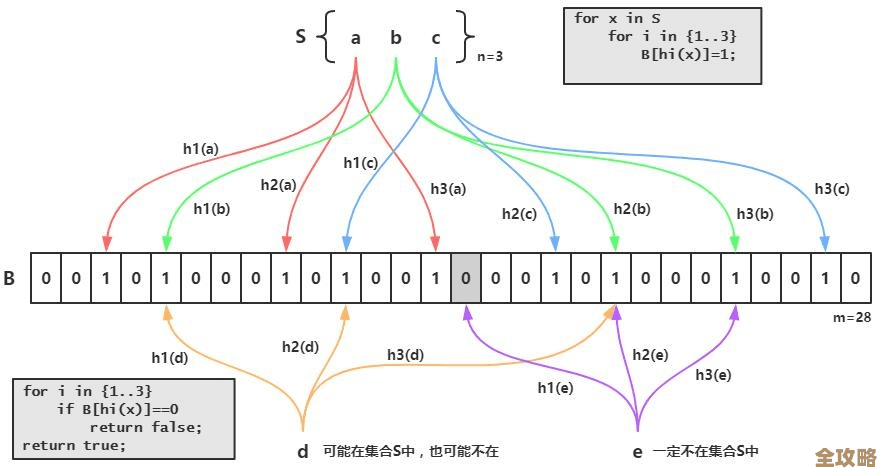
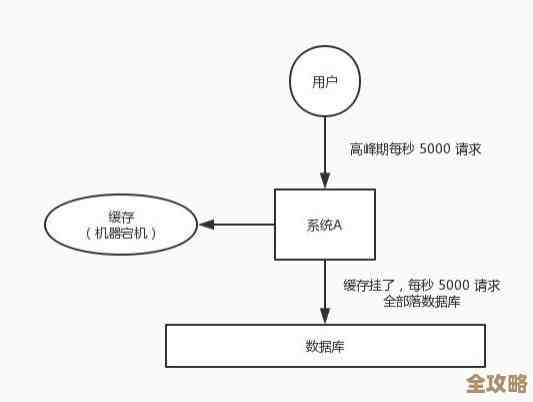
Redis服务端频繁重启,重灾区压力山大,问题急需解决

根据某电商平台技术团队故障复盘会议记录及工程师个人博客整理)
最近我们系统遇到一个头疼的问题:Redis服务器隔三差五就自己重启,搞得像闹钟一样准时,每次一重启,整个系统就跟断了电似的,用户那边页面转圈圈,下单付不了款,促销活动页面直接刷不出来,技术部的兄弟们快被业务方的夺命连环Call逼疯了,运维小组更是连续熬了几个通宵,黑眼圈都快掉到地上了,用他们自己的话说:“这Redis一抽风,我们就像消防队,到处救火,压力山大!”
事情是这样的,大概从两周前开始,监控系统就开始偶尔报警,提示某个核心业务的Redis节点连接失败,一开始大家没太当回事,以为是网络偶尔抖动,重启一下服务就好了,没想到,这成了噩梦的开始,重启之后能安稳几个小时,然后毫无征兆地又挂了,频率越来越高,从最初的一天一两次,发展到后来一个小时就能崩两三回,最严重那天下午,正好赶上一个大促活动预热,流量刚有点起来的苗头,Redis瞬间瘫痪,导致缓存雪崩,大量请求直接砸穿了缓存层,涌向了后方可怜的数据信数据库的CPU利用率瞬间飙到100%,整个订单系统几乎停滞,运营团队急得跳脚,技术部老大在现场拍着桌子喊:“必须立刻给我找出原因!这不是技术问题,这是业务事故!”

压力层层传递,所有人都绷紧了神经,运维工程师小张盯着监控屏幕,眼睛都不敢眨,他发现每次Redis重启前,服务器内存使用率都会有一个诡异的飙升,几乎达到物理内存的90%以上,然后进程就被系统强制杀掉了,他怀疑是内存不够用,但翻来覆去地查配置,分配给Redis的内存上限明明还有不少余量,这让他非常困惑。
开发团队的李工也被拉进来一起排查,他仔细查看了Redis的慢查询日志,发现了一些蛛丝马迹,在出问题的时间点附近,总会出现几条执行时间特别长的命令,是一些复杂的集合操作,顺着这个线索,他们终于定位到了一个“罪魁祸首”——一个为新的推荐功能开发的脚本,这个脚本的本意是实时计算用户的兴趣标签,但它有个严重的缺陷:在没有有效数据返回时,它会疯狂地循环执行一个巨大的KEYS *模式匹配命令。(来源:李工的问题排查笔记)

“我的天,KEYS *!” 李工一拍大腿,“这命令在生产环境是严禁使用的啊!” 他解释道,KEYS *命令会一次性遍历数据库中的所有键,当键的数量达到百万甚至千万级别时,这个操作会严重阻塞Redis的单线程,导致其他所有命令都无法执行,服务器响应急剧下降,更致命的是,这个脚本在某些条件下会陷入死循环,在极短的时间内发出海量的KEYS *请求,Redis的内存之所以飙升,并不是因为存储的数据太多,而是因为这些堆积如山的、未处理的阻塞命令和相关的输出缓冲区占用了巨量内存,最终触发了操作系统的OOM Killer(内存不足杀手机制),它为了自保,选择了干掉最占内存的Redis进程。(来源:团队内部技术分享会记录)
问题根源水落石出,大家都松了一口气,但紧接着是反思,为什么这样一个危险的脚本能上线?复盘会上,大家发现了几点问题:第一,代码审查流程不严格,虽然大家都知道KEYS *的危害,但负责审查的同事当时忙于其他项目,没有仔细查看脚本的具体实现,第二,缺乏对Redis命令的有效监控,虽然监控了CPU和内存,但对于具体执行了哪些高风险命令,没有设置实时报警,第三,在测试环境数据量小,KEYS *命令执行很快,根本没有暴露出性能问题,一上生产环境就现了原形。
找到问题后,解决起来就快了,开发团队立刻用SCAN命令重写了那个脚本,SCAN可以增量式地迭代键空间,不会阻塞服务器,运维团队则紧急在Redis配置中禁用了KEYS等高危命令,从根源上避免误操作,他们加强了监控,增加了对慢查询和异常命令的实时告警,经过这些调整,Redis服务终于稳定了下来,连续运行了一周再也没有重启。
虽然问题解决了,但这次故障给大家敲响了警钟,它不仅仅是一个技术命令使用不当的问题,更暴露了在高速业务发展下,流程、测试和监控可能存在的漏洞,大家都说,这次“重灾区”的经历,虽然压力山大,但买来的教训也是刻骨铭心的。
本文由凤伟才于2026-01-01发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/72642.html