Redis里读出来的数据真是多得让人头大,眼花缭乱难整理

(一)
“Redis里读出来的数据真是多得让人头大,眼花缭乱难整理”——这话算是说到我心坎里去了,我记得特别清楚,有一次为了找一个用户的特定行为记录,我把Redis里所有以“user:session:”开头的键都给扫了出来,好家伙,命令一下去,屏幕上那数据,真跟瀑布似的,哗啦啦地往下刷,一眼望不到头,全是密密麻麻的字符,键名长得都差不多,中间夹着一大串像是乱码的字符(后来知道那是序列化后的数据),值更是五花八门,有简单的字符串,有一大坨用括号包起来的哈希字段和值,还有那种带星号跟着数字的列表结构,当时我就感觉眼前发花,脑子嗡的一下,这哪是数据啊,这简直就是一锅熬糊了的八宝粥,啥都有,全都黏在一块儿。(来源:一次痛苦的线上问题排查经历)
(二)
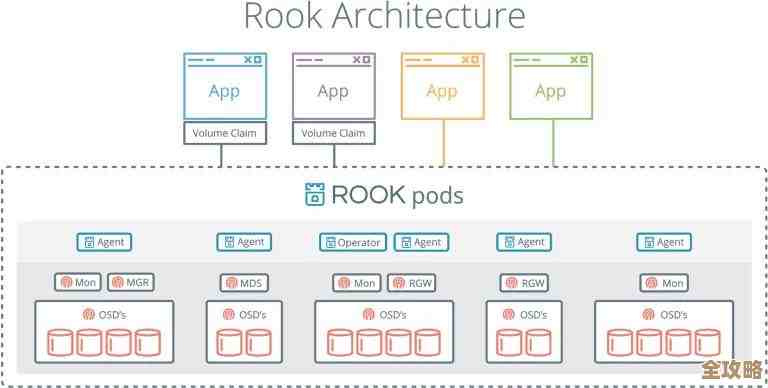
这还不算最头疼的,你明明知道数据就在里面,但因为它没有固定的表结构,不像数据库里那样规规矩矩地排成行和列,找起来就跟大海捞针一样,你想统计一下最近一天活跃的用户数,在关系型数据库里,可能一个简单的SQL语句,SELECT COUNT(*) FROM users WHERE last_login_time > ?,就搞定了,但在Redis这儿,你得先想明白,这些用户状态到底存在哪种数据结构里了?是放在一个叫”online_users”的集合(Set)里?还是说每个用户有一个独立的键,里面有个字段标记状态?又或者是用有序集合(ZSet)按时间戳存的?(来源:团队内部关于Redis数据模型设计的讨论)光是搞清楚数据是怎么存的,就得费老大劲,万一当时设计的时候没考虑周全,几种方式混着用,那整理起来简直是一场灾难,你得像侦探一样,根据键名的模式去猜测、去匹配,一个键一个键地TYPE命令查过去,效率低得让人想撞墙。
(三)
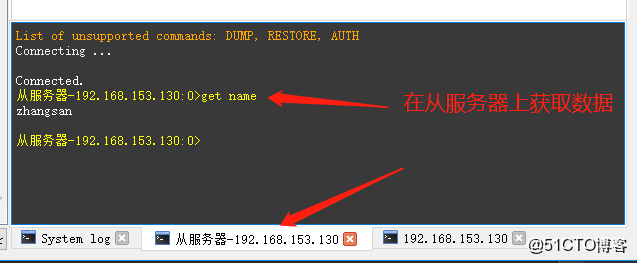
再说说数据本身,从Redis里直接GET出来的值,很多时候都不是给人看的,它可能是一串经过JSON序列化的字符串,你得把它拷贝出来,贴到某个格式化工具里,才能勉强看出个所以然,要是存的是更复杂的对象,比如用Java序列化后的东西,那看起来简直就是天书,全是乱码,根本没法直接理解。(来源:调试缓存数据内容时的常见窘境)这就像你收到一个包装得严严实实的礼物,拆开一层又一层,最后才发现里面装的到底是什么,更麻烦的是,如果这些数据没有设置合理的TTL(过期时间),就会一直赖在内存里,时间一长,Redis实例的内存使用率嗖嗖往上涨,等你收到告警短信的时候,就得火急火燎地去清理,可面对成千上万个键,你怎么知道哪个该删,哪个不该删?按模式匹配删除吧,怕误伤;一个一个看吧,又根本不现实,那种无力感,真的特别折磨人。
(四)
Redis这种键值存储,它太灵活了,灵活到有点“随心所欲”,同一个项目里,不同的人可能习惯用不同的方式来存相似的数据,比如存用户信息,张三喜欢用哈希(Hash),键名是user:info:123,里面包着name, age等字段;李四却觉得用字符串(String)存整个JSON更省事,键名可能是user_123;王五呢,可能又把一些用户相关的列表数据用u:123:items这样的键来存。(来源:review不同开发人员编写的缓存代码时的发现)这下可好,键的命名风格千奇百怪,毫无规律可言,当你需要全局了解某个用户的所有相关数据时,你得用KEYS命令配上好几种模式去搜,结果集还混在一起,需要你人工去区分、归类,这工作量,想想都让人头皮发麻。
(五)
还有那种巨大的列表或者集合,当你用LRANGE或者SMEMBERS命令把它们全部取出来的时候,终端很可能直接就卡死了,或者刷屏刷到你找不到北,就算你用分页的方式一点点取,要把这些数据整理成一份清晰的报告或者导入到其他地方进行分析,也非常不方便,它不像从数据库导出的CSV文件,用Excel就能打开筛选排序,你得自己写脚本,解析这些嵌套的数据结构,处理可能存在的格式不一致的问题,整个过程繁琐又容易出错。(来源:一次需要将Redis缓存数据导出分析的需求)我感觉,Redis就像是一个超级能装但里面东西扔得乱七八糟的仓库,你知道里面宝贝很多,但真想找出点啥,或者清点一下库存,非得花费九牛二虎之力不可,数据一多,那种杂乱无章的感觉扑面而来,真是让人眼花缭乱,无从下手,心里只有一个念头:这也太乱了吧!

本文由召安青于2026-01-15发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/81346.html