数据库系统概念里那些源码细节,想搞懂得一点点慢慢扒才能明白

说到《数据库系统概念》这本书,它就像一本武功秘籍的总纲,告诉你数据库应该有哪些部件,这些部件大概是怎么配合的,但真要把数据库做出来,或者说真想弄懂它到底是怎么跑起来的,就得去读那些真正的“武功招式”——也就是像SQLite、PostgreSQL或者MySQL的源码,书里可能用一两页讲完“事务的原子性和持久性”,但源码里为了做到这两点,藏着无数让人头秃的细节。
举个例子,书里说事务要保证原子性,也就是一个事务里的操作要么全做,要么全不做,源码是怎么实现这个“要么全做,要么全不做”的呢?一个非常核心的机制是预写式日志(WAL),书里会提WAL这个词,但源码里的细节才叫精彩,比如在SQLite的源码里(我们以它为例,因为它比较轻量),当你执行一个修改数据的SQL语句时,数据库并不会直接去把数据页写到磁盘上的数据库文件里,那样做太危险了,万一写到一半断电,数据库文件就毁了,原子性根本没法保证。

源码的做法是,它先把要做什么事,像写日记一样,一条一条地记录在一个单独的日志文件里,这个“日记”的写法极其讲究,它不仅仅记录“把表A的第5行name字段改成‘张三’”,它还要记录很多额外的信息,比如事务ID、日志的校验和、以及一个非常重要的标记——提交记录,关键细节在于:只有在包含“事务提交”这条记录本身,以及它之前的所有日志记录,都被安全地、强制地刷到磁盘之后,这个事务才算真正提交成功,这个“强制刷盘”的操作,调用的可能是操作系统底层的fsync之类的函数,确保不是写在操作系统的缓存里就完事了,这个过程就像是,你要做一个多步骤的承诺,你必须把“我承诺做A、B、C三步,承诺人:我,日期:这整句话都白纸黑字写完,并且用力把墨水摁透到纸背,确保字迹不会消失,然后这个承诺才算数,如果在写这句话的过程中笔没水了或者纸破了,那这张作废的纸会被扔掉,就像这个不完整的事务从未发生过一样,这就是源码实现原子性的一个核心细节,它把“全做或全不做”这个抽象概念,转化为了“日志记录是否完整写入”这个非常具体、可检查的操作。
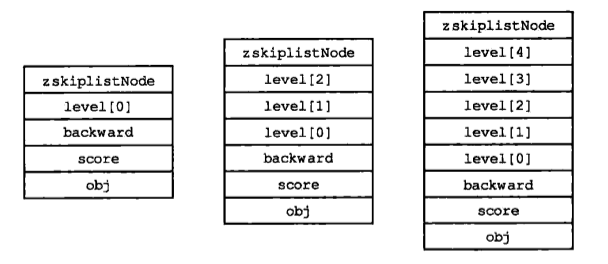
再比如,书里会讲索引,特别是B+树,书上的图画得很漂亮,节点分裂、合并的算法也讲得很清楚,但一读源码,你会发现一大堆书上不会提的、让人头疼的“琐事”,比如并发控制,想象一下,你正按照书上的算法,优雅地分裂一个B+树节点,突然另一个查询线程也要来读这个节点,会发生什么?如果没有任何保护,查询线程可能会读到一半是旧数据、一半是新数据的“分裂中”的混乱节点,结果肯定是错的。

所以在源码里,B+树的实现绝不是书上那个单纯的算法描述,它浑身都挂满了锁,可能是在访问某个节点前,先获得这个节点的读锁或写锁,分裂操作可能需要先锁住父节点,再锁住要分裂的节点,操作完成后再按顺序释放,这些锁的粒度(是锁整个树,还是锁一个页面,还是锁一行?)、锁的类型(共享锁、排他锁)、获取和释放的顺序(防止死锁),是源码中极其复杂的一部分,这些细节直接决定了数据库在高并发下的性能和正确性,书上会说“需要并发控制”,但源码里是实打实地用一行行lock_page()、unlock_page()这样的函数调用和复杂的锁管理逻辑来搞定它的,读源码时,你会看到算法优美的“骨架”外面,包裹着为了应对混乱现实世界而生的、肌肉虬结的“锁机制”铠甲。
还有缓冲池管理,书里说为了减少慢速的磁盘IO,数据库会在内存里开辟一块区域叫缓冲池,缓存经常用到的数据页,听起来很简单是吧?但源码里的缓冲池管理器是一个极其精密的组件,它不仅要简单地缓存数据,还要决定当缓冲池满了,需要腾出空间给新页时,把哪个旧页踢出去?这就是经典的页面置换算法,比如LRU(最近最少使用),但源码里的LRU可能不是教科书上那种简单的链表实现。
比如MySQL的InnoDB存储引擎,它就把缓冲池的LRU列表分成了两段,一部分是“年轻代”,一部分是“老年代”,为什么这么搞?这是为了应对全表扫描这种“不友好”的查询,一次全表扫描会把缓冲池里所有的热点数据都冲掉,如果用的是朴素的LRU,会对其他查询的性能造成灾难性影响,这种“改进版LRU”的细节,是数据库工程师在长期实践中打磨出来的优化,是为了解决实际生产问题而生的智慧,你在书上很难看到对这种特定问题、特定优化的深入讲解,但在源码里,你能看到它具体是怎么划分链表、怎么定义页面何时从“年轻代”晋升到“老年代”的精确逻辑。
就连最基础的数据在磁盘上怎么摆放,源码里也大有学问,书里会说数据以“页”为单位存储,但一页里面呢?比如一条变长字段(VARCHAR)的记录,在页里是怎么存储的?源码里你会看到,页头可能有一个“偏移量表”,它像是一个目录,记录着每条记录在页面内的起始位置,这样,当一条变长记录更新后长度发生变化时,数据库可以不用移动后面的所有记录,只需要把新记录放在页面的空闲空间里,然后更新一下页头那个“偏移量数组”里对应的指针就行了,这种物理存储的微观结构,直接影响了更新操作的效率,这也是一个典型的“魔鬼在细节中”的例子。
《数据库系统概念》给你画了一张宏伟的蓝图,告诉你一座大厦应该有承重墙、水电管道和电梯,但源码就是那张张详细的施工图,它告诉你承重墙的钢筋要多粗、怎么捆扎,水管用什么材质的螺纹接口,电梯的缆绳的安全系数要留多少,这些细节,才真正决定了这座大厦是否坚固、耐用、高效,一点点去扒这些源码细节,虽然过程缓慢且充满挑战,但每理解一个点,就像解开了一个谜题,对数据库如何工作的认识也会变得无比扎实和深刻。

本文由盘雅霜于2025-12-30发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/71492.html