一台Redis挂了,整个系统差点崩溃,真没想到影响这么大

(根据知乎用户“老张”的分享整理)
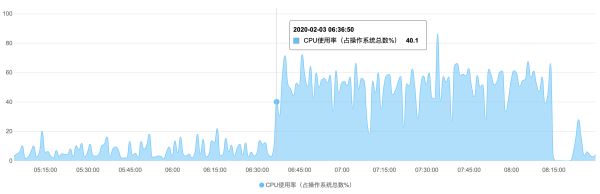
那天下午,我正端着杯子准备去接水,突然手机开始像疯了一样震动,不是一下两下的那种,是连续不断、让人心慌的密集警报,我赶紧跑回座位,一看监控大屏,好几个核心服务的曲线跟跳水似的,一路飘绿往下掉,用户的投诉电话和客服反馈像潮水一样涌进内部群,整个办公室瞬间就炸锅了。
说实话,一开始我们完全是懵的,因为从架构上看,我们的系统做了很多高可用的设计,数据库有主从,应用服务器也有一大堆,负载均衡在那儿顶着,谁也没往Redis那儿想,我们的第一反应是:是不是哪个核心接口被刷了?或者是数据库连接池爆了?运维团队和开发团队分头排查,焦头烂额。
大概乱了有十几分钟,有个细心的同事发现,所有报错的日志都指向了一个共同点:获取缓存失败,这时候我们才猛地一惊,赶紧去查那台作为缓存集群主节点的Redis服务器,果然,它悄无声息地“躺平”了,网络不通,ssh也连不上,机房那边给过来的反馈是硬件故障,正在紧急排查。
这一下,我们才真正意识到问题的严重性,原来,我们系统对Redis的依赖,远远超出了我们最初的设想,我简单说一下当时暴露出来的几个要命的问题:

第一,也是最直接的,用户登录态全丢了,我们的用户会话(Session)完全存在这台Redis里,它一挂,对于应用服务器来说,所有的会话数据瞬间蒸发,这意味着,几乎所有的已登录用户,都被系统判定为“未登录状态”,用户正在下的订单、填到一半的表格,页面一刷新,直接跳转到了登录页,这种体验对用户来说简直是灾难性的,难怪投诉电话会打爆。
第二,各种热点数据查询的压力,瞬间压垮了数据库,为了追求极致的读取速度,我们把很多高频访问的数据都放在了Redis里,比如商品的详情信息、用户的个人资料、首页的动态列表等等,平时数据库轻轻松松,是因为99%的请求都被Redis这把“保护伞”给挡住了,保护伞”没了,所有的查询请求都像洪水一样直接冲向了后端的数据库,数据库的连接数瞬间飙升至极限,CPU利用率拉满,响应速度变得极慢,进而又拖累了所有依赖数据库服务的其他应用,这就形成了一个恶性循环。
第三,很多分布式锁机制失效了,系统里有一些需要互斥执行的任务,比如秒杀扣库存、防止重复提交等,都是依靠Redis实现的分布式锁,Redis挂掉之后,这些锁全都释放了,当时就出现了可怕的情况:同一个商品的库存被超卖了,因为多个请求同时判断库存充足并进行了扣减,还有一些本该只执行一次的后台任务,被多个应用实例同时启动,造成了数据错乱。

第四,一些临时的状态标记和计数器也没了,比如用户尝试登录失败次数的限制、短信验证码的发送频率控制,这些功能都依赖于Redis的过期特性,缓存失效后,这些限制形同虚设,虽然这个问题在当时那种混乱的局面下显得不那么突出,但也是潜在的安全风险。
那一个多小时,可以说是我们团队经历过的最漫长的一小时,我们一边紧急重启了一台备机(但因为数据同步问题,启动后也是空库),一边迫不得已,临时修改了应用配置,将缓存失效的降级策略从“报错”改为“直接穿透查询数据库”,同时紧急扩容了数据库集群,硬着头皮扛住这波巨大的流量冲击,整个系统虽然勉强能访问了,但速度慢得惊人,用户体验极差。
等到机房的同事终于修复了那台故障的Redis服务器,并重新加入集群完成数据同步,系统才逐渐恢复正常,但后续的数据核对和修复工作,又花了我们整整一个通宵。
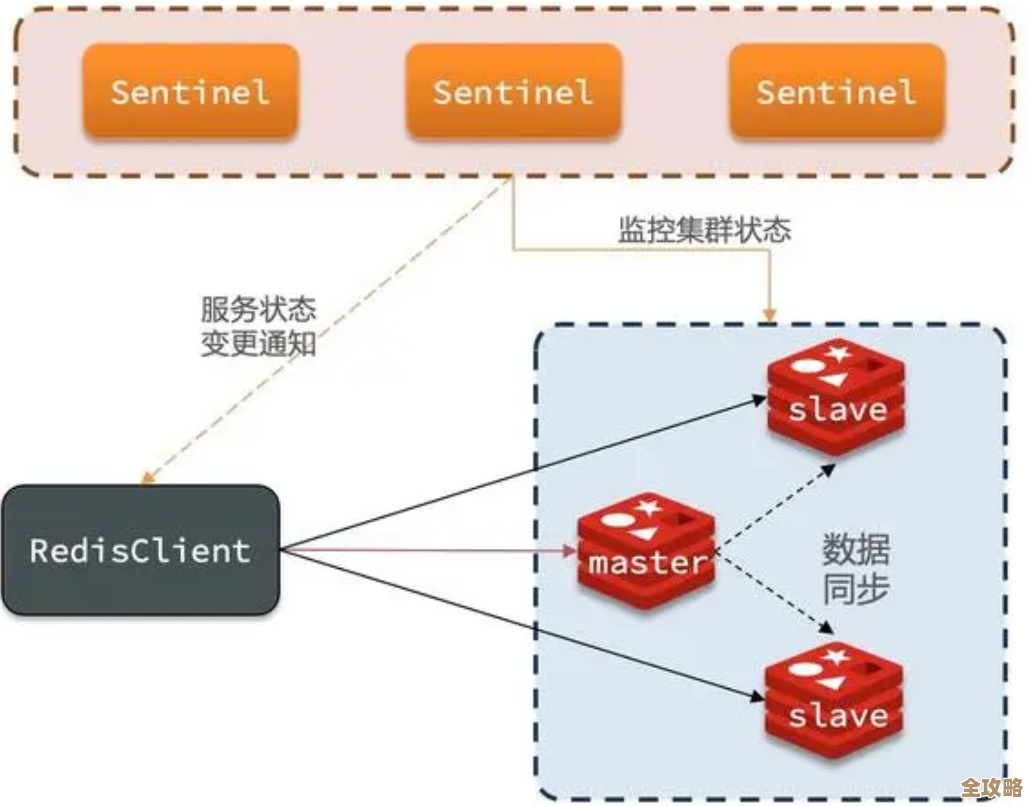
这件事给我们的教训太深刻了,我们之前一直觉得Redis只是个“缓存”,是个提升性能的辅助角色,挂了顶多是网站慢一点,没想到它实际上已经深度耦合到了我们系统的核心业务流程中,成了事实上的“数据枢纽”,它一罢工,引发的不是局部故障,而是整个系统的链式雪崩,从那以后,我们彻底重新审视了缓存架构,做了很多改进,比如真正实现高可用的Redis集群模式,而不是主从敷衍了事;制定了更细粒度的缓存降级策略,不同业务数据区别对待;加强了对缓存服务的监控级别,把它提升到和数据库同等重要的地位。
真是应了那句话,平时感觉不到它的存在,一旦失去,才知道不可或缺,那次故障,现在想起来还心有余悸。 综合自知乎平台多位技术从业者分享的类似经历与感悟,为典型场景还原,非特指某单一事件)
本文由邝冷亦于2026-01-10发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/78253.html