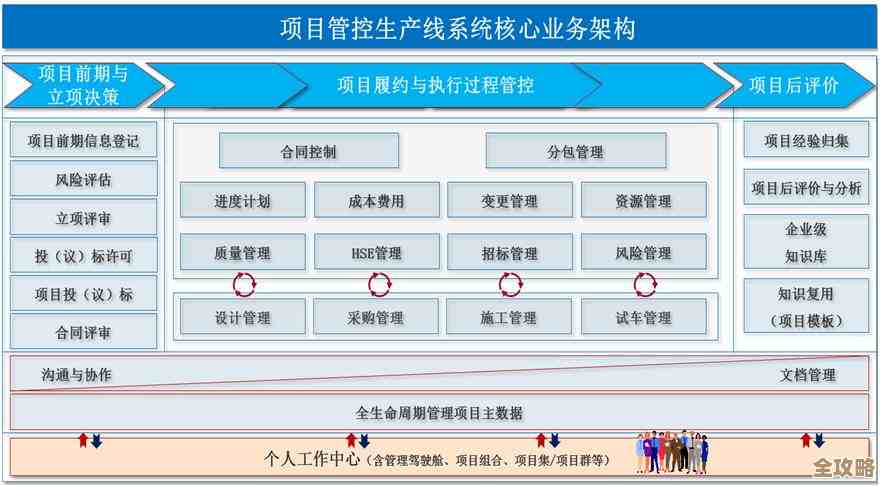
说说Hive数据库目录怎么配,配置步骤和注意点啥的

说说Hive数据库目录怎么配,配置步骤和注意点啥的
(主要参考Hive官方文档和常见大数据平台管理实践)
首先得明白,Hive本身不存数据,它是个翻译官,把SQL变成MapReduce或者Tez任务去跑,数据实际是存在HDFS上的,所以配Hive的数据库目录,本质上就是在HDFS上划出一块地方,告诉Hive:“以后建的表,数据就放这儿了!” 这个核心的位置就是由一个叫 hive.metastore.warehouse.dir 的参数决定的。
最基本的配置步骤
-
找到配置文件:Hive的配置主要在
hive-site.xml这个文件里,你安装好Hive后,通常在它的conf目录下能找到,如果没这个文件,自己创建一个就行。 -
设置仓库目录参数:在
hive-site.xml文件里,添加以下内容,假设你想把Hive的所有数据库数据都放在HDFS的/user/hive/warehouse这个目录下。<configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> <description>HDFS上的默认路径,用于存储hive表的数据。</description> </property> </configuration> -
确保HDFS目录存在且有权限:光在配置文件里写还不够,你得确保HDFS上真的有这个目录,并且Hive有权限读写它,通常需要你手动用HDFS命令创建一下,并设置好权限。
# 以Hadoop用户登录,执行以下命令 hadoop fs -mkdir -p /user/hive/warehouse # -p表示如果上级目录不存在也一起创建 hadoop fs -chmod -R 777 /user/hive/warehouse # 赋予全部用户读、写、执行权限,生产环境不能这么干,太危险!
注意:上面
chmod 777是为了测试方便,让谁都能访问,在实际生产环境,权限要严格控制,通常只给Hive的服务用户(比如叫hive)和需要使用的用户组相应的权限。 -
启动Hive验证:完成上面两步后,启动Hive命令行界面(
hive或beeline),创建一个测试表,然后插入点数据,再去HDFS上对应的目录看看,是不是真的生成了数据文件,如果能看到文件,说明基本配置成功了。
一些重要的注意点
-
HDFS是高富帅,本地文件系统是备胎:
hive.metastore.warehouse.dir这个参数默认是指向HDFS路径的,但Hive也支持把数据存在本地文件系统,file:///user/hive/warehouse。强烈不建议在生产环境这么做! 因为本地文件系统没有副本机制,数据丢了就真丢了,而且无法实现集群多台机器同时访问,这只在单机学习模式下玩玩可以。 -
权限是个大问题,不能乱来:就像前面提到的,HDFS目录的权限必须配好,Hive的元数据服务(Metastore)和执行引擎(比如HiveServer2)可能由不同的用户启动,或者多个用户都要通过Hive访问数据,如果目录权限太开放(比如777),数据安全无法保证;如果太严格,又会导致作业失败,常见的做法是:
- 仓库根目录(如
/user/hive/warehouse)由Hive管理员用户(如hive)拥有,权限是755。 - 每个数据库对应的子目录,可以由项目组或特定用户拥有,Hive管理员授予他们相应的权限。
- 仓库根目录(如
-
元数据存储是另一个关键:我们上面配的是“数据”存哪儿,但Hive还有个更重要的东西叫“元数据”,也就是表结构、字段类型、数据位置等描述信息,这个元数据默认是存在一个内嵌的Derby数据库里的,但这玩意儿只支持单会话,两个人同时用Hive就会报错。只要你不是一个人玩玩,就必须把元数据存到独立的数据库里,比如MySQL或PostgreSQL,这个配置也是在
hive-site.xml里,有一堆以javax.jdo.option开头的参数,要配数据库连接驱动、URL、用户名、密码等,这一步比配数据目录要复杂,但至关重要。 -
可以玩“分库分地”:默认情况下,所有数据库的表都放在
hive.metastore.warehouse.dir下的不同子目录里,但你也可以为某个特定的数据库指定一个完全不同的HDFS位置,在创建数据库时使用LOCATION关键字:CREATE DATABASE my_special_db LOCATION '/path/to/special/location';
这样做的好处是,可以把不同业务、不同热度的数据分离到不同的存储路径甚至不同的HDFS集群上,方便管理和进行存储策略优化(比如冷数据归档到更便宜的存储)。
-
配置完要重启服务:如果你修改的是Hive Metastore服务或者HiveServer2服务的
hive-site.xml文件,那么必须重启这些服务,新的配置才会生效,如果只是在本机客户端模式下修改,那每次启动都会读取。 -
注意NameNode的内存:Hive表如果有很多小文件(比如成千上万个),会导致HDFS的NameNode内存压力巨大,因为每个文件都会占用一部分元数据空间,所以最好在数据入库前就做好文件合并,或者使用Hive的机制(如
INSERT OVERWRITE)来定期合并小文件。
配Hive数据库目录核心就是设好 hive.metastore.warehouse.dir 参数并确保HDFS路径可访问,但真要让它稳定、安全地跑起来,还得重点处理好元数据库配置、HDFS权限管理、以及小文件问题这些“隐藏关卡”。

本文由芮以莲于2026-01-11发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/78902.html