数据库那些零碎点滴,帮你快速理清头绪不再迷糊

综合自网络技术博客、论坛问答及开发者社区经验分享)
你是不是总觉得数据库这东西,名字天天听,SQL也写过几句,但脑子里对它的全貌总是一团浆糊?好像知道点,又好像啥也不确定,别急,这不是你一个人的问题,今天咱们就抛开那些厚厚的教科书,像唠家常一样,把数据库那些零碎的点滴串一串,帮你理清头绪。
先打个比方:数据库就是个超级文件柜
别想得太复杂,你就把它想象成一个设计得非常科学的、巨大的文件柜,这个文件柜(数据库)里有很多抽屉(表),比如一个抽屉专门放所有用户的信息,叫“用户表”;另一个抽屉放所有商品的信息,叫“商品表”。
每个抽屉里呢,都是一摞一摞格式统一的卡片(行),每一张卡片代表一个具体的人或物,而卡片上印好的那些栏目,姓名”、“年龄”、“电话”(列),就是用来填写具体信息的,这样,你想找“张三”的电话,就不用翻箱倒柜,直接打开“用户表”这个抽屉,找到“姓名”是“张三”的那张卡片,看一眼“电话”栏目就行了,这个“找”的动作,就是SQL查询。
两种主流的文件柜:SQL和NoSQL
市面上文件柜主要分两种流派,弄懂这个就不容易选错。
-
SQL(关系型数据库):规矩森严的钢铁柜
- 代表:MySQL, PostgreSQL, SQL Server这些。
- 特点:就像你公司档案室的铁皮柜,规矩特别多,数据必须整整齐齐地放进事先设计好的表格里,行列分明,表与表之间还可以建立“关系”,订单表”里可以引用“用户表”里的用户ID,这样就知道订单是谁下的,优点是数据严谨,不容易出错,适合存储像银行交易、个人信息这种要求高度一致性的数据,缺点是如果数据格式不固定,或者数据量超级大、增长超级快,它可能会有点“死板”,扩展起来麻烦。
-
NoSQL(非关系型数据库):灵活能变的储物间
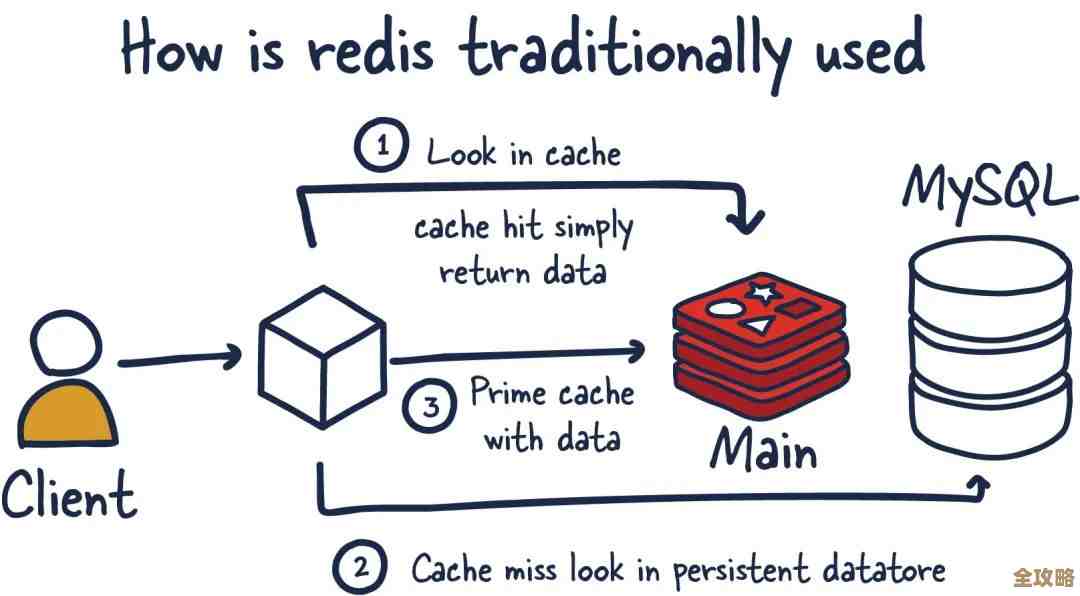
- 代表:MongoDB, Redis这些。
- 特点:这个就像你家的大储物间,没那么死板,它不强制要求数据必须是表格形式,比如MongoDB,它存的是像JSON一样灵活的文档,每个文档(相当于一张卡片)的结构都可以不一样,今天存用户信息可以带“爱好”字段,明天存另一个用户不带这个字段,完全没问题,Redis则更像一个超级快的键值对储物格,主要用来存一些临时性的、需要急速读写的数据,比如网站的登录状态、秒杀商品的库存数,优点是灵活、速度快、容易扩展,适合处理海量非结构化数据,缺点是在数据的一致性和完整性上,可能没SQL那么严格。
简单说,需要高度稳定和复杂查询的,选SQL;需要处理海量灵活数据、追求极致速度的,考虑NoSQL,现在很多大项目都是两者混着用,各干各的擅长事。
核心操作:增删改查(CRUD)
无论哪种文件柜,你对数据的操作归根结底就是四种,有个洋气的缩写叫CRUD:
- 增(Create):往柜子里新放入一张卡片,SQL里是
INSERT语句。 - 查(Read):从柜子里找出你要的卡片,这是最常用的操作,SQL里是
SELECT语句。 - 改(Update):修改某张卡片上的信息,比如改个电话号码,SQL里是
UPDATE语句。 - 删(Delete):把一张没用的卡片从柜子里拿出来扔掉,SQL里是
DELETE语句。
你平时写的绝大部分SQL,都是在和这四兄弟打交道。
两个关键概念:索引和事务
光会开柜子找东西还不够,怎么找得快、怎么保证操作不出错,是更重要的。
-
索引(Index):给文件柜贴的智能标签
- 想象一下,如果你的“用户表”抽屉里有上亿张卡片,你要找“张三”,难道要一张张翻吗?会累死的,索引就像你在抽屉侧面贴的一个智能标签页,上面写着“按姓名排序”,并且直接指向了每张卡片的位置,这样你就能用“二分法”快速定位到“张三”。索引能极大提高查询速度。
- 代价:索引不是免费的,它就像书的目录,要占用额外的空间(书变厚了),而且当你新增、删除、修改卡片时,不仅要去动卡片本身,还得去更新那个标签页(索引),所以不能瞎建索引,通常只给那些经常被用来查询的列(比如用户名、手机号)建索引。
-
事务(Transaction):要么全成功,要么全失败的安全操作
- 最经典的例子就是银行转账:从A账户扣100元,向B账户加100元,这两个操作必须作为一个“整体”来完成,绝对不能发生A的钱扣了,B的钱没加上这种鬼事。
- 事务就是干这个的,它把一系列操作打包,保证这些操作要么全部成功执行,要么只要有一个失败,就全部回滚到操作前的状态,就像什么都没发生过,这保证了数据的一致性,SQL里用
BEGIN TRANSACTION,COMMIT,ROLLBACK这些命令来控制。
数据库设计的一点门道:范式
刚开始设计表的时候,你可能会想把所有信息都塞进一张大表里,比如把用户的姓名、地址、他买的商品名、订单金额全放一起,这看起来省事,但后患无穷,比如用户地址变了,你得把他所有的订单记录都改一遍,很容易漏掉。
“范式”就是一套减少数据冗余、避免更新异常的设计准则,你不用死记硬背三范式五范式的条条框框,只需要理解核心思想:“一个东西只在一个地方说一遍”,把数据拆分成多个主题明确的表,通过“关系”连接起来,比如把用户信息单独放“用户表”,商品信息放“商品表”,订单只记录用户ID、商品ID和数量,这样地址变了,只需要改“用户表”里一个地方就行了。
数据库没那么神秘,它就是个高级文件柜,你先搞清楚自己要存什么,是规整的结构化数据(选SQL)还是灵活的非结构化数据(选NoSQL),然后学会最基本的“增删改查”来操作它,为了更快,要学会用“索引”;为了安全,要理解“事务”;为了以后好维护,设计表时要有点“拆分”的意识,别把所有东西揉成一团。
脑子里有了这个大的框架,再去看具体的SQL语法或者某个数据库的用法,就不会再觉得迷糊了,因为你知道了它们在这个框架里扮演的是什么角色,希望这些零碎的点滴,能帮你把思路理清楚。

本文由黎家于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/78417.html