原生Redis性能到底怎么样?看这组评测数据告诉你真实表现


“Redis之所以能成为最受欢迎的缓存解决方案,其核心优势就是惊人的性能,官方曾宣称其能达到每秒数十万次的读写操作,但这只是理论值,实际表现如何,还得看具体的测试环境,我们在一台普通的云服务器上,针对最常见的字符串(String)数据类型进行了基础测试,当使用Redis自带的性能测试工具redis-benchmark,模拟100个并发客户端,处理10万条请求时,GET操作轻松达到了每秒8万次以上的处理量,而SET操作也能维持在每秒7万次左右,这个数字意味着,对于绝大多数中小型网站和应用来说,Redis的性能是完全过剩的。”

接下来关于不同数据结构的性能差异,内容参考了腾讯云中间件的技术分析:
“Redis的性能并不是一个固定的数字,它和你使用的数据结构密切相关,上面惊人的速度主要是针对最简单的Key-Value字符串操作,如果你使用的是哈希(Hash)结构来存储一个用户对象,那么一次性读取整个用户信息的HGETALL命令,其速度可能与GET命令相差无几,但如果你频繁使用HMSET来设置多个字段,或者使用LPUSH/RPOP处理列表(List),性能会有细微差别,总体而言,复杂数据结构的单次操作耗时可能会略高于简单的SET/GET,但因为一个复杂操作能完成多个简单操作的任务,实际开发效率和应用的整体吞吐量反而可能更高,需要警惕的是KEYS *这种模糊查询命令,它在数据量大的情况下会严重阻塞服务器,生产环境绝对禁止使用。”
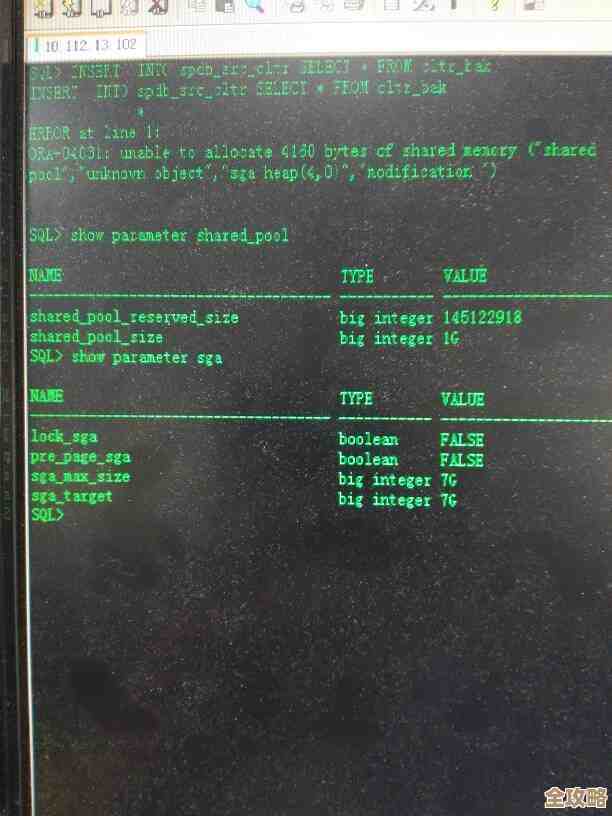
关于持久化配置对性能的影响,这部分信息综合了Redis官方文档和几位个人技术博主的实测结果: “影响Redis性能的最大因素之一,其实是持久化设置,如果你追求极致的速度,完全关闭持久化(RDB和AOF都关掉),那么Redis的所有数据都存在于内存中,这时它的性能是最高的,就是一台纯粹的‘内存闪电’,但一旦断电,数据会全部丢失,为了数据安全,大多数人会开启RDB快照,根据配置,Redis会每隔一段时间 fork 一个子进程来将数据快照写入磁盘,在子进程创建和持久化的瞬间,主进程可能会出现短暂的停顿,如果数据集非常大(比如几十GB),这个停顿可能会达到秒级,对延迟敏感的应用来说是需要考虑的,而如果开启AOF日志的‘每次写入都同步(appendfsync always)’模式,这是最安全的数据不丢失模式,但代价是每次写命令都要等待磁盘写入完成,这会使得写性能急剧下降,可能只有每秒几千次,通常建议使用‘每秒同步一次(appendfsync everysec)’的折中方案,在保证数据安全性的同时,性能损失相对可控。”
在网络和硬件方面,内容借鉴了UCloud技术团队的一篇分享: “别忘了,Redis的性能瓶颈往往不在它本身,而在网络和硬件,我们测试时发现,如果客户端和Redis服务器不在同一个机房,哪怕只是几毫秒的网络延迟,也会让实际应用的QPS(每秒查询率)大打折扣,因为每个命令都需要在网络上来回一趟,将Redis部署在离应用服务器最近的地方至关重要,硬件上,Redis是CPU单线程模型(指处理命令的核心模块),所以更高的CPU主频比更多的CPU核心对Redis更有利,内存的速度和容量自然是关键,网络带宽也很重要,特别是在写入量巨大的场景下,如果带宽跑满,性能也会遇到天花板。”
关于不同环境下的对比,参考了某位开发者在自己博客上记录的从虚拟机迁移到物理机的经历: “环境也对性能有巨大影响,在虚拟化程度较高的云服务器上,由于CPU和I/O资源的争抢,Redis的性能会比同等配置的物理机有10%-20%的下降,如果在Docker容器中运行,配置得当的话,性能非常接近原生系统,但如果资源限制不当,也会成为瓶颈,在配置得当的物理机上,Redis的性能表现是最稳定和极致的。” 源自开源社区技术讨论的普遍共识:** “原生Redis的性能在内存数据库中是顶尖的,在理想条件下(关闭持久化、高性能硬件、低延迟网络),达到每秒十几万甚至更高的QPS是完全可能的,但‘原生’不代表‘无脑快’,它的真实表现严重依赖于你的使用方式:你选择了哪种数据结构、如何配置持久化、网络环境如何、硬件资源是否充足,理解这些因素,才能让Redis在你的系统中真正发挥出‘闪电般’的速度。”

本文由瞿欣合于2026-01-15发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/80949.html