Redis遇到麻烦了?聊聊那些不太正统但挺管用的解决办法

Redis遇到麻烦了?聊聊那些不太正统但挺管用的解决办法
Redis这家伙,速度快、本事大,是咱们很多系统里的“扛把子”,专门处理那些最急、最重的活儿,但俗话说得好,能力越大,捅的娄子也可能越大,当Redis真遇到麻烦时,官方手册里的标准操作有时就像“远水救不了近火”,今天咱们就不聊那些一本正经的套路,扒一扒老司机们在关键时刻使出的那些“野路子”,这些办法可能不那么正统,甚至有点“土”,但在紧要关头,还真能帮上大忙。
第一招:内存告急?别急着加机器,先来个“数据瘦身大法”
Redis最常遇到的坎儿就是内存不够用,眼看着内存使用率蹭蹭往上涨,报警短信响个不停,第一反应往往是:“快,申请一台更大的机器!”但这需要时间,而且成本高,这时候,不妨试试一些临时的“瘦身”技巧。
检查一下有没有存储了一些“鸡肋”数据?有些缓存数据,可能设置了一小时的过期时间,但实际业务上可能只用前十分钟,后面五十分钟完全是在占着茅坑不拉屎,这时候,可以写个简单脚本,手动扫描并提前删除这些“僵尸”数据,给内存减负,这招在某个知名电商网站的分享里被提到过,他们在一次大促前夜,就是通过这种清理,硬生生挤出了20%的内存空间,平稳度过了流量高峰。
再比如,对于存储的Value,是不是太“胖”了?有些人图省事,把一个巨大的JSON对象直接塞进一个Key里,能不能把它拆成几个小Key?或者用更紧凑的数据结构,比如用Hash来代替多个独立的String?虽然这会增加一点代码的复杂性,但换来内存的显著下降,这笔买卖在危急时刻非常划算,这其实就是一种“空间换时间”思想的灵活应用,只不过这里我们是用“设计的复杂度”来换“宝贵的空间”。
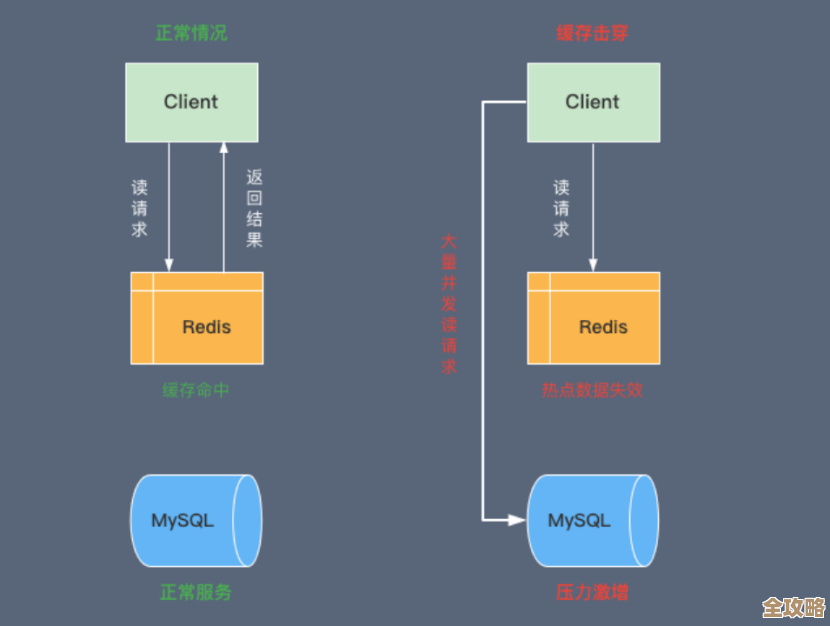
第二招:热点Key打爆服务器?试试“本地缓存+随机过期”组合拳
Redis本身没问题,但某个明星商品或者热门新闻突然火了,所有的请求像潮水一样涌向同一个Key所在的Redis实例,这就是 dreaded 的“热点Key”问题,Redis单线程的特性导致它很容易被这种单个Key的高并发读打懵。
正统解法可能是用Redis集群的读写分离,或者提前做数据分片,但如果事发突然,来不及调整架构怎么办?一个应急的办法是:在应用服务器本地加一层缓存,当发现某个Key被频繁访问时,让应用程序第一次从Redis读取后,在本地内存里也存一份,并设置一个较短的过期时间(比如几秒钟),后续的读请求直接读本地,大大减轻Redis的压力。

但这里有个坑:如果所有服务器的本地缓存同时失效,又会形成一股新的“缓存击穿”洪流冲向Redis,更聪明的做法是给每台服务器的本地缓存过期时间加一个随机值,基础过期时间是5秒,那么每台机器实际过期时间可以是5秒加上一个0到2秒的随机数,这样,缓存失效的时间点就错开了,Redis收到的请求就会是平滑的,而不是一个陡峭的脉冲,这种方法在一些互联网公司的技术博客中常被提及,是应对突发流量的经典“缓冲”策略。
第三招:持久化出问题,数据恢复慢?手动“制造”备份点
Redis的RDB和AOF持久化是数据安全的重要保障,但万一遇到极端情况,比如AOF文件巨大导致恢复时间长达数小时,业务等不起啊。
这时候,一个有点“笨”但有效的办法是:手动创建备份点,在系统低峰期(比如凌晨),你可以通过命令行执行 BGSAVE 命令,生成一个当前内存数据的RDB快照,立刻将这个RDB文件复制到安全的地方(比如另一台机器、对象存储),为了确保数据一致性,最好在备份期间暂停AOF的重写操作。
这样做的目的是,如果主Redis实例真的彻底崩溃,需要从备份恢复,你可以选择用这个“新鲜”的手动RDB文件,而不是可能已经非常庞大的AOF文件来恢复,恢复速度会快好几个数量级,虽然这会丢失从备份点到崩溃点之间的数据,但比起全量丢失或者长达数小时的停机,这点损失往往是业务可以接受的,这相当于在自动持久化机制之外,人为增加了一个可控的“安全绳”。

第四招:连接数爆表?快速定位并“踢掉”慢查询或闲置连接
Redis会突然告警连接数过多,新的请求无法接入,除了检查客户端是否没有正确关闭连接外,一个快速止血的方法是使用Redis自带的命令来诊断和清理。
用 CLIENT LIST 命令查看所有连接的详细信息,你会看到每个连接的ID、空闲时间、正在执行的命令等,重点找两类“坏分子”:一类是那些空闲时间(idle)特别长的连接,可能是客户端异常退出留下的“僵尸连接”;另一类是查看cmd字段,找出那些正在执行慢查询(KEYS * 这种破坏性命令)的连接。
找到目标后,不要犹豫,直接用 CLIENT KILL ID <连接ID> 命令把它们“踢掉”,这能立刻释放宝贵的连接资源,让服务恢复,这招有点粗暴,属于“治标不治本”,但能为你后续排查客户端代码bug或优化慢查询赢得宝贵的时间,这就像医院急诊室,先稳定生命体征,再慢慢查病因。
总结一下
这些“野路子”方法,核心思想都是在系统设计的弹性和冗余不足时,通过人工干预和灵活变通,快速恢复服务,为根本解决问题争取时间,它们就像是消防队的破拆工具,不是建房子的标准流程,但大火烧起来时,能最快地打开生命通道,事后一定要复盘,用更优雅的架构(如集群、熔断、限流)来替代这些临时方案,毕竟总不能天天靠着“救火”过日子,但无论如何,知道这些“偏方”,能让你在Redis真的遇到麻烦时,心里更有底。
本文由盈壮于2026-01-07发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/76064.html