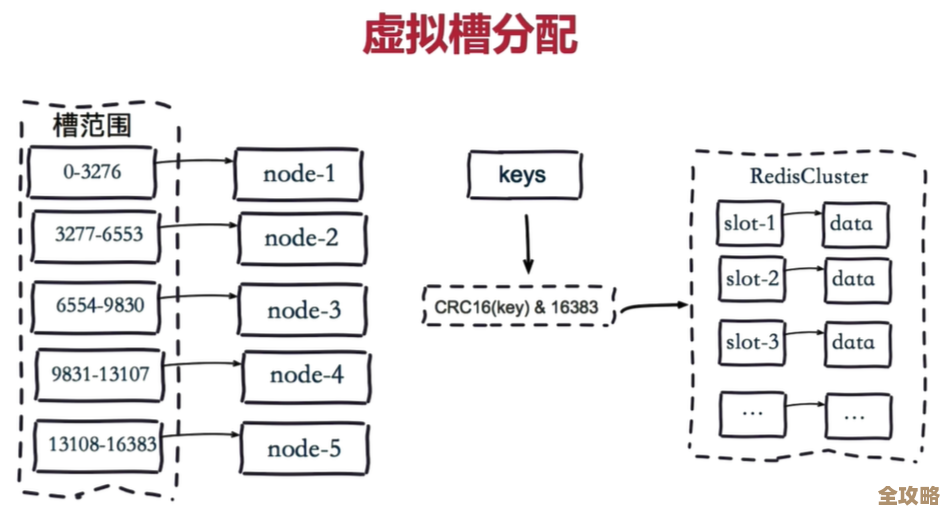
Redis里键会不会重复啊,重复了又会怎样,可能性到底有多大?

关于Redis里的键会不会重复,答案其实很简单:在同一个Redis数据库中,键是不会重复的。 你可以把Redis想象成一个巨大的、超级快的字典或者地图,这个字典里的每一个词条(也就是键)都必须是唯一的,当你尝试给一个已经存在的键设置新的值时,并不会产生一个新的、重复的键,而是会用新的值覆盖掉旧的值。
如果“重复”设置了键,会发生什么呢?
这里说的“重复”,其实就是覆盖更新,具体会发生什么,完全取决于你使用的命令和键原来对应的数据类型,我们来看看几种常见的情况:
-
最普通的情况:使用
SET命令 如果你对一个已经存在的键再次使用SET命令,比如这个键原来存的是你的网名“小明”,你再次执行SET username "小红",小明”这个值就会被永久地替换成“小红”,旧的数据会被丢弃,就像从来没存在过一样,这是最常见、最直接的覆盖操作。 -
当键的数据类型不匹配时:危险的覆盖 这是一种容易导致问题的情况,假设你之前用一个键
user:100存储了一个复杂的用户信息,使用的是哈希(Hash)数据类型,里面包含了姓名、年龄、邮箱等多个字段,你或者你的同事不小心对这个键执行了一个SET user:100 "张三"命令,这下就出问题了!原来那个结构化的哈希数据会被彻底摧毁,替换成一个简单的字符串值“张三”,之前的所有字段都丢失了,而且这个过程是不可逆的,等你后面的程序试图从这个键里读取年龄等字段时,就会报类型错误,因为现在它已经不是一个哈希表了,根据Redis官方文档(《Redis in Action》一书中也有类似强调),这种操作是允许的,但需要开发者自己来保证操作的正确性。
-
使用一些特殊的“SET”命令 Redis提供了一些更智能的SET命令,它们的行为有所不同:
SETNX(SET if Not eXists):这个命令是“如果不存在才设置”,它天生就是为了避免覆盖而设计的,只有当键不存在时,它才会设置值;如果键已经存在,它什么也不做,返回0表示设置失败,这常用于实现分布式锁等场景。MSET(Multiple SET):同时设置多个键值对,如果其中某个键已经存在,它也会毫不留情地进行覆盖。
除了覆盖,还有什么其他影响?
- 过期时间(TTL)会被清除:如果原来的键设置了过期时间(比如10分钟后自动删除),那么当你用
SET命令覆盖它时,这个过期时间也会被一并清除,键将变成永久有效的,除非你再次为它设置新的过期时间,这一点在Redis的官方命令文档中有明确说明。 - 内存变化:新值的大小如果比旧值大,Redis占用的内存会增加;如果新值更小,内存会被释放一部分。
键重复的可能性到底有多大?

从技术上讲,在Redis服务器正常运行且没有外部干扰的情况下,绝对不会出现两个完全相同的键同时存在的情况,Redis的核心机制保证了键的唯一性。
我们通常担心的“可能性”,其实指的是“意外覆盖”发生的概率,这个概率完全取决于人为因素和系统设计,而不是Redis本身,可能性的大小可以从以下几个方面来看:
- 开发人员的意识和规范:如果团队没有良好的键名命名规范(比如都用简单的
a,b,c来命名),或者对Redis的数据类型操作不熟悉,那么误操作的概率就会大大增加,这是最大的风险来源。 - 应用程序的逻辑错误:代码中的bug可能导致在不应该覆盖的地方执行了SET操作,在更新用户积分时,错误地使用了
SET而不是更安全的HINCRBY(对哈希字段进行增量操作)。 - 多个应用或服务操作同一个Redis:当多个独立的系统共享一个Redis实例时,如果它们之间没有协调好键的命名空间(比如没有用
app1:user:100和app2:user:100这样的前缀进行隔离),就极有可能发生键冲突和意外覆盖。 - 人为直接操作:运维人员或开发者通过命令行工具(如
redis-cli)直接操作生产环境的Redis时,一个手误就可能造成严重的数据覆盖。
如何降低“意外覆盖”的风险?
虽然Redis不会产生重复键,但我们可以通过一些最佳实践来保护数据不被意外覆盖:
- 使用清晰的命名空间:为键设计有意义的、带前缀的名字,用户数据用
user:{id},商品数据用product:{sku},会话数据用session:{token},这就像给不同的数据分了文件夹,大大降低了冲突的可能。 - 选择正确的命令:根据场景选择是否允许覆盖,如果不确定键是否存在又不想覆盖,优先使用
SETNX,更新哈希字段就用HSET,增加数值就用INCR或HINCRBY。 - 权限控制:在生产环境中,配置Redis的密码认证,并遵循最小权限原则,避免不必要的写权限。
- 隔离环境:严格将开发、测试、生产环境的Redis实例分开,避免误操作。
Redis本身通过键的唯一性设计保证了数据索引的准确性,我们完全不用担心它内部会自己产生重复键,真正的风险在于我们如何使用它,所谓的“键重复”问题,实质上是“数据被意外覆盖”的人为操作问题,通过良好的设计规范、谨慎的操作和充分的测试,完全可以将其发生的可能性降到最低。
本文由颜泰平于2026-01-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/84579.html