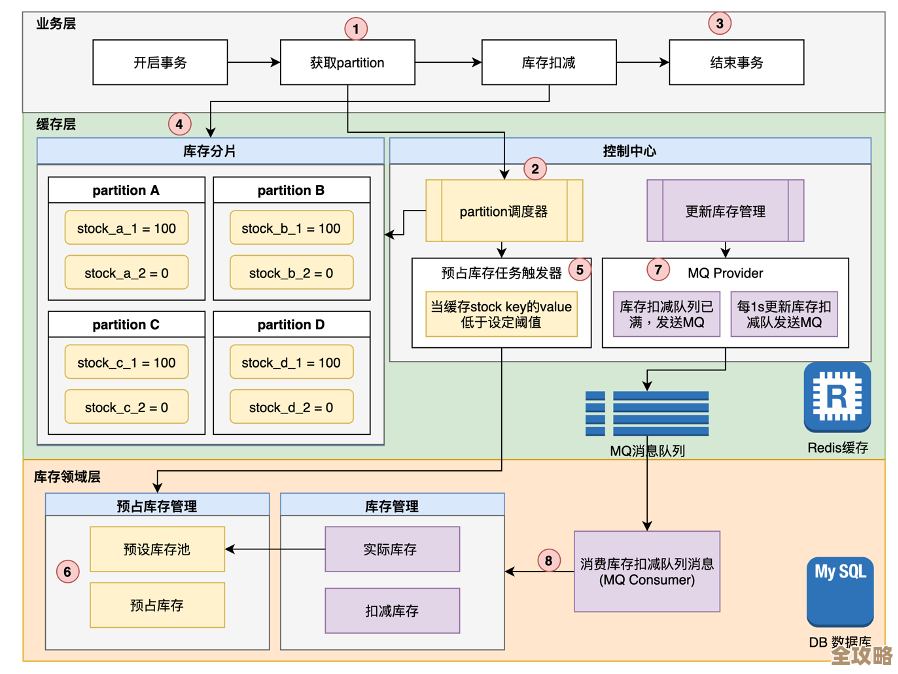
说说云原生里那些可观测性到底是怎么回事,感觉挺重要但又有点复杂

说到云原生里的可观测性,咱们可以把它想象成给一辆非常复杂的赛车装上一套超级仪表盘和黑匣子,以前开普通家用车(好比传统软件),速度表、油量表、水温表这些基本仪表(也就是监控)就够用了,车子哪里不对劲,比如水温过高,你看一眼仪表就知道大概问题出在哪儿。
但云原生应用不一样,它就像一辆由几百上千个小零件(微服务)组成的F1赛车,这些零件还在比赛过程中不断地自动更换、调整位置,这时候,你如果还用家用车的仪表盘,那就完全抓瞎了,你可能只知道赛车变慢了(系统变卡),但根本搞不清是哪个轮胎(服务)出了问题,是引擎(数据库)喘不上气,还是几个零件之间配合失误(服务调用失败),可观测性就是为这种极端复杂、动态变化的系统量身打造的“超级仪表盘”。
这个“超级仪表盘”主要看三样东西,业内通常称为三大支柱(来源:CNCF云原生定义中普遍接受的观念),你别被这词吓到,其实很好理解。
第一根支柱,叫做日志。 这个咱们最熟悉,就像飞机的黑匣子或者程序的“日记本”,系统里发生的每一个重要事件,比如用户登录了、下单失败了、某个计算完成了,都会用文字的形式记录下来,一条一条的,当出了问题,工程师就会去翻看这些日志,像侦探查案一样,看看在出错的那一刻前后,系统都“记”了些什么,但光有日志不够,因为云原生环境下服务太多了,日志量巨大,而且是分散的,你得有一个中央日志库把它们收集起来才能高效查询。
第二根支柱,叫做指标。 这个就像赛车的实时仪表,显示的是当前的速度、转速、压力等数字,在系统里,指标就是一系列可量化的数据点,比如CPU使用率、内存占用、网站每秒的访问次数、请求的平均响应时间等,指标的特点是它是数字,可以被持续不断地采集,然后做成图表,让你一眼就能看出系统的整体健康状况和性能趋势,比如你看到响应时间的图表突然出现一个高峰,就知道那个时间点肯定出了啥事,它帮你快速发现“是不是有问题”,但具体“为什么有问题”,还得靠其他支柱。
第三根支柱,叫做链路追踪。 这是云原生可观测性里最关键、也最能体现其价值的部分,咱们举个例子:你在APP上点了一个“下单”按钮,这个请求背后可能依次调用了“用户权限服务”、“商品库存服务”、“优惠券服务”、“支付服务”等几十个微服务,如果这个下单请求失败了,你怎么知道是链条中的哪一环掉了链子?链路追踪就是给这个最初的“下单”请求发一个唯一的“身份证”(Trace ID),这个ID会随着请求传递到后面每一个被调用的服务,这样,你就可以在监控界面上完整地看到这个请求的一生:它经过了哪些服务、在每个服务里待了多久、是成功还是失败,就像给一次快递包裹投递过程装了GPS,你能精确看到它在哪个分拣中心耽搁了,或者在哪位快递员手上丢失了,这直接解决了微服务架构下最头疼的“问题定位”难题。
为什么说它重要又感觉复杂呢?重要性在于,没有可观测性,在云原生这种如同森林般错综复杂的环境里,你基本上就是个“瞎子”,系统没事的时候一切安好,一出问题就是灾难性的,运维人员只能靠猜和盲人摸象,恢复时间会非常长,严重影响业务。复杂性在于,实现可观测性不是装一个软件就完事了,它首先是一种设计和开发阶段就要考虑进去的理念,要求程序在写代码的时候就要打好日志、暴露指标、支持链路追踪,它涉及一整套技术工具的选型、部署、整合和日常维护,比如用Elasticsearch、Logstash、Kibana(ELK)堆栈处理日志,用Prometheus收集指标,用Jaeger或Zipkin做链路追踪,或者直接用商业的集成平台,产生的海量数据本身也需要管理和分析,对团队的技术能力要求比较高。
云原生可观测性的核心,就是从传统监控那种“已知故障点”的被动检查,转变到“应对未知故障”的主动探索,你不再仅仅是预设一些报警规则(比如CPU超过80%就告警),而是当出现一个你从未预料到的古怪问题时,你手头有足够丰富的数据(日志、指标、链路)和强大的工具,能够像侦探一样快速回溯、排查和定位问题的根本原因,它不是什么神秘的东西,本质上就是一套更高级、更全面的“看病”手段,确保云上这个复杂生命体能够健康、透明地运行。

本文由盈壮于2026-01-21发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/84076.html