Redis热点Key怎么找,挖掘背后那些用法和套路分享

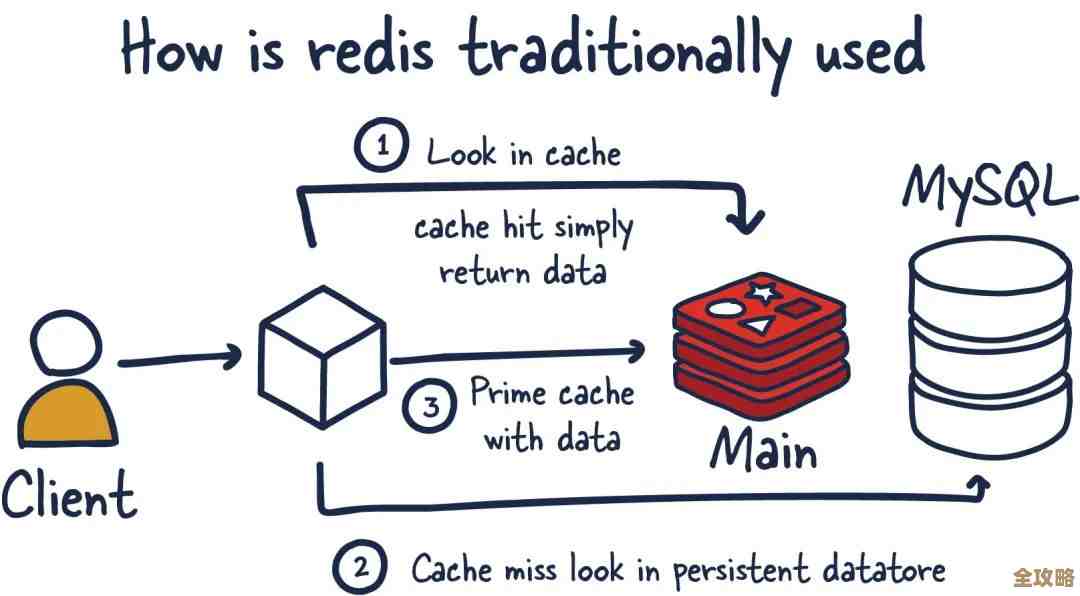
关于Redis热点Key的问题,其实就是在问:在那么多数据里,到底哪几个Key被访问得特别频繁,成了“大明星”,以至于可能拖累整个系统的表现,找这些“明星Key”并理解它们背后的业务逻辑,是优化Redis性能的关键一步。
怎么找出热点Key?
找热点Key不能靠猜,得有方法,根据网络上多位工程师的分享(例如来自阿里云数据库团队、腾讯云开发者社区等平台的公开文章),主要有以下几种实用的路子:

-
靠Redis自己报告:这是最直接的方法,Redis 4.0及以上版本提供了一个好用的命令——
redis-cli --hotkeys,你运行这个命令,Redis就会帮你扫描分析,最后给你列出哪些Key可能是热点Key,还会告诉你它们的访问频率类型(比如是读多还是写多),这就像是给Redis做了一次“体检”,能快速拿到一份嫌疑名单,但要注意,这个命令在执行时可能会对Redis服务器的性能有轻微影响,最好在业务低峰期进行。 -
靠监控工具发现:如果你用了云服务商(如阿里云、腾讯云)的Redis,或者自己搭建了监控系统(如Prometheus + Grafana),那就更方便了,在这些监控面板上,你通常可以直接看到每个Key的QPS(每秒查询次数) metrics,你把QPS从高到低排个序,排在前面的那几个“尖峰”,十有八九就是热点Key,这种方法可以实时、持续地观察,是线上环境最常用的手段之一。
-
靠代码层面打点:这个方法更主动,也更能结合业务,就是在应用程序访问Redis的代码里,埋点记录下每个Key的访问次数,每次执行
GET或SET命令前,都先在一个地方(比如本地内存或者另一个专门的统计系统)给这个Key的计数器加1,这样,你不仅能知道哪个Key热,还能清楚地知道是哪个业务操作导致了它变热,开源中国社区里有开发者分享过,他们在框架层面统一封装了Redis客户端,自动实现了这种访问日志的收集。
-
根据业务经验推测:有经验的开发者一眼就能看出哪些数据可能成为热点,全平台统一的配置信息、爆款商品的详情、顶级网红的最新一条微博、热门综艺的实时投票计数等,这些数据通常具有“全局性”和“高并发读”的特点,在项目上线前,就要把这些Key列为重点观察和保护对象。
挖掘背后的用法和套路
找到热点Key只是第一步,更重要的是搞清楚“它为什么这么热?”以及“我们该怎么办?”,这背后藏着不少设计和优化的智慧。

-
发现“只读”型热点,果断上本地缓存。
- 场景:你发现一个热点Key,比如叫
global:site_config,里面存着网站的基本设置,几乎所有页面都要读取它,但几乎从不修改。 - 背后用法:这种“读多写少”的数据,没必要每次都去访问Redis,可以在应用服务器本地加一层缓存(比如用Guava Cache或Caffeine),让数据在应用本地存一份,设置一个短暂的过期时间(比如30秒),这样绝大部分请求直接在本地就返回了,极大地减轻了Redis的压力,这是空间换时间的经典思路。
- 场景:你发现一个热点Key,比如叫
-
发现“计数”型热点,考虑分片或异步。
- 场景:一个Key叫
video:12345:view_count(视频播放次数),在热门视频发布时,每秒有上万次自增操作,Redis可能成为瓶颈。 - 背后用法:对于这种频繁写的热点,一个办法是分片,不用一个Key存总计数,而是用10个Key,
video:12345:view_count:0到...:9,每次随机选一个进行增加,最后要获取总数时,把这10个Key的值加起来,另一个办法是异步化,不每次直接写Redis,而是先把增加操作发到消息队列,然后由消费端批量合并后再更新Redis,将多次写操作合并成一次。
- 场景:一个Key叫
-
发现“大V”或“爆款”效应,做好数据隔离。
- 场景:社交平台上,某个顶级大V一发微博,他个人主页的粉丝列表
followers:user_id就会被海量查询;电商平台,秒杀商品的信息Key会被瞬间刷爆。 - 背后用法:这种热点往往伴随着突发流量,除了用上述方法,有时还需要在架构上做考虑,能否为这类顶级热点数据单独部署一个Redis实例,让它“住单间”,避免它抢光公共Redis实例的CPU和带宽资源,影响到其他普通数据,这就是一种资源隔离的思想。
- 场景:社交平台上,某个顶级大V一发微博,他个人主页的粉丝列表
-
热点Key可能是“伪热点”,优化代码逻辑。
- 场景:排查后发现,一个看似普通的Key访问量奇高,原因可能是代码里有循环调用Redis的“笨”逻辑。
- 背后用法:在循环体里频繁查询同一个用户信息,而不是先批量查询出来,找到这种代码“坏味道”,将其优化成一次批量操作(如使用
MGET),热点可能就自然消失了,这说明,有时候热点Key不是业务特性导致的,而是不良的编程习惯造成的。
找热点Key需要借助工具和监控,像侦探一样搜集证据,而处理热点Key的套路,核心思路无非是“分流”(如本地缓存、数据分片)和“减压”(如异步写入、资源隔离),最关键的是,要深入结合业务场景去分析热点产生的原因,才能选择最合适的“套路”来解决问题,让Redis这个性能加速器真正物尽其用。
本文由颜泰平于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/78411.html