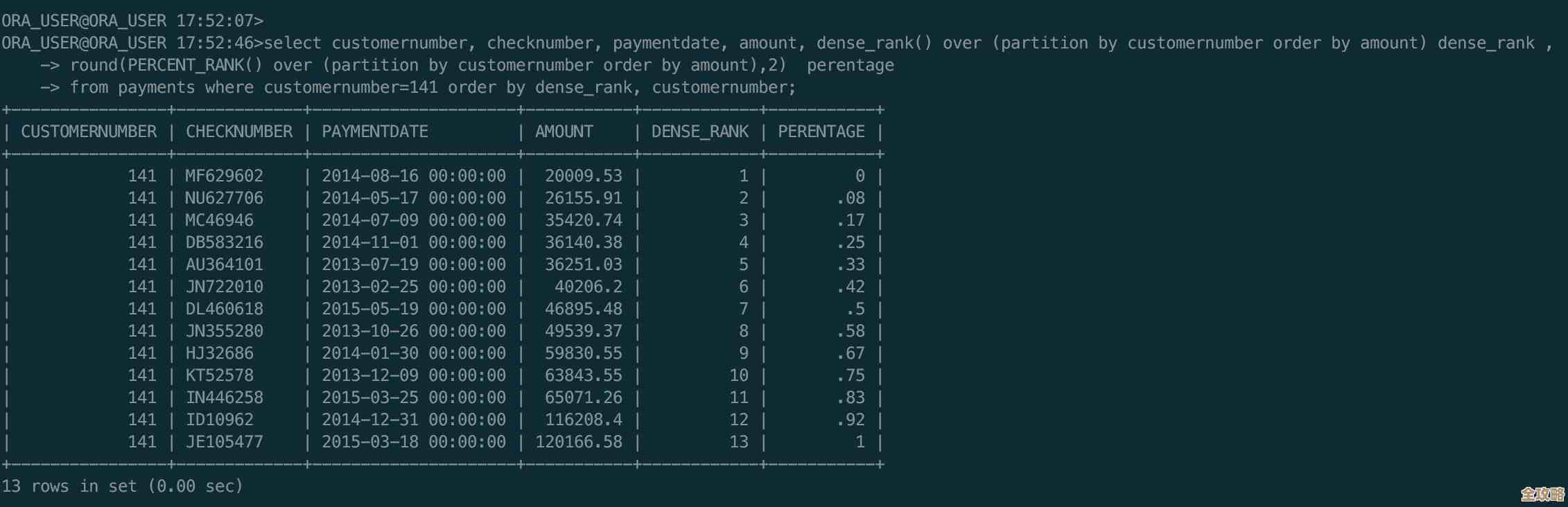
说实话,做 Kubernetes Operator 其实没那么简单,有些原则你得先摸清楚才能少走弯路

说实话,做 Kubernetes Operator 其实没那么简单,有些原则你得先摸清楚才能少走弯路,这话不是我说的,是很多在实际项目中摸爬滚打过的工程师们(在 Red Hat 的工程师们在博客和社区讨论中多次强调)的血泪总结,你可能看过很多文章,把 Operator 说得天花乱坠,好像只要用了 Operator,就能自动化一切,一劳永逸,但真正上手之后,你会发现坑是一个接一个,想少踩点坑,下面这几个原则,你最好在动手前就先琢磨透。
第一,先问“是不是真的需要 Operator”,别为了用而用。 这是最最重要的一条原则,Operator 本质上是一个针对特定应用的、复杂的自动化控制器,它管理的是有状态的应用,而且这个应用本身的管理逻辑就得足够复杂,一个简单的无状态 Web 服务,用个 Deployment 加个 Service 就能搞定,它的扩容、重启都很直接,你硬要给它写个 Operator,那绝对是杀鸡用牛刀,凭空增加了开发和维护的复杂度,那什么时候才真的需要呢?比如你要管理一个数据库(像 PostgreSQL、Redis)、一个消息队列(像 Kafka),或者任何一个需要“领域知识”才能操作的应用,这些“领域知识”指的是:怎么安全地备份和恢复?怎么做版本升级而不丢数据?怎么在节点故障时自动故障转移?如果你的应用不需要处理这类复杂的、手动的、需要专业知识的过程,那你可能只需要一个 Helm Chart 或者一堆 YAML 文件就够了,工程师社区里常说的一个观点是:“如果你的操作手册只有一页纸,那你可能不需要 Operator。”
第二,你的 Operator 要“低调”且“仁慈”,别把自己当主角。 这是什么意思呢?你的 Operator 是去帮助用户管理应用的,而不是去抢走用户对集群的控制权,一个好的 Operator 应该遵循 Kubernetes 的设计哲学,尤其是“声明式 API”和“控制器模式”,用户通过 YAML 文件声明他期望的应用状态(3个副本,版本是 2.1),Operator 的责任是默默地、不断地观察当前状态,并努力将当前状态向期望状态调整,它不应该去阻塞用户的正常操作,用户能不能直接用 kubectl edit 去修改 Operator 创建出来的 Pod 的镜像?在理想情况下,应该是可以的,虽然 Operator 下次调和循环时可能会根据 CRD(自定义资源定义)里的规范把镜像改回去,但至少给了用户一个紧急干预的窗口,如果你的 Operator 设计得过于“霸道”,到处加拦截(Webhook),让用户感觉寸步难行,那这个 Operator 的体验就会非常差,Operator 是用户的助手,不是用户的老板。

第三,把“人”放在心上,日志和事件要说得清楚明白。 Operator 是在自动化复杂的操作,但再好的自动化也可能出问题,当问题发生时,运维人员(可能是你,也可能是你的同事)需要能快速搞清楚“现在到底发生了什么?”、“卡在哪一步了?”,这时候,Operator 的日志和它向 Kubernetes 事件中心发送的事件就至关重要,你不能只在日志里打一行“Error occurred”(发生错误)就完了,你得说清楚:是在处理哪个用户的哪个自定义资源时出的错?是在执行哪个操作步骤(“正在创建第3个Pod”)时失败的?失败的具体原因是什么(“无法从镜像仓库拉取镜像 xyz:1.0,权限认证失败”)?Kubernetes 自身的基础控制器(如 Deployment)在这方面做了很好的示范,你可以多看看它们的日志和事件格式,清晰的日志和事件能极大降低运维的难度,这也是一个成熟 Operator 的标志。
第四,状态,状态,还是状态!管理好应用的状态是你的核心任务。 既然 Operator 是用来管理有状态应用的,那么它就必须能精确地理解和记录应用本身的状态,这不仅仅是 Pod 是 Running 还是 Pending,对于数据库,状态可能包括:主从角色、数据同步进度、备份任务是否完成等,你的 CRD(自定义资源定义)设计里,一定要有一个 status 字段,用来清晰地反映这些丰富的、属于你应用的领域状态,Operator 的逻辑要能够根据 status 来判断下一步该做什么,只有当 status.currentPhase 是 BackupCompleted(备份完成)时,才能开始执行版本升级操作,如果你把所有这些状态都只放在程序的内存变量里,一旦 Operator 容器重启,就全忘了,可能会做出错误的决策,导致灾难性后果,把关键状态持久化到 CRD 的 status 子资源中,是必须的。

第五,循序渐进,别想着一口吃成胖子。 开发 Operator 是一个迭代的过程,不要一开始就试图实现所有高级功能,比如复杂的滚动升级、自动缩容等,你应该先从最核心的生命周期管理开始:能不能成功部署一个单实例的应用?然后再加上扩容功能,再然后,实现备份功能,一步一步来,每完成一步都进行充分的测试,社区里有很多工具包(如 Kubebuilder、Operator SDK)能帮你搭建框架,但它们只是帮你省了脚手架的工作,核心的业务逻辑(也就是你对被管理应用的“领域知识”)还是得靠你自己一点一点编码实现和测试,先做一个能解决最痛点功能的“最小可行产品”(MVP),再慢慢完善,这样既能快速验证想法,也不容易在复杂的代码中迷失方向。
第六,测试,测试,再测试!你的 Operator 是“运维代码”。 普通的应用代码有 Bug,可能只是某个 API 接口报错,Operator 要是有 Bug,很可能把你管理的所有数据库实例都删了,或者导致大面积服务中断,对 Operator 的测试要求必须非常高,这包括:单元测试(测试你控制器的核心逻辑)、集成测试(在真实的 KinD 或 Minikube 集群里,测试整个部署和操作流程),以及最关键的——混沌工程测试(模拟节点宕机、网络分区等故障,看你的 Operator 能否按预期恢复),这部分工作非常耗时,但绝对不能省,没有经过充分测试的 Operator,就像一颗埋在生产环境里的定时炸弹。
做 Kubernetes Operator 是一个既有挑战又有成就感的事情,它要求你不仅懂 Kubernetes,更要懂你要管理的那个应用,在开始编码之前,多花点时间思考清楚以上这些原则,能让你避开很多常见的陷阱,真正做出一个稳定、可靠、对用户友好的自动化运维工具,而不是一个制造麻烦的“麻烦制造者”。
本文由邝冷亦于2025-12-29发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/70751.html