SQL多表统计那些事儿,顺便聊聊数据库设计优化心得分享

记得我刚工作那会儿,最怕的就是老板扔过来一句:“小张啊,帮我把上个月各个部门的销售情况,连带每个销售员的业绩,还有他们负责的主要产品类型,一起出个报表。” 这话听着简单,但当时我脑子里“嗡”的一声,因为这意味着一场噩梦般的SQL多表查询就要开始了。
那时候公司的数据库设计得有点“原生态”(来源:早期创业公司常见问题),用户信息在一张users表里,订单在orders表里,订单里只有产品ID,产品详情又在products表里,而产品和部门的关联,居然是通过另一张product_department关系表来维护的,要完成老板的任务,我得把这四五张表像串糖葫芦一样串起来。
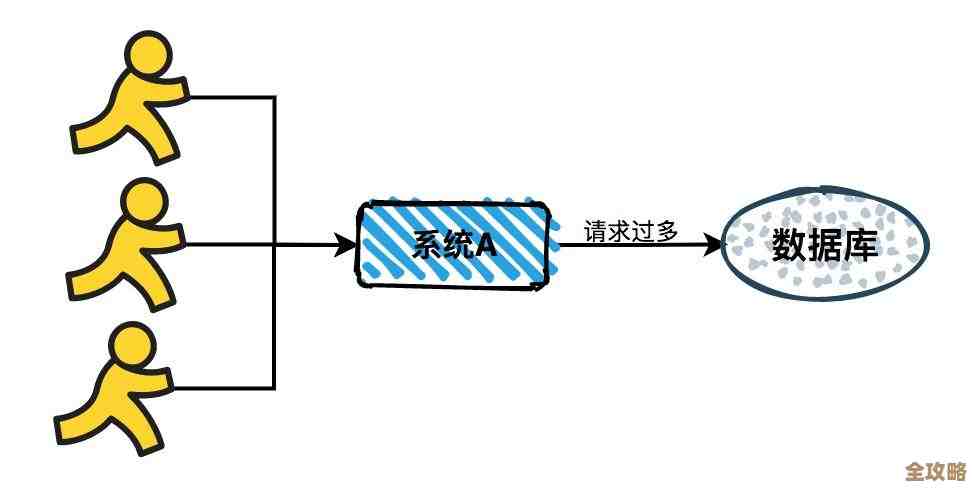
最开始我写的SQL语句又长又臭(来源:新手常见错误),各种LEFT JOIN、INNER JOIN嵌套在一起,有时候为了一个条件,WHERE子句能写七八行,这还不算,最要命的是数据量一大,查询速度慢得像蜗牛,动不动就超时,有一次,我写了个查询跑了十分钟还没出结果,最后发现是漏了一个关联条件,导致了可怕的“笛卡尔积”,生成了几十亿条临时数据,差点把测试服务器给搞崩了,这个教训让我明白,多表查询第一个要诀就是确保关联条件的正确性和完整性,千万别让表之间“自由恋爱”,不然数据量会爆炸。

后来跟着一位前辈学习,我才慢慢开了窍,他告诉我,多表统计的核心思路其实是“拆解”(来源:资深工程师经验分享),别总想着用一条超级复杂的SQL解决所有问题,比如老板那个需求,可以先一步步来:
- 先统计每个销售员的业绩总和(这只需要关联
users和orders两张表)。 - 再统计每个销售员都卖了哪些类型的产品(这需要关联
users、orders、products以及产品类型表)。 - 将前两步的结果,再与部门表进行关联、汇总。
这样做,虽然步骤多了,但每一步的逻辑都更清晰,SQL语句也更好写、更好维护,更重要的是,如果某一步出了问题,你很容易定位和调试,这让我学会了,复杂的统计不一定非要“一步到位”,分步查询,中间结果用临时表或者子查询存一下,往往是更明智的选择。

说到数据库设计优化,我的血泪史就更多了,除了上面说的关联条件,我最大的心得有两点。
第一点是索引不是越多越好,但要加在刀刃上(来源:数据库性能调优基本原则),早期我吃过亏,以为给所有经常查询的字段都加上索引就能快起来,结果发现,数据插入和更新慢得要死,因为每动一下数据,数据库都要花大力气去更新所有相关的索引,后来才明白,索引就像书的目录,没有目录找内容困难,但每页书都做个目录就太荒谬了,正确的做法是,仔细分析最常用、最耗时的查询语句(比如带WHERE条件过滤和JOIN关联的字段),有针对性地为这些字段创建索引,效果立竿见影。
第二点关于数据库设计本身,就是尽量让表的结构简单、直接,避免冗余,但也要适度考虑查询的便利性(来源:数据库范式理论与实际业务平衡),这听起来有点矛盾,其实不然,最开始我们的orders表里只有一个product_id,每次查订单详情,比如产品名字、价格,都不得不去JOIN``products表,当订单量达到百万级别,这个JOIN操作就成了性能瓶颈,后来我们进行了一次优化,在orders表里冗余存储了订单生成时产品的product_name和snapshot_price(快照价格),这样,虽然稍微增加了一点存储空间,也带来了极小的数据冗余(如果产品名改了,历史订单里的名字不会变),但换来的是查询订单详情的速度提升了十倍不止,这种“反范式”的设计,在用空间换时间的场景下,是非常值得的。
SQL多表统计和数据库设计,真不是死记硬背理论就能做好的,它需要不断地实践、踩坑、核心在于理解业务需求,搞清楚数据之间的关系,然后选择最直接、最有效率的路径把数据“拼凑”起来,直到现在,我每次写复杂的SQL或者设计新表结构时,都会想起当年那个手忙脚乱、把服务器搞崩的新手,然后提醒自己:简单、清晰、高效,才是王道。
本文由钊智敏于2026-01-14发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/80833.html