多云环境下,技术复杂又人员忙乱,流程怎么理顺才不崩盘

(根据“InfoQ”社区中多位一线技术负责人的实践经验分享整理)
多云环境就像一个人同时用好几个不同的厨房做一顿大餐,每个厨房的灶具、锅具、调料摆放规矩都不一样,而技术复杂和人员忙乱,相当于厨师们对某些新厨房不熟悉,同时又要赶时间出菜,这种情况下,如果还按照原来在一个厨房里的老办法来指挥,肯定乱成一锅粥,最后菜没做好,厨房可能还着火了,理顺流程的核心,不是去追求某个完美的技术方案,而是先让人和事情变得有序起来。
第一步:别急着灭火,先画张“厨房地图”

人员忙乱的时候,最忌讳看到问题就冲上去解决,就像厨房里一个锅着了火,所有人都去扑这个火,结果其他锅全糊了,在多云环境下,问题会像打地鼠一样从各个云平台冒出来,首要任务是让所有人对“我们在用什么”以及“谁在负责什么”有共同的认识。
这需要做两件看似简单但极其重要的事:
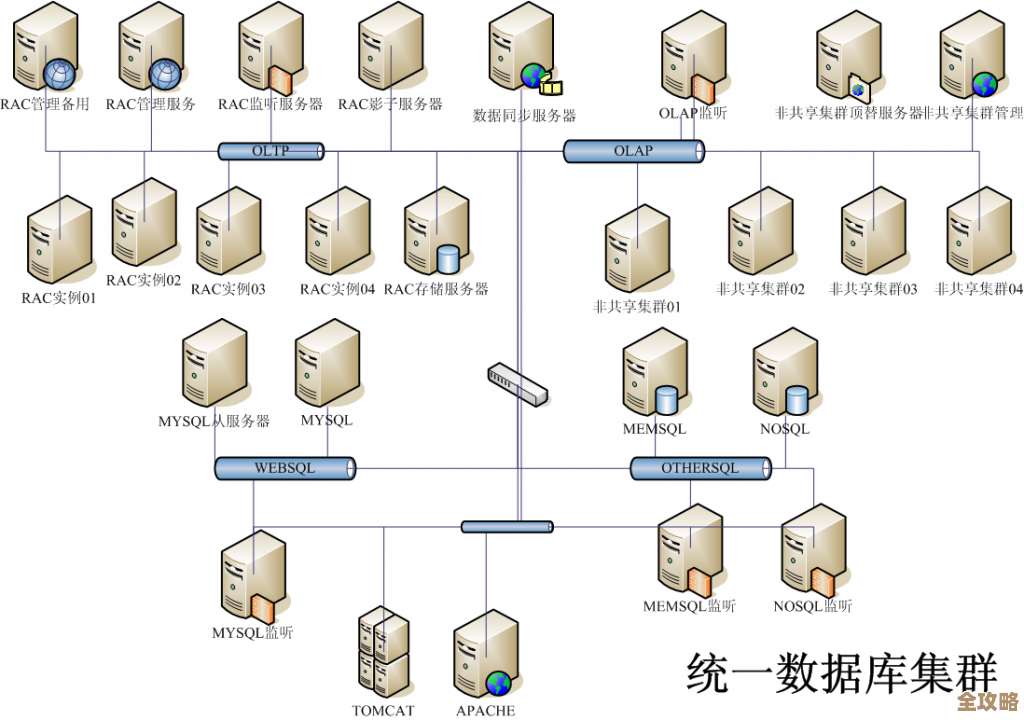
- 建立统一的资源清单:把所有云账户下的服务器、数据库、网络配置、存储等关键资源,用一个统一的视角管起来,这不一定要用特别昂贵的工具,可以是从一个简单的、定期更新的电子表格开始,关键是,要让团队主要成员能从这个清单里快速找到:“这个应用跑在哪朵云上?”“它的数据库在哪里?”“谁有权限访问?”(来源:某电商平台运维总监分享的“混沌治理”第一步)
- 明确“第一责任人”:对于每一个应用或服务,必须明确一个主要的运维或开发负责人,在多云环境下,最怕出现“我以为张三在管”“张三以为李四在管”的灰色地带,这个责任人不需要解决所有技术难题,但他的任务是“问题上报和协调的第一站”,确保任何关于该服务的异常都能被快速发现并启动应对流程。
第二步:简化操作,把复杂动作变成“傻瓜按钮”

技术复杂意味着很多操作门槛很高,需要专门的知识,在A云上扩容一台服务器和在B云上操作可能完全不同,如果每次都需要专家手动操作,不仅效率低,而且容易出错,专家也会被累死。
这时,流程理顺的关键是“标准化”和“自动化”。
- 标准化:不是说要把所有云都配置成一模一样(这很难做到),而是定义出一些标准的操作规范,无论在哪朵云上部署应用,都必须遵循相同的日志记录格式、监控指标上报方式和安全基线检查,这样,无论底层技术多复杂,上层观察和管理的逻辑是统一的。
- 自动化:把重复、繁琐的操作,比如服务器初始化、应用部署、日常巡检等,写成自动化脚本或工作流,理想情况下,开发人员只需要点一下“部署到测试环境”的按钮,背后的自动化流程就会在指定的云平台上完成所有配置和部署工作。(来源:某金融科技公司DevOps团队倡导的“自助式平台”理念)这相当于把大厨的颠勺、调味等复杂动作,封装成了一个“智能炒菜机”,普通助手也能做出标准化的菜品,这能极大减少人为失误,并把技术人员从救火中解放出来,去处理更核心的问题。
第三步:建立清晰的“火警铃”和“逃生路线”

即使做了预防,在多云环境下故障依然会发生,忙乱中最大的敌人是恐慌和无效沟通,必须有一个事先演练好的应急响应流程。
这个流程不需要长篇大论,但要回答几个关键问题:
- 警报响了怎么办?:监控系统发现异常,警报发给谁?第一责任人如果10分钟没反应,自动升级给谁?(发到团队群,如果无应答,5分钟后自动通知技术总监)。
- 初步判断怎么做?:责任人收到警报后,依据一个简单的检查清单(先查监控图表、再登录机器看日志)进行初步判断,而不是凭感觉瞎猜。
- 需要支援怎么喊?:当一个人解决不了时,如何快速发起“求助”?是拉一个临时的故障处理群,还是有一个固定的on-call(值班)小组轮换机制?关键是要让求助的路径非常清晰、没有心理负担。
- 事后必须“复盘”:每次故障处理后,无论大小,都要有一个简短的复盘会,重点不是追责,而是问三个问题:“发生了什么?”“根本原因是什么?”“我们如何防止下次再发生?”(来源:广泛采用的故障复盘“三问法”)这个过程能不断优化之前的流程和工具,形成良性循环。
在多云这种复杂又忙乱的局面下,想靠一招制胜是不现实的,理顺流程的核心思路是“化繁为简,以人为本”,先通过清单和明确责任止住混乱的蔓延;再通过标准化和自动化降低操作复杂度和人为错误;最后用清晰的应急流程给团队兜底,让大家在故障面前心中有数、忙而不乱,这一切的起点,都是先让团队的工作方式变得有序和可协作,而不是一味地去攻克最尖端的技术难题,当流程这条“流水线”顺畅了,技术的复杂性自然就在可控范围内了。
本文由帖慧艳于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/71817.html