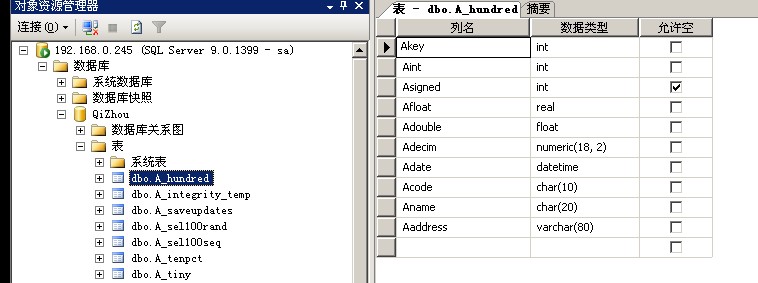
红色赛道里Redis面试被刷,感觉redis淘汰真心不简单啊

(来源:知乎匿名用户分享)“红色赛道里Redis面试被刷,感觉redis淘汰真心不简单啊”这个帖子,其实是一位程序员在面试后发出的感慨,他自认为对Redis挺熟的,常规命令、数据结构啥的都能答上来,没想到最后挂在了一个他觉得“应该不难”的问题上——Redis的内存淘汰策略,这一挂,让他回去仔细一琢磨,才发现这里面门道深得很,根本不是背几个策略名字就能应付过去的。

(来源:帖子原文描述)据他回忆,面试官当时没直接问“Redis有哪几种内存淘汰策略?”这种八股文问题,而是抛出了一个非常具体的场景:“假设我们有一个用Redis做缓存的热门活动页面,访问量巨大,内存很快就要满了,这时候你设置了maxmemory-policy为allkeys-lru,但上线后运维反馈,明明看起来内存还没完全占满,却偶尔会有一些明明还在被频繁访问的Key被莫名其妙地淘汰掉,导致大量请求穿透到数据库,差点引发雪崩,你觉得可能是什么原因造成的?”

这位老哥当时就有点懵,他心想,LRU(最近最少使用)不是挺经典的吗?按照最近访问时间淘汰最久没用的数据,咋会淘汰掉热点数据呢?他支支吾吾地答了一些可能的原因,比如是不是LRU算法实现有bug,或者是不是网络延迟导致的时间戳不准之类的,结果显然没让面试官满意。

(来源:用户事后学习总结)面试失败后,他憋着一股劲去查资料、看源码,才恍然大悟自己错得有多离谱,原来,Redis的LRU算法并不是一个严格的、精确的LRU实现,为了节省内存、提升性能,Redis采用了一种近似LRU的算法,它并不会为每个Key都维护一个精确的最后访问时间戳,那样内存开销太大了,相反,Redis会随机抽取一批Key(默认是5个,可通过maxmemory-samples配置),然后从这批Key中淘汰掉那个距离上次访问时间最久的。
(来源:Redis官方文档及技术博客解读)问题就出在这个“随机抽样”上,想象一下,当内存压力很大时,Redis就像在一个装满小球的池子里随机抓一把,然后扔掉里面最旧的那个,如果运气不好,某一轮抓取恰好抓到了几个热点Key和几个更冷的Key,那淘汰掉一个相对较热但在这批样本里“最老”的Key,是完全有可能的!虽然概率不高,但在海量请求下,这种小概率事件就成了必然,这就解释了为什么会出现“热点数据被误杀”的灵异事件。
(来源:用户拓展思考)他这才明白,面试官的问题精髓不在于让他背策略,而是考察他是否了解Redis在性能和精确度之间做的权衡,是否意识到这些策略在极端场景下的潜在风险和局限性,更进一步,这个问题其实是在引导他思考解决方案。
- 调整采样数量:增加
maxmemory-samples的值,比如提高到10,这样抽样的代表性更强,淘汰结果更接近真正的LRU,但会稍微增加CPU开销。 - 换用其他策略:比如
allkeys-lfu(最不经常使用),这个是Redis 4.0之后加入的,基于访问频率淘汰,可能更适合那种需要保护热点数据的场景,但LFU也有它的实现机制和需要注意的地方。 - 架构设计上兜底:不能过度依赖缓存淘汰策略的“智能”,核心热点数据是否可以考虑设置永不过期(在内存足够且数据需要常驻的前提下),或者做好缓存穿透、雪崩的保护措施,比如布隆过滤器、限流降级等。
(来源:用户最终感悟)经过这番折腾,这位发帖人感慨道,以前学Redis,觉得会背noeviction、allkeys-lru、volatile-lru、allkeys-random、volatile-random、volatile-ttl这几种策略的名字和含义就差不多了,真到面试和实战中才发现,水太深了,一个看似简单的“淘汰”背后,涉及到算法原理、实现细节、性能权衡、适用场景等一系列知识,Redis的淘汰机制真心不简单,它不是一个黑盒,而是一个需要开发者深刻理解其工作原理和限制的工具,否则在高压力的生产环境中,就可能埋下意想不到的故障隐患,这次面试虽然挂了,但他觉得值了,因为这逼着他把一个知识点彻底挖透了。
本文由黎家于2025-12-26发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/68740.html