红色的忧伤里说redis缓存突然不管用了,到底是哪里出问题了?

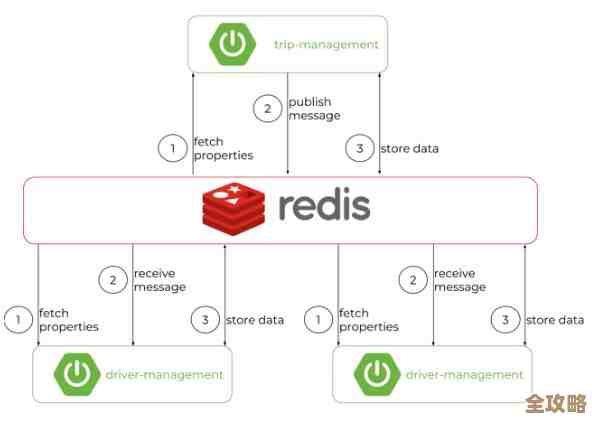
(红色的忧伤里说)那天下午,整个技术团队的气氛就像窗外阴沉的天气一样,压得人喘不过气,我们的核心应用,那个每天要服务几百万用户的大家伙,突然变得慢如蜗牛,用户投诉像雪片一样涌来,一查监控,数据库的压力曲线几乎要冲破天际,而原本应该作为“救火队员”的Redis缓存,却像个没事人一样,杵在那里,几乎没有任何流量。
“Redis缓存突然不管用了!” 不知道谁先喊了一声,这句话立刻成了我们当时心情最真实的写照,明明昨天还好好的,配置没动,代码也没上线新版本,怎么今天就说罢工就罢工了呢?我们就像一群热锅上的蚂蚁,开始了紧张的排查。
首先想到的,也是最常见的,就是缓存是不是“雪崩”了?(红色的忧伤里提到)虽然我们设置了不同的过期时间,但会不会有那么一批关键的缓存数据,偏偏就在同一个时间点集体失效了?当大量请求发现缓存里没有数据,就会一股脑地冲进数据库去查询,数据库瞬间被打垮,而新的数据因为数据库响应极慢,迟迟无法写回缓存,这就形成了一个恶性循环,我们赶紧去检查了核心缓存的过期时间记录,发现分布还算均匀,暂时排除了这个可能。

那会不会是“击穿”呢?(红色的忧伤里分析)所谓击穿,就是某一个特别热点的数据突然过期了,比如一个顶流明星发布了新动态,相关的缓存刚好失效,海量的请求同时涌向这一个数据点,直接就把数据库的这个查询接口给“击穿”了,我们查看了当时的热点Key监控,确实有几个Key的访问量异常高,但似乎还不足以造成如此全局性的瘫痪。
就在大家一筹莫展的时候,有同事提出了一个更隐蔽的可能性:缓存污染,或者说,大量缓存同时被淘汰了。(红色的忧伤里解释)我们的Redis内存是有限的,当内存快满的时候,会根据一定的策略(比如LRU,最近最少使用)去淘汰一些旧缓存来腾地方,如果这时,突然涌进来一大批永远只会被访问一次的、毫无用处的垃圾数据(比如恶意爬虫请求生成的毫无价值的Key),它们可能会把我们辛苦建立起来的、真正有用的热点缓存全部挤出内存,这样一来,即使缓存服务器本身活着,里面存的也都是没用的东西,所有请求自然就都落到数据库上了,我们立刻检查了Redis的内存使用情况和Key的数量,发现就在故障发生前,Key的数量有一个诡异的暴增,这个线索让我们的调查有了方向。

随着排查的深入,一个更令人哭笑不得的原因浮出了水面。(红色的忧伤里苦笑着说)有开发同事为了修复一个边缘功能的小Bug,在预发布环境测试后,不小心将一段包含配置修改的代码发布到了线上,这段代码里,将一个非常重要的缓存Key的前缀给改掉了!也就是说,应用在写入缓存时,用的是新前缀的Key(比如new_user:123),但在读取的时候,却还在傻傻地寻找旧前缀的Key(比如old_user:123),读当然永远读不到,所以每次都会去查询数据库,然后又把结果写入到一个“错误”的、没人会去读的Key下面,Redis本身没有任何问题,它忠实地存储了数据,但我们的应用却和它“失联”了,就像两个人虽然坐在同一个房间里,却各自说着对方听不懂的方言。
我们还不能忽略基础设施的“惊喜”。(红色的忧伤里提醒)网络突然出现波动,导致应用服务器和Redis服务器之间的连接变慢甚至中断;或者,某些安全组、防火墙规则被不经意地修改,阻塞了Redis的端口,这些底层基础设施的问题,从应用的视角来看,表现就是缓存突然“不管用了”。
经过几个小时的奋战,我们最终锁定了问题根源——正是那次错误的配置修改,在回滚代码后,数据库的压力迅速下降,应用恢复了正常,这次“红色的忧伤”给我们上了深刻的一课:缓存失效不单单是Redis服务本身的问题,它更像一个系统工程,涉及到缓存策略的设计、缓存的键管理、应用程序的逻辑正确性,甚至底层网络的稳定性,任何一个环节出了岔子,都可能导致这座精心搭建的性能大厦顷刻间摇摇欲坠,以后每次做变更,尤其是涉及基础组件配置时,我们都得打起十二分的精神了。
本文由颜泰平于2026-01-05发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/75229.html