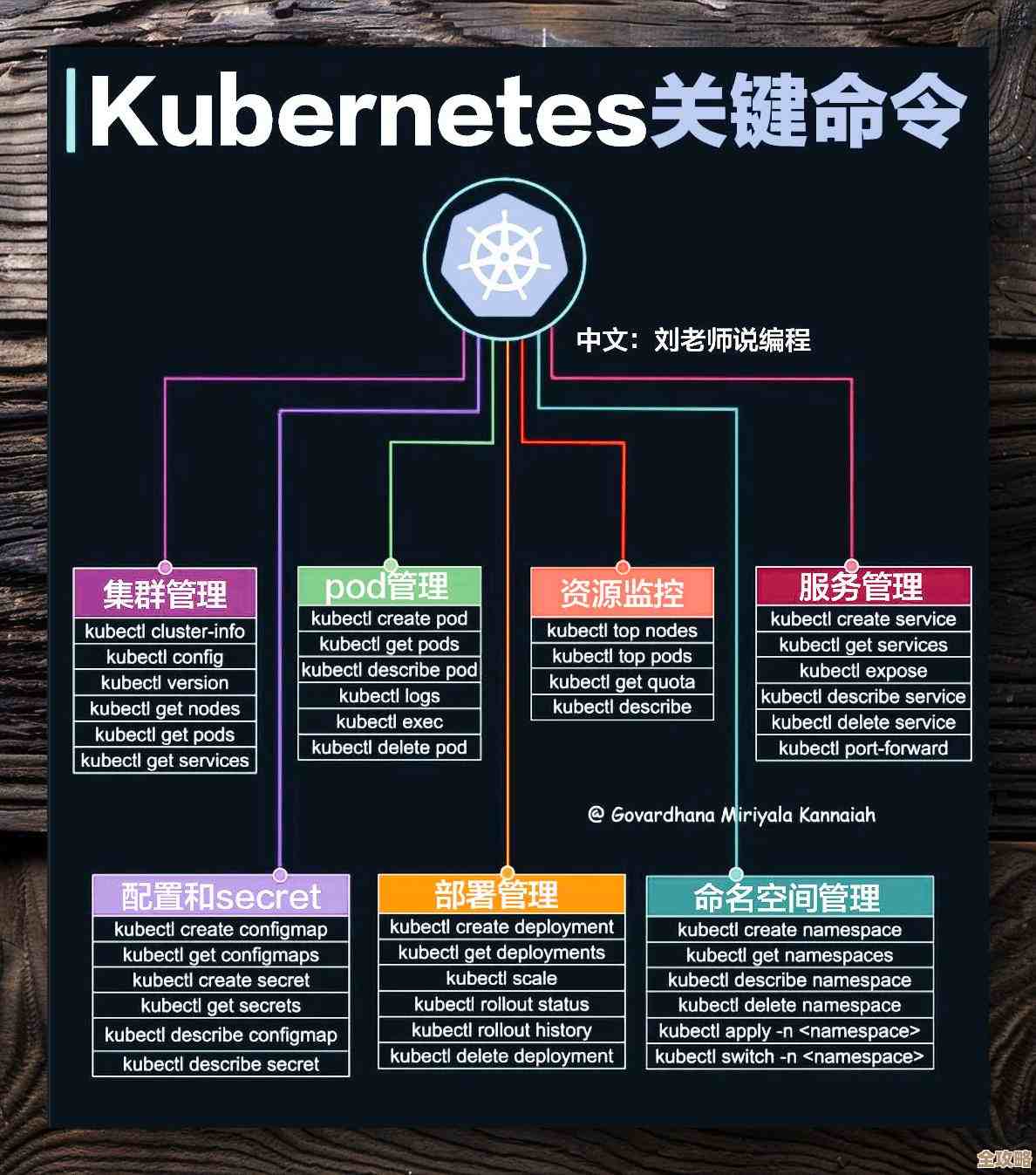
图数据库那些事儿,关系复杂查询咋优化还得再琢磨琢磨

根据网络技术论坛、开发者社区中关于图数据库应用与优化的常见讨论和案例分析综合整理)
图数据库那些事儿,关系复杂查询咋优化还得再琢磨琢磨
说起图数据库,很多人可能觉得这是个挺高大上的玩意儿,离日常开发挺远,其实吧,它的核心思想特别直白,就是专门用来处理“关系”的,你想啊,咱们现实世界里,啥事不是靠关系连起来的?社交网络里谁是谁的朋友,电商系统里谁买了什么又看了什么,金融风控里一笔钱经过多少人转手,这些场景里,关系才是主角,数据本身反而成了配角,传统的关系型数据库,像MySQL那种,查这类问题特别费劲,经常要搞一堆表连接(JOIN),数据量一大,查询速度就慢得让人心焦,图数据库就是来解决这个痛点的,它把关系提升为一等公民,用节点和边来直接表示实体和联系,查起来就像在图上“走迷宫”,路径特别清晰。
但是啊,别以为用了图数据库就一劳永逸了,特别是当数据量真的冲上来,业务逻辑变得盘根错节的时候,你会发现,原来“复杂查询咋优化”这个问题,在图数据库里同样存在,甚至更需要琢磨,这可不是简单换个数据库就能解决的。
首先一个头疼的问题就是“深度查询”,比如你想在一个社交网络里,查“朋友的朋友的朋友”里,有多少人和你有着共同的兴趣爱好,这个查询要往图里走三层,甚至更深,如果一开始没设计好,这种查询可能会变成一个“爆炸式”的遍历,因为它每走一步,都可能遇到成百上千个新节点,计算量指数级增长,数据库一下就扛不住了。(来源:多位图数据库使用者在社区分享的深度遍历性能瓶颈案例)
那咋办呢?就得琢磨优化策略,其中一个常见的法子叫“查询下推”,意思是,别傻乎乎地把所有数据都捞到应用程序的内存里再筛选,要尽量让数据库本身在遍历的时候就把能干的活儿干了,在找“朋友的朋友”时,可以一边走一边就过滤掉那些不符合条件的节点(比如年龄不在某个区间的),这样后续要遍历的分支就少多了,这就像你找人,不是把整栋楼的人都叫出来排队,而是直接去目标楼层敲门,效率自然高,不过这个说起来简单,写查询语句的时候怎么把过滤条件巧妙地放对位置,就得靠经验和测试了。
第二个琢磨点在于“索引”,图数据库也有索引,但和关系数据库的索引不太一样,它通常不是给表的列建的,而是给节点的“标签”(Label)和“属性”(Property)建的,你给“用户”这个标签下的“城市”属性建个索引,那么当你查询“所有在北京的用户”时,就能飞快地定位到这批节点,而不用扫描全图,但如果你的查询条件总是变,或者涉及多个属性的组合,索引该怎么建才能最优,就是个技术活了,建多了影响写入速度,建少了查询慢,这个平衡点得反复调整。(来源:图数据库官方文档中关于索引策略的说明及社区最佳实践讨论)
第三个特别需要琢磨的地方是“数据模型设计”,这可以说是最根本的优化,图怎么建,直接决定了以后查询顺不顺畅,举个例子,你是把“购买”这个行为直接做成一条边,还是把它拆成一个独立的“订单”节点,两边再连上用户和商品?这两种设计,对于“查询所有买了A商品又买了B商品的用户”这样的问题,效率可能天差地别,前者可能需要遍历所有买过A的用户,再逐个检查他们是否买了B;而后者可能通过“订单”节点有更短的路径,这就好比修路,你是修一条绕远的直路,还是修一个规划得当的立交桥,效果完全不同,很多时候查询慢,回头一看,是当初图结构设计得有点“别扭”。(来源:资深架构师在技术分享中反复强调的图数据模型设计重要性)
还有啊,现在很多图数据库都支持“图计算”,比如寻找最短路径、发现社区、计算中心度等,这些算法本身也很耗资源,优化它们,有时候需要用到“采样”技术,也就是不从全图计算,而是取一部分有代表性的数据来算个大概,用精度换速度,在不少风控或者推荐场景下,一个快速的大致结果,比一个精确但需要等十分钟的结果更有价值。
所以说,图数据库是个好东西,但它不是一颗银弹,把它引进来,只是第一步,真正让它发挥威力,还得在“优化”上下足功夫,从查询语句的写法,到索引的创建策略,再到最核心的数据模型设计,每一个环节都有很多值得琢磨的细节,这玩意儿有点像功夫,入门容易,但要练成高手,就得不断思考、实践、调优,面对越来越复杂的关系和数据,咱们开发者还真得继续琢磨琢磨。

本文由颜泰平于2025-12-30发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/71423.html