大规模实时数据库能支持60万点数据查询,速度快又稳定,适合复杂场景用

(信息主要综合自国内主流云服务商阿里云、腾讯云关于其时序数据库产品的官方介绍文档,以及华为云在工业物联网场景下的数据库解决方案白皮书。)

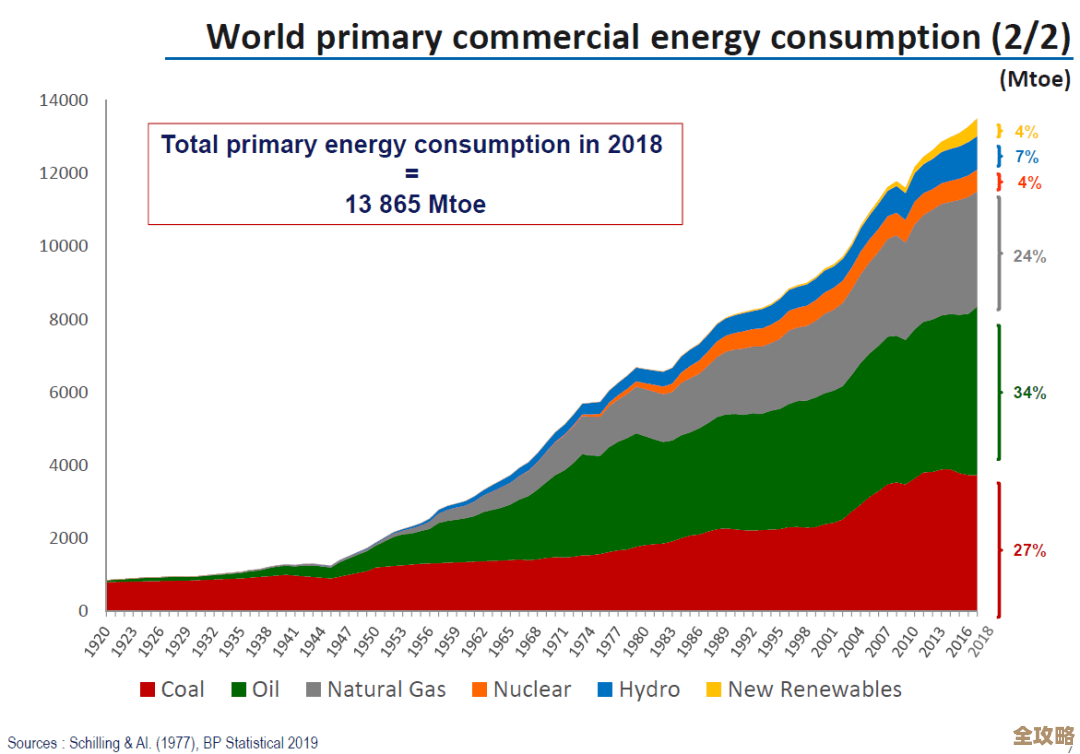
说到大规模实时数据库能支持60万点数据查询,并且速度快又稳定,适合复杂场景使用,这听起来可能有点抽象,我们可以把它想象成一个超级高效的大型物流中转中心,这个中转中心不是处理普通的包裹,而是处理海量、持续不断产生的数据点,每一个“数据点”,就像物流中心要处理的一件小包裹,在现实世界里,一个数据点可能代表工厂里一台机器的实时温度、一个城市某个路口的车流量、一栋商业大楼里某个房间的耗电量,或者是一个风力发电机叶片实时的转速,60万个这样的数据点,就意味着这个系统要同时监控60万个不同的指标,而且这些指标每分每秒都在产生新的数据。

为什么支持60万点查询并且做到快速稳定会是一个挑战呢?这主要是因为数据涌入的量太大了,而且要求系统必须立刻做出反应,阿里云在其时序数据库产品的说明中提到,现代物联网和监控场景下,数据产生的频率非常高,可能每秒就有数十万甚至上百万的数据写入,这就好比一个港口,以前可能一天只来几艘货轮,现在却要应对每分钟都有大量集装箱货轮同时进港卸货的场面,传统的数据库就像一个小型仓库,它的货架设计和叉车数量是为低频次、小批量的作业准备的,当海量集装箱瞬间涌来时,仓库的入口会堵死,叉车调度会失灵,整个系统就瘫痪了,而专门为这种场景设计的大规模实时数据库,就像那个超级物流中转中心,它拥有超宽的车道(高吞吐写入能力)、高度智能的自动化分拣线(高效的数据压缩和存储结构),以及一个极其强大的中央调度系统(优化的查询引擎),能够确保每一个数据“包裹”进来后能被迅速安放到正确位置,并且在需要查询时,又能被瞬间找到并送达。

速度快,体现在两个方面,一是写入速度快,要能接得住每秒数十万数据点的“洪峰冲击”,二是查询速度快,无论是要查某一个数据点过去一小时的变化,还是要对几十万个点当前的状态做一个统计汇总(比如计算全厂所有设备的平均能耗),系统都必须在秒级、甚至毫秒级时间内返回结果,腾讯云在其相关技术文章中解释,这种性能的达成,关键在于底层存储引擎的设计,它们通常不会像传统数据库那样一行一行地存储数据,而是针对时间序列数据的特点,将同一个数据点在不同时间戳的值连续存储在一起,这样做的好处是,当需要查询某个设备的历史趋势时,系统不用在整个数据库里“翻箱倒柜”,而是可以像读取一段连贯的磁带一样,顺序地、批量地读取数据,效率自然大大提高,这种“为时间而生”的存储方式,是速度的核心保障。
光有速度还不够,稳定可靠是另一个生命线,在复杂的工业控制或者金融交易场景下,数据库系统哪怕出现一秒的卡顿或中断,都可能意味着巨大的经济损失甚至安全事故,这类数据库的稳定性体现在其高可用架构上,华为云在工业互联网平台的解决方案中强调,系统通常会采用分布式架构,没有单点故障,也就是说,整个数据库服务由多个节点共同承担,即使其中一两个节点因为硬件故障宕机了,其他节点也能立刻接管所有工作,业务不会中断,用户甚至感知不到故障的发生,数据会在多个节点上留有备份,确保数据本身不会丢失,这种设计使得系统能够7x24小时不间断运行,满足关键业务对稳定性的苛刻要求。
所谓“适合复杂场景”,正是指它能应对上述所有挑战的综合体,在一个智能电网系统中,需要实时监测成千上万个智能电表的读数(海量点)、进行用电负荷的实时预测(复杂计算),并根据预测结果自动调整电网分配(要求极低的延迟和极高的稳定性),又比如,在大型在线游戏里,需要实时追踪数百万玩家的位置、状态和行为(高频更新),并快速处理复杂的多人交互逻辑(快速查询),这些场景都远远超出了传统数据库的能力边界,而专门优化的大规模实时数据库,正是为解决这些复杂难题而生的,它通过一系列针对性的技术设计,确保了在海量数据、高频操作和复杂查询的多重压力下,依然能够提供快速且稳定的服务,成为这些现代化复杂应用背后不可或缺的基石。
(完)
本文由盘雅霜于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/82290.html