Redis应付高流量其实没那么难,关键是这些技巧你得知道

说到Redis应对高流量,很多人可能觉得这是个特别复杂、需要高深技术的话题,但其实它的核心思想非常直接,你不需要一开始就钻研那些最顶尖的架构,只要把一些基础但关键的技巧用好了,就能解决大部分的高流量问题,下面这些技巧,都是实践中总结出来的干货,理解了它们,你就掌握了Redis高并发的钥匙。
第一,别让Redis干重活,让它做它最擅长的事。 这个道理来自一位资深架构师的分享,Redis是单线程模型的,这意味着它处理命令的速度极快,但它不喜欢等待,如果你把一个非常复杂的计算,比如需要循环几千次才能得出结果的操作,通过Lua脚本塞给Redis去执行,那么在这段时间里,Redis就无法处理其他任何请求,所有客户端都得等着,这就好比高速公路的收费站只有一个窗口,偏偏前面有辆车在慢吞吞地找零钱,后面的车全堵死了,正确的做法是,把复杂的计算逻辑放在应用程序里完成,Redis只负责最纯粹的读写和简单的数据操作,让它保持“快”的本色。
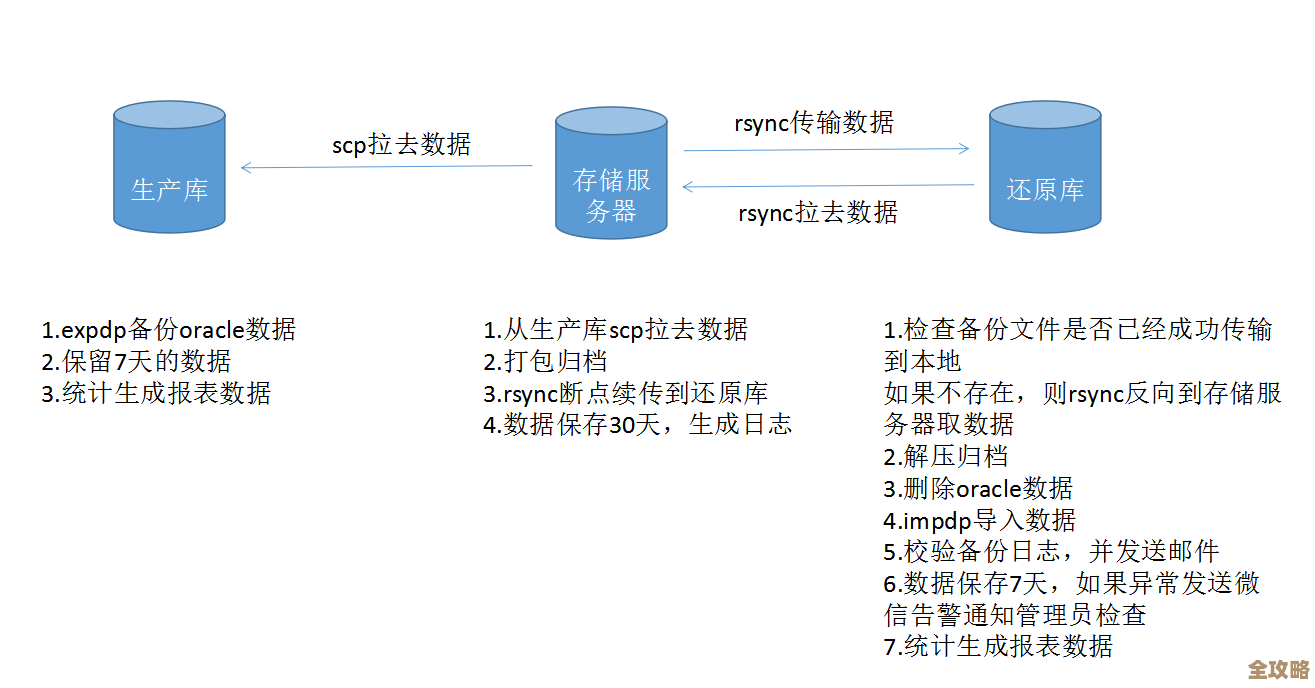
第二,给热点数据找个“前台”,这就是缓存。 这是几乎所有大型互联网应用的标配技巧,你的数据库(比如MySQL)处理能力有限,当每秒有几万甚至几十万次请求直接砸向数据库去查询同一件热门商品的信息时,数据库肯定扛不住,会直接崩溃,解决办法就是使用Redis作为缓存层,具体操作是:应用程序在查询数据库之前,先到Redis里问问有没有这个数据,如果有(这叫做“缓存命中”),就直接从Redis里取,速度飞快,完全不用麻烦数据库,如果没有(这叫做“缓存穿透”),再去数据库查,然后把查到的结果写一份到Redis里,这样下次再来查询就能命中了,这就好比银行里办理业务,常见的问题直接由大堂经理(Redis)快速解答,只有复杂业务才需要去柜台(数据库)排队,大大减轻了柜台的压力。

第三,设置合理的过期时间,别让缓存“永远活着”。 这个技巧是从缓存设计原则中来的,如果你把数据放进Redis后就不管了,永远不删除,那么一旦这个数据在数据库里被更新了(比如商品价格变了),用户从Redis读到的就还是旧数据,这就出现了数据不一致的问题,一定要给缓存数据设置一个过期时间(TTL),比如设置10分钟或者1小时过期,这样,即使数据有轻微延迟,也能在一定时间后自动更新,这就像超市里的牛奶会标上保质期,过了保质期就下架换新的,保证了顾客总能买到新鲜的产品。
第四,警惕缓存穿透和缓存雪崩,这是两个常见的“坑”。 这两个概念在技术社区被讨论得非常多,缓存穿透指的是查询一个根本不存在的数据,比如查询一个不存在的商品ID,由于这个数据在数据库里也没有,所以应用程序每次都会去查数据库,Redis起不到任何保护作用,大量的这种请求同样会压垮数据库,解决办法很简单:如果发现数据库里也没有这个数据,就在Redis里也存一个空值(同样设置一个短的过期时间),这样下次再有同样的请求,Redis就能直接返回空值,而不用再去查数据库了。

缓存雪崩则更危险,它指的是在某一时刻,大量的缓存数据同时过期失效,这会导致所有的请求瞬间都涌向数据库,数据库承受不住瞬间的峰值压力而宕机,解决办法是避免给大量数据设置相同的过期时间,可以在设置过期时间时,增加一个随机值,比如基础过期时间是30分钟,然后再加上一个0到5分钟的随机数,这样就能让缓存失效的时间点分散开,不会在同一时刻发生,从而保护数据库。
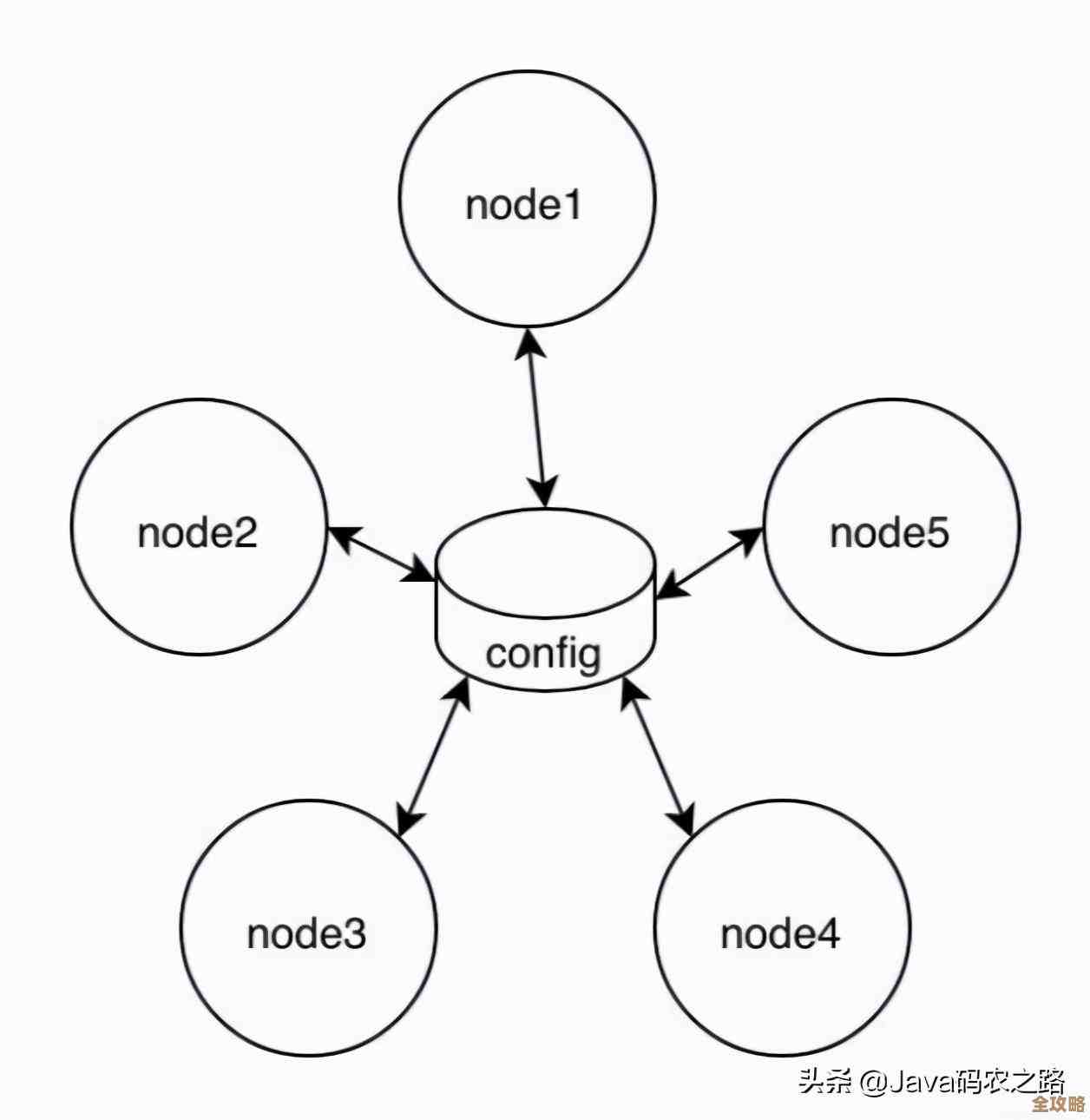
第五,当一台Redis不够用时,考虑把数据分开存放,也就是分片。 这是水平扩展的常见思路,因为单台Redis服务器的内存和性能是有上限的,当你的数据量非常大,或者读写请求高到一台机器处理不过来时,你就需要把数据拆分到多台Redis服务器上,可以按照一定的规则来分,比如根据用户的ID,把ID以1开头的用户数据存到第一台Redis,以2开头的存到第二台,以此类推,这样,每台Redis只负责一部分数据和请求,整体的处理能力就成倍增加了,这就像一个仓库放不下所有货物了,那就多建几个仓库,把不同类型的货物分门别类地存放和管理。
用好Redis应对高流量,核心在于理解它的特性,并围绕这些特性来设计你的使用方案,别让它做复杂运算、用好缓存机制、设置合理的过期策略、防范穿透和雪崩风险、在必要时进行分片扩展,把这些看似简单的技巧真正落到实处,你的系统就能从容应对大多数高流量场景了。
本文由颜泰平于2025-12-30发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/71474.html