你对Redis集群到底知道多少,还是只是听说过而已呢?

综合了Redis官方文档、多位技术博主如“程序员囧辉”、“三太子敖丙”的相关文章,以及《Redis设计与实现》一书中的核心观点,以通俗易懂的方式呈现。)
“你对Redis集群到底知道多少,还是只是听说过而已?”这个问题问得很好,因为它直接戳中了很多人的知识盲区,很多人可能只是在简历上写了“了解Redis集群”,或者面试前背了几个概念,分片”、“主从复制”,但一旦被追问细节,就容易露馅,我们来实实在在地聊聊Redis集群到底是怎么一回事,它要解决什么问题,以及它是怎么运作的。
Redis集群诞生的根本原因就一个字:大。
当你的数据量很小,或者访问请求不多的时候,一个单独的Redis服务器(我们称之为单实例)完全够用,既简单又稳定,但想象一下,如果你的系统用户量上亿,每天产生海量的缓存数据,一个Redis实例的内存可能只有16G或32G,根本装不下这么多数据,这就是所谓的“容量瓶颈”,如果所有的读写请求都压向这一台机器,它很可能因为处理不过来而崩溃,这就是“性能瓶颈”,单点故障也是大问题,万一这台唯一的机器宕机了,整个缓存服务就全挂了。
Redis集群是怎么解决这些问题的呢?它的核心思想是“分而治之”,也就是“数据分片”(Sharding)。
你可以把Redis集群想象成一个由多个小班组(Redis节点)组成的超大车间,这个车间一共有16384个固定编号的“货位”(称为哈希槽,Slot),假设我们有三台主服务器(三个主节点),那么管理员就会大致平均地把这16384个货位分配给它们。
- 节点A负责 0 到 5500号货位。
- 节点B负责 5501 到 11000号货位。
- 节点C负责 11001 到 16383号货位。
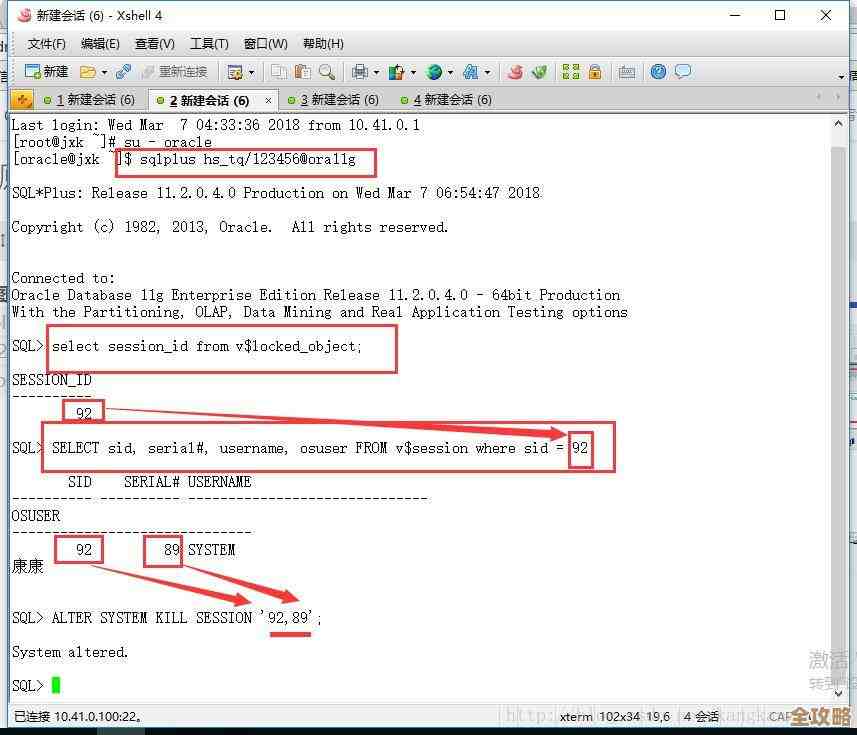
当你存入一个数据时,set user:1001 "张三",集群会用一个简单的算法(对key计算CRC16校验和,再对16384取模)算出这个key应该放在哪个货位上,算出来假设是5000号货位,那么这个数据就会被自动路由到负责5000号货位的节点A上存储。
这样一来,海量数据就被分散到了三台机器上,每台机器只存一部分,突破了单机内存的限制,读写的压力也被分摊了,实现了负载均衡,这就是集群最核心的价值。
光有分片还不够,万一某个主节点宕机了,它负责的那部分数据不就丢了吗?集群必须具备“高可用”能力。
Redis集群的高可用是通过“主从模式”实现的,上面我们说的是三个主节点,现在给每个主节点都配上一到多个“跟班”,也就是从节点(Slave),给主节点A配一个从节点A1,给B配B1,给C配C1。
平时,从节点就像主节点的影子,实时同步主节点的数据,它们不处理客户端的写请求,但可以分担读请求,一旦主节点A因为某种原因宕机了,集群中的其他节点会检测到这个情况,然后就会发起一次“选举”,将从节点A1“提拔”为新的主节点,这样,原来由A负责的那些货位(0-5500)现在由新的A1来接管了,整个过程是自动的,对客户端的影响很小(期间可能会有短暂的不可用),从而保证了服务的持续可用。
听起来很完美,但使用集群也会带来一些复杂性和限制。
最常被提到的限制就是,在集群模式下,不支持那些需要同时操作多个key的命令,除非这些key都恰好落在同一个节点的同一个货位上,你不能直接对两个分别存储在不同节点上的key执行 mget 命令,因为这会涉及到跨节点的查询,而Redis集群的节点之间并不会在查询时相互通信,你必须使用一种叫做“哈希标签”(Hash Tag)的技巧,通过将key的一部分用花括号包起来,强制让一批相关的key都落到同一个货位上。
集群的运维也变得复杂了,你需要监控多个节点的状态,处理节点的增删、数据的迁移等,当你想给集群扩容,增加一个新的主节点D时,你需要手动从A、B、C三个老节点上匀一部分货位给D,并且这个数据迁移的过程需要谨慎操作,否则可能影响线上服务。
回到最初的问题,对Redis集群“知道多少”意味着你需要理解:
- 它为什么存在:解决单机Redis的容量、性能和单点故障问题。
- 它的核心机制:数据分片(16384个槽)和请求路由。
- 它的高可用保障:主从复制和故障自动转移。
- 它的代价与限制:跨key操作受限、运维复杂度增加。
如果只是“听说过”,可能仅仅停留在“Redis集群就是把数据分开存”的层面,而真正“知道”的人,能清晰地阐述上述要点,并能结合实际场景讨论何时该用集群、何时用哨兵(Sentinel)模式就足够了,以及在使用集群时需要注意哪些“坑”,这其中的差别,正是在面试或技术讨论中体现功力的地方。

本文由称怜于2026-01-10发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/78311.html