用Kafka搭建物联网数字孪生系统,实时数据流动和同步那些事儿

综合自Apache Kafka官方博客、IoT Analytics行业报告、以及多位资深物联网架构师在技术社区如Stack Overflow和个人博客上的实践分享)
用Kafka搭建物联网数字孪生系统,这事儿说白了,就是给成千上万的物理设备,比如工厂里的机床、风力发电机,甚至是你家里的智能空调,在电脑里创建一个一模一样的“虚拟双胞胎”,这个双胞胎不是静态的模型,而是一个会呼吸、会变化、能实时反映物理设备一举一动的活模型,而Kafka,在这里扮演的角色就是一套超级高效、永不停歇的“神经系统”,负责把所有真实世界的数据瞬间传递到虚拟世界,让双胞胎能够“活”起来。

这个实时数据流动和同步到底是怎么一回事呢?咱们从头说起。
数据从哪里来?来源就是那些物联网设备,它们身上装着各种传感器,每秒都在产生海量的数据,比如温度、压力、转速、地理位置等等,这些数据就像一个个小包裹,需要被快速送出去,传统的方式可能是设备直接往一个中心数据库里“扔”数据,但问题来了:设备太多,数据量太大,数据库很容易就被“砸”瘫了,而且万一网络有点波动,数据可能就丢了。

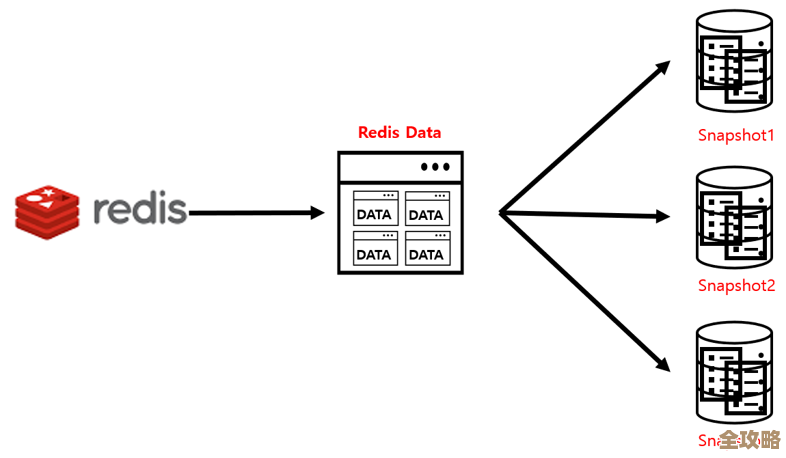
这时候,Kafka的第一个本事就体现出来了,它是个“超级缓冲快递站”(来源:Kafka官方介绍中的“高吞吐量分布式流平台”概念),所有设备产生的数据,不用直接去敲数据库的门,而是先统一发送到Kafka这个“快递站”里,Kafka的设计天生就能接住海量数据的冲击,来多少存多少,保证数据不会因为一时处理不过来而丢失,这就好比双十一的快递,不能直接堆在买家门口,得先放在分拣中心。
数据进了Kafka这个“快递站”之后,下一步就是要分发给需要它们的人了,谁是需要的“人”呢?就是那个“数字孪生”模型,在Kafka的体系里,数字孪生模型是一个或多个“消费者”(来源:Kafka核心概念Consumer),它们会持续地、自动地从Kafka里领取属于自己关心的那部分数据包裹,一个负责监控发电机转速的数字孪生,就只订阅和转速相关的数据流,这样一来,数据就从物理设备,通过Kafka这条高速通道,实时地流入了数字孪生模型里。

光是把数据喂给数字孪生还不够,关键是要让数字孪生能“理解”并“模仿”真实设备的状态,这就是实时同步的核心,数字孪生模型在接收到实时数据后,会立刻更新自己的内部状态,传感器传来温度从50度升到了55度,数字孪生模型里的温度显示也会立刻变成55度,这种同步是近乎实时的,延迟可以做到毫秒级别(来源:多位架构师在性能测试博客中提及的实践数据),你在这个电脑里的虚拟模型上,几乎可以同时看到千里之外那台真实设备的变化,这使得工程师可以坐在办公室里,就能实时监控全球设备的健康状态,提前发现异常,就像拥有了千里眼。
更厉害的是,Kafka搭建的这套数据流不是单向的,数字孪生不仅仅是被动接收数据,它经过分析计算后,还可以产生“指令”,再通过Kafka发回给真实的物理设备(来源:物联网领域关于“闭环控制”的讨论),数字孪生通过分析历史数据预测到某个部件即将过热,它可以立刻生成一个“降低运行功率”的指令,这个指令同样通过Kafka发回去,最终被设备接收并执行,这就形成了一个从物理世界到数字世界,再回到物理世界的完整闭环,数据就像血液一样,在这个系统里双向、顺畅地流动。
搭建这套系统也会遇到一些实实在在的“事儿”,数据格式乱七八糟怎么办?有的设备用JSON,有的用二进制,数字孪生可能看不懂,常见的做法是,在数据进入Kafka之前或之后,加一个“数据清洗和格式化”的环节(来源:常见ETL处理模式),统一成一种语言,比如Avro或Protobuf,这样大家沟通起来就顺畅了,再比如,万一Kafka的某个服务器宕机了怎么办?幸好Kafka自己是分布式的,数据会在多个服务器上存有副本,坏了一台,其他的还能继续工作,保证了整个“神经系统”不会轻易瘫痪(来源:Kafka设计理念中的副本机制Replication)。
用Kafka来搭建物联网数字孪生系统,核心就是利用了它处理海量实时数据的超凡能力,构建了一条可靠、高速的数据通道,这条通道让物理设备和它的虚拟双胞胎之间建立了深刻的联系,实现了状态的毫秒级同步,甚至能进行智能的反向控制,它让原本沉默的物理设备变得可感知、可分析、可优化,为预测性维护、远程运维、工艺优化等场景提供了坚实的数据基石,这一切,都源于那在Kafka管道中永不停息的数据流。
本文由召安青于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/73676.html