数据库主从同步那块儿到底咋监控才靠谱,别光说理论要实操点的办法

直接上干货,监控数据库主从同步,你就盯紧下面这几个实实在在的地方,自己动手查,比啥 fancy 的工具都管用。
第一,核心中的核心:看主从同步的关键状态。
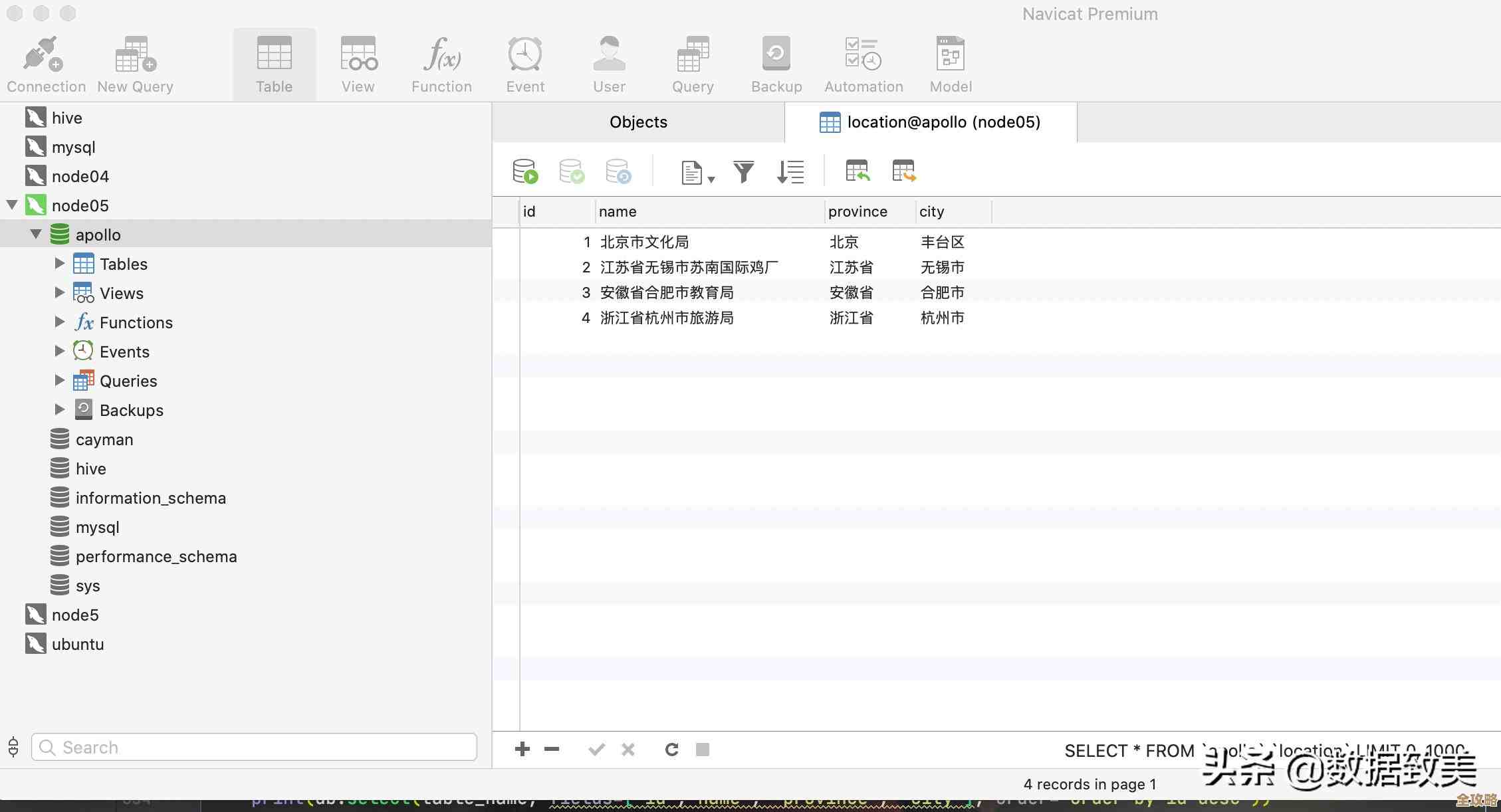
别管那么多,直接连上从库,执行那个最常用的命令:SHOW SLAVE STATUS\G,你就盯着这几个结果看,别的先不用管:
- Slave_IO_State: 这个告诉你从库现在在干嘛,最常见的就是“Waiting for master to send event”,这是好的,说明它正老实等着主库发数据过来,要是出现“Connecting to master”、“Reconnecting after a failed master event read”之类的,那就是网络或连接出问题了。
- Slave_IO_Running 和 Slave_SQL_Running: 这两个必须是 Yes,只要有一个是 No,同步就停了,如果停了,紧接着看后面的 Last_IO_Error 和 Last_SQL_Error 字段,里面会写明报错原因,比如连不上主库、或者执行某个SQL语句出错了。
- Seconds_Behind_Master: 这个就是复制延迟,单位是秒。这是最重要的监控指标之一,理想情况是0,如果这个数字慢慢变大,或者一直在一个大于0的值徘徊,说明从库“追”不上主库了,延迟几十秒可能还能接受,要是延迟到几百、几千秒,那从库的数据就太旧了,基本不可用,你需要设置告警,比如延迟超过30秒就发警告,超过300秒就报严重。
第二,别忘了检查主从的数据是否一致。 状态看起来都正常,不代表数据就一定一模一样,时间长了,可能会有一些数据差异,你需要定期做一致性检查,一个很实在的办法是,找个业务低峰期,比如半夜,对核心的表用校验工具(pt-table-checksum)跑一下,这个工具的原理是给数据算个“指纹”,在主库算一遍,在从库算一遍,然后对比“指纹”是否一样,如果不一样,就说明那块数据对不上了,你得想办法修复(比如用 pt-table-sync 工具),这个不用天天做,但每周或每两周做一次是稳妥的。

第三,监控数据库的错误日志和性能。
很多问题会先暴露在日志里,主库和从库的错误日志文件(MySQL 的 error log)你得定期扫一眼,用 tail -f 命令实时看着,或者用日志收集工具监控有没有出现复制相关的错误关键词。
从库本身也是一台数据库服务器,它的性能也会影响同步速度,你要监控从库的:
- CPU 使用率: 如果从库的CPU经常跑满,那它可能没足够资源来回放主库的SQL,就会导致延迟。
- 磁盘 I/O: 从库要写数据,如果磁盘速度太慢(比如用着烂硬盘),或者IO利用率持续100%,那它肯定快不起来,延迟就会增加。
- 网络流量: 主从之间的网络不能太差,监控主库发往从库的网络流量是否正常,有没有网络中断、丢包的情况。
第四,设置告警,别等出了事才发现。 把上面要检查的东西,都做成自动化的告警:

- 状态告警:
Slave_IO_Running或Slave_SQL_Running变成 No,立刻打电话发短信。 - 延迟告警:
Seconds_Behind_Master超过你设定的阈值(比如30秒),就发通知。 - 性能告警: 从库的CPU、磁盘IO长时间过高,也要告警,这是延迟的潜在原因。
实操步骤总结:
- 每天或每小时: 跑脚本或通过监控平台看一遍
SHOW SLAVE STATUS里那三个关键状态(两个Running和延迟)。 - 每周或每两周: 在业务低峰期,对核心表做一次数据一致性校验。
- 随时: 关注数据库错误日志的告警信息,监控从库服务器的CPU、磁盘IO指标。
- 出问题时: 首先查
SHOW SLAVE STATUS中的错误信息;其次查错误日志;最后检查从库服务器负载。
监控主从同步,“延迟”和“两个线程状态”是生命线,先保证这两样没问题,然后再通过定期校验和性能监控,去发现那些隐藏的、慢慢积累的问题,这样操作下来,你的主从同步监控就相当靠谱了。
(参考来源:Percona 数据库监控实践、MySQL 官方手册复制状态说明、常见运维监控场景经验总结)
本文由度秀梅于2026-01-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/85258.html