Redis里头空间到底咋用的,调研了下占用和使用情况

最近我仔细研究了一下Redis里面的空间到底是咋用的,发现情况比想象中要复杂一些,很多人可能和我一开始想的一样,觉得Redis就是个内存缓存,数据存进去占多大地方,看数据本身大小就差不多了,但实际上,水还挺深的,我来把调研到的情况捋一捋。
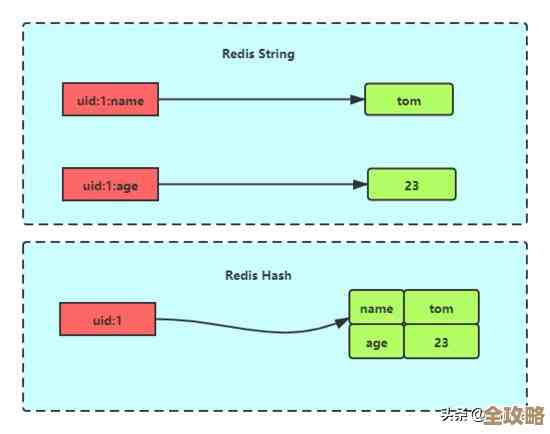
最直观的当然是你存进去的数据本身占了大部分空间,比如你存了一个字符串类型的键值对,key是"user:1001:name",value是"张三",那这部分空间就是实打实用来存这些字符的,如果你存的是哈希(Hash)、列表(List)、集合(Set)或者有序集合(ZSet)这种复杂类型,那么里面每一个字段、每一个元素也都要占用空间,这是基础,大家都懂。

但问题就在于,Redis占用的内存,远不止你存进去的原始数据那么大,有相当一部分空间被一些“看不见”的成本吃掉了,根据Redis官方文档(来源:Redis官方文档关于内存优化的章节)和一些技术社区的分析(来源:如Redis Labs博客、Stack Overflow相关高票讨论),这些额外的开销主要来自以下几个方面:
第一,保存Key本身的成本不小,每一个Key都是一个Redis对象(Redis叫它redisObject),这个对象本身就有一定的元数据开销,它会记录这个Key的数据类型(是字符串还是哈希等等)、它的编码方式、最后一次被访问的时间(用于LRU淘汰算法)、引用计数等等,这部分元数据固定就要占不少字节,如果你的业务场景里有海量的小Key(比如几百万个Key,每个Key对应的value却很小),那么光是这些Key的元数据开销累积起来就是一笔巨大的浪费,可能比实际数据占的空间还大,这就好比一个小仓库里,每个货品本身不大,但都给配了一个巨大且一模一样的包装盒,结果包装盒比货品还占地方。

第二,复杂数据结构的内部开销,这个特别重要,比如你用一个Hash结构来存一个用户对象,有姓名、年龄、城市三个字段,你以为空间就是 key + (field1 + value1 + field2 + value2 ...) 吗?不是的,Redis在内部实现这些数据结构时,自身也需要一些管理成本,在旧的Redis版本中,即使用一个Hash只存很少的几个字段,它也会预先分配一个比较大的空间(通过一个叫zipmap后来叫ziplist的紧凑结构,但一旦元素数量或大小超过阈值,就会转成标准的hashtable),而一个标准的hashtable,为了保持高效的查找性能,通常会预留一部分空闲位置(负载因子小于1),这又会造成一定的空间浪费,列表、集合等结构也是类似的道理,存储大量小型复杂结构(比如几万个Hash,每个Hash只存几个字段)时,其内存利用率可能非常低。
第三,内存分配器的开销,Redis默认使用的内存分配器是jemalloc,它为了减少内存碎片、提高分配效率,会以特定的尺寸规格(比如8字节、16字节、32字节...以此类推)来分配内存,这就会导致一种情况:你的数据可能只需要10字节,但分配器会直接给你分配16字节的空间,那多出来的6字节就浪费了,这个叫内部碎片,当你的数据尺寸五花八门时,这种内部碎片积少成多,也会占用不少内存。

第四,主从复制和持久化时的额外开销,如果你开启了持久化(AOF日志),或者有从节点(slave)进行数据同步,在特定时刻也会产生额外内存占用,在进行RDB快照(持久化的一种方式)生成时,Redis会使用操作系统的“写时复制”(Copy-on-Write)机制,这期间,如果主进程有数据修改,Redis就需要将被修改的数据页复制一份,这样在快照生成期间,内存中可能会同时存在两份数据,导致内存使用量短暂飙升,甚至可能达到平时的一倍,如果机器内存紧张,这就非常危险了,同样,从节点刚连接上主节点进行全量同步时,也会在本地创建一个完整的数据集副本,这会消耗和主节点差不多大小的内存。
第五,过期键的清理不是实时的,Redis删除过期键主要有两种策略:被动删除(当这个键被访问时发现它过期了,才删除)和主动定期删除(每隔一段时间随机检查并删除一批过期键),这意味着,在两次主动删除之间,大量已经过期的键其实还留在内存里,并没有被立刻释放,如果你一瞬间设置了大量短期过期的键,那么在一段时间内,这些“僵尸”键会一直占用着内存,直到被清理掉。
总结下来看,Redis的空间使用情况可以大致用一个公式来理解:总内存占用 ≈ 原始数据大小 + Key的元数据开销 + 值数据结构的内部管理开销 + 内存分配器碎片 + 复制/持久化等运营开销。
要想搞清楚自己Redis实例里空间到底被谁用了,不能光看数据量,最好使用Redis自带的命令深入分析,最强大的工具是redis-cli附带的--bigkeys选项(来源:Redis命令行工具文档),它能扫描整个数据库,找出哪种数据类型以及哪个最大的Key占用了最多内存,更详细的分析可以用MEMORY USAGE <key>命令(来源:Redis命令文档),它可以精确计算出一个Key及其value实际占用了多少字节,这个计算就包含了前面提到的各种开销,通过INFO MEMORY命令(来源:Redis命令文档)则可以查看整个实例的内存使用概况,包括已用内存、峰值内存、内存碎片率等关键指标,内存碎片率如果远大于1,比如达到1.5以上,就说明碎片化比较严重了,可能需要采取措施。
了解了这些,再去优化Redis的内存使用就会更有方向了,避免使用海量小Key,可以考虑将多个小Hash合并成一个大Hash;根据业务情况选择合适的、更紧凑的数据类型和编码方式;设置合理的内存上限和淘汰策略(maxmemory-policy),防止内存耗尽;定期检查并处理内存碎片问题等等,Redis的空间使用是一门学问,不能想当然。
本文由颜泰平于2025-12-31发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/71961.html