选数据库这事儿,怎么挑才能让CRM系统跑得顺畅又靠谱呢?

选数据库这事儿,怎么挑才能让CRM系统跑得顺畅又靠谱呢?这事儿不能光听销售忽悠,得从CRM自己个儿的“脾气秉性”说起,CRM系统说白了就是公司的客户关系大管家,它每天要处理的事儿可多了:从记录每个客户的姓名电话,到跟踪销售员每次拜访的聊天内容,再到分析哪些产品最受欢迎,最后还得给老板们生成一堆看得懂看不懂的报表,这些活儿,特点都不一样,对数据库的要求自然也不同。

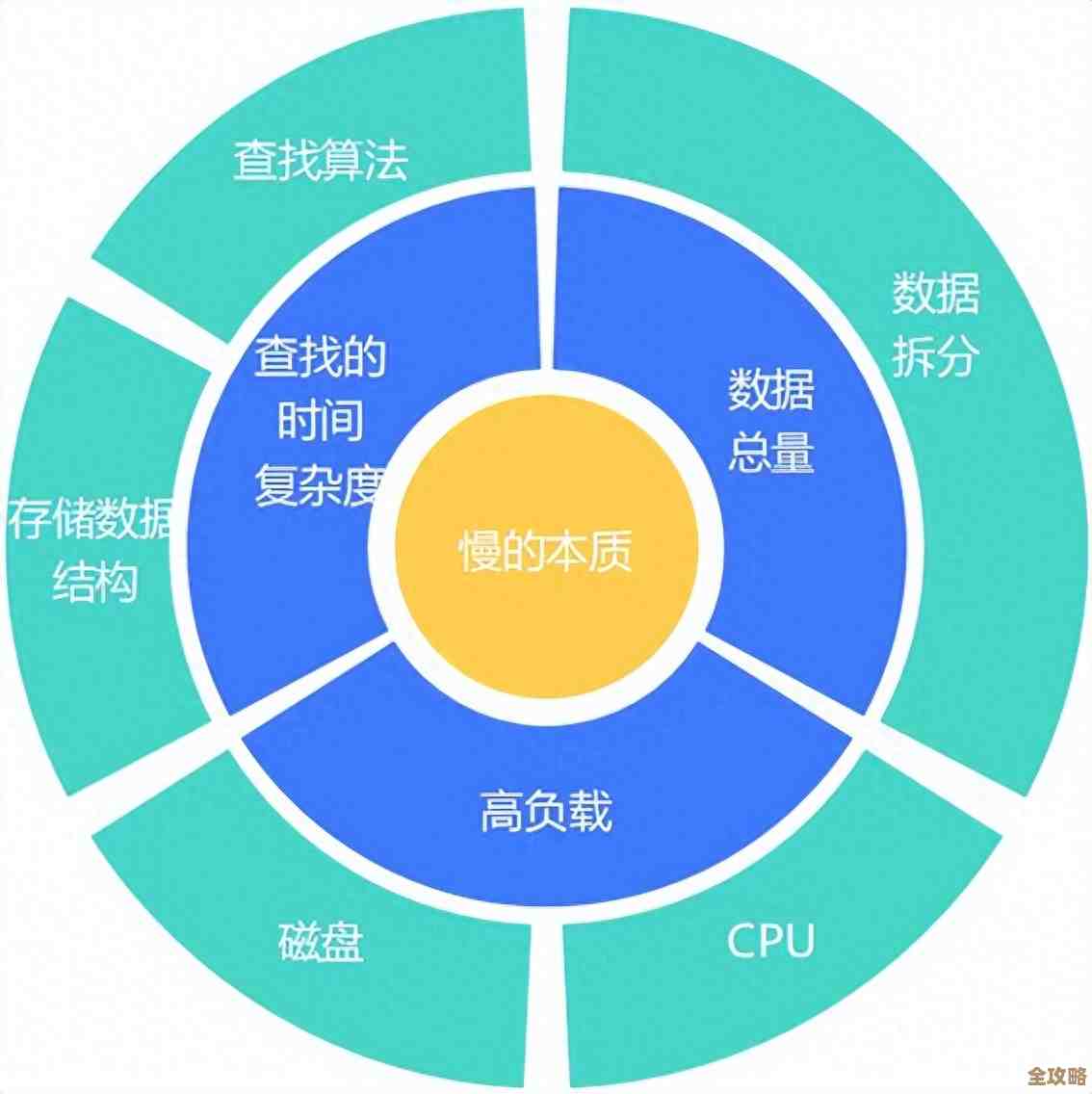
你得琢磨清楚,你的CRM系统最常干的是哪种活儿,是那种需要瞬间响应的?销售员在见客户前,唰一下要调出这个客户最近半年的所有联系记录和购买历史,这种操作,要求数据库的“读”速度必须快,延迟必须低,这时候,一些关系型数据库,比如经过优化配置的MySQL或者PostgreSQL,往往能表现出色,因为它们擅长处理这种结构清晰、需要快速查询的交易。(参考常见企业级应用数据库选型思路)
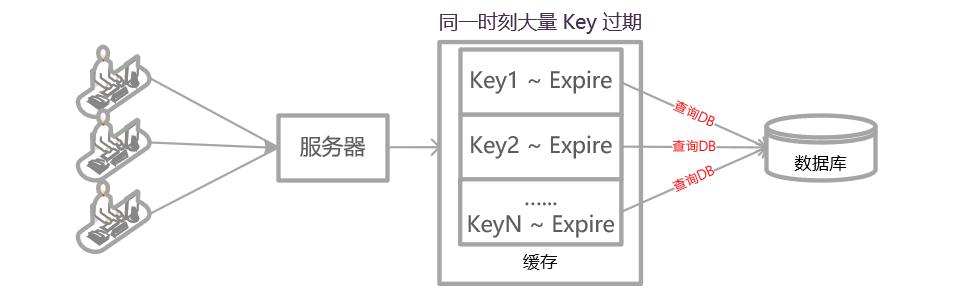
但CRM不光是查得快就行,当市场部做活动,一瞬间有几万人同时访问网站留下联系方式,或者销售团队集体将一批新的潜在客户录入系统时,数据库的“写”能力就面临巨大考验,它得像一个高效的海关,能同时开放多个通道,快速处理汹涌而入的数据,还不能出错、不能堵车,这种情况下,一些在设计之初就特别注重高并发写入能力的数据库,比如某些NoSQL数据库或者新一代的分布式数据库,可能会更合适,因为它们能更好地把写入压力分散到不同的服务器上。(考虑高并发场景下的数据库表现)

然后就是数据量的问题,初创公司可能觉得存几十万条客户记录就顶天了,但对于一家大型企业,客户数据、互动记录、交易流水可能随随便便就奔着百亿、千亿条去了,这时候,数据库能不能“撑得住”就成了关键,传统单机数据库可能很快就遇到瓶颈,而具备横向扩展能力的数据库就成了必选项,所谓横向扩展,就是数据太多一台机器存不下、算不动的时候,可以简单地增加几台便宜的普通服务器,组成一个集群来共同分担,像搭积木一样,这样,未来业务量再增长,你也不用担心数据库会成绊脚石。(引自大规模数据存储与处理的架构原则)
光快、能装还不行,还得“准”,CRM里的客户信息、订单金额,那可都是真金白银,绝对不能出错,销售A刚给客户张三打了折,把订单总价从10000元改成了9500元,紧接着财务B查看这张订单时,必须看到的是9500元,而不能是修改前的10000元,这就叫数据的一致性,关系型数据库在这方面有严格保障(ACID特性),能确保数据准确无误,但有些时候,为了换取更高的处理速度或可用性,某些新型数据库可能会在一致性上做一些妥协(最终一致性),你得想清楚,你的业务是否能接受这种短暂的延迟,对于CRM核心的财务、客户主数据,通常强一致性是底线。(基于数据一致性在关键业务中的重要性)
还有一个不能忽视的点是“灵活性”,传统的CRM可能字段都是固定的,姓名、电话、公司,但现在做个性化营销,你可能想记录客户“喜欢红色”、“养猫”、“对价格敏感”等各种标签,这些信息不规则,今天想加一个字段,明天又想减少一个,如果数据库结构太死板,每次改动都得大动干戈,那业务创新就太受限制了,一些文档型或列式NoSQL数据库在 schema 灵活性上就有优势,允许你更自由地增减字段,适应业务的快速变化。(适应现代CRM动态数据模型的需求)
还得看看“家底”和“人手”,数据库不是买来就完事了,它需要安装、配置、优化、备份、监控,这是个技术活儿,像Oracle、SQL Server这些商业数据库,功能强大稳定,但软件许可费用昂贵,对运维人员的要求也高,而MySQL、PostgreSQL这类开源数据库,零软件成本,社区活跃,但需要公司自己有较强的技术团队去驾驭,现在很多云服务商提供的数据库服务(如AWS Aurora、阿里云PolarDB等)是个折中的好选择,它把很多复杂的管理工作都接管了,让你更专注于业务,按用量付费,对于很多企业来说性价比更高。(综合成本与运维复杂度的现实考量)
挑数据库没有唯一的标准答案,它是个权衡的艺术,你得像老中医看病一样,先给自己的CRM业务“望闻问切”:是读多写少还是写多读少?数据量增长有多快?对数据准确性要求多高?业务变化频率如何?团队的技术能力和预算怎样?把这些问题的答案捋清楚了,再去看各种数据库的“特长”,才能找到那个能让你的CRM系统既跑得顺畅又长期靠谱的“最佳搭档”。

本文由寇乐童于2025-12-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/67687.html