新浪借助Redis优化性能,用户体验提升得飞起到底是咋做到的

根据新浪微博技术团队在官方博客和技术分享会上披露的信息,他们借助Redis优化性能、大幅提升用户体验的做法,核心可以概括为“把最热、最需要快速响应的数据,用最快的方式放在离用户最近的地方”,这听起来简单,但背后是一系列非常精细和巧妙的设计。
新浪面临的核心问题是什么? 在微博这样的社交平台上,用户量极其庞大,尤其是像明星发布动态、发生热点事件时,会产生海量的并发访问,一个顶级明星发一条微博,可能几分钟内就有几十万甚至上百万人来浏览、点赞、评论和转发,如果每一次用户打开这条微博,系统都去数据库里查询这条微博的内容、点赞总数、评论列表、转发数量,数据库瞬间就会被压垮,页面加载会变得极慢,用户体验极差,甚至导致服务不可用,这就是他们必须解决的“高并发读写”和“热点数据访问”的难题。
Redis是如何被用来解决这些问题的呢?

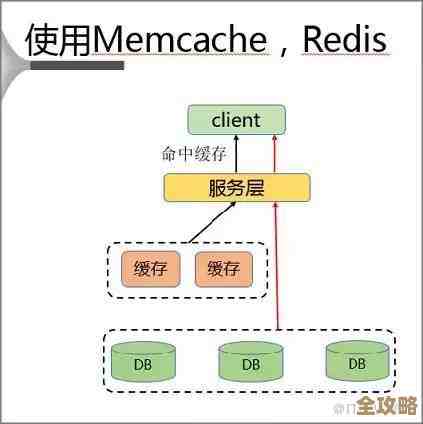
第一招:用Redis做“超级缓存”,抗住读压力。 这是最直接也是最重要的一步,根据新浪团队的分享,他们把用户访问最频繁的数据都放到了Redis里。
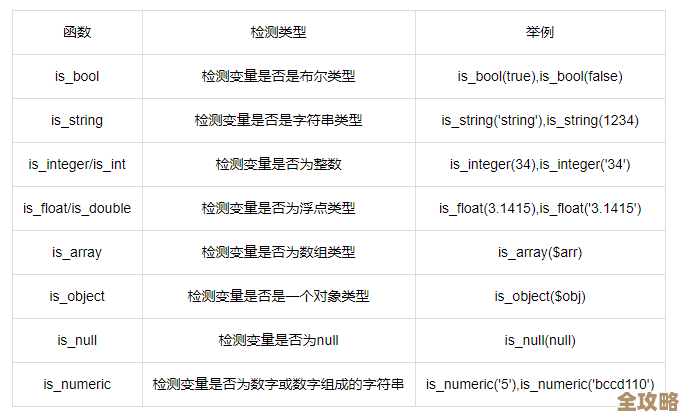
- 用户关系(关注列表/粉丝列表): 判断你是否关注了某个人,这个查询频率非常高,如果每次都去数据库查,效率低下,他们就把每个用户的关注列表和粉丝列表都以特定的数据结构存在Redis里,查询速度极快。
- 微博时间线: 你打开微博首页看到的那一长串信息流,是很多你关注的人发布的微博集合,如果实时去数据库里为每个用户拼接这个列表,根本来不及,他们的做法是:当任何一个用户发布一条新微博时,系统会立刻找到这个用户的所有粉丝,然后把这条新微博的ID“推送”到每个粉丝的个人时间线Redis队列里,这样,当你访问首页时,系统只需要直接从你自己的Redis时间线里取出最新的微博ID,然后再去缓存里批量获取这些ID对应的微博内容即可,速度得到了数量级的提升。
- 计数信息: 一条微博的点赞数、评论数、转发数,这些数据每时每刻都在变化,而且是读远大于写,如果每次点赞都直接更新数据库,然后读的时候又从数据库取,数据库压力巨大,他们使用Redis的原子计数功能来存储这些数字,点赞操作只是在Redis里给一个键的值加1,而读取这个数字则是一次极快的Redis查询,完全绕开了数据库。
第二招:不是简单粗暴地缓存,而是设计巧妙的数据结构。 新浪团队没有把Redis当成一个简单的键值对仓库,而是深度利用了它丰富的数据结构,存储一条微博的点赞列表,他们不是只存一个总数,还可能用一个集合(Set)来存储所有点赞用户的ID,这样做有两个巨大好处:

- 可以快速判断“当前登录用户是否已经对该微博点过赞”,在页面上显示已赞或未赞状态。
- 可以轻松实现点赞列表的展示。 这种设计用空间换取了时间,虽然占用内存多一些,但换来了极其迅捷的查询速度。
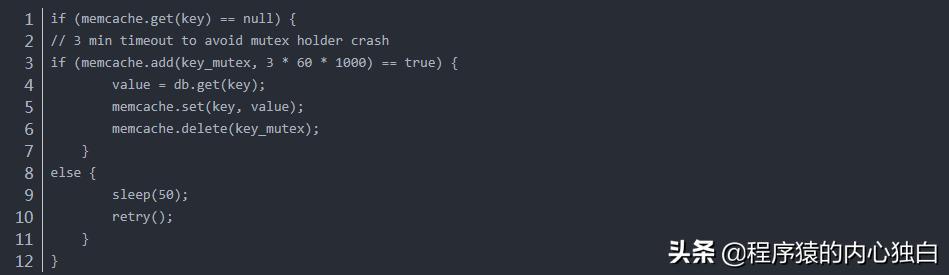
第三招:处理“写”的高并发——消息队列和异步化。 即使读了缓存,写操作(发微博、点赞、评论)依然很密集,新浪的做法是“削峰填谷”,不让写请求直接冲击核心数据库,他们同样用Redis充当了临时消息队列的角色,一个点赞请求过来,系统先在Redis里完成计数增加和用户记录,然后把这个点赞动作作为一个任务,放进一个由Redis构成的延迟任务队列里,后台有 worker 进程再慢慢地、分批地从队列里取出任务,异步地更新到持久化数据库中,这样,对于用户来说,点赞操作是瞬间完成的(因为Redis很快),而后台的数据同步则可以平稳进行,避免了数据库的瞬时高峰。
第四招:海量数据下的内存管理和集群化。 微博的数据量太大了,一台Redis服务器的内存根本装不下,新浪很早就开始使用Redis集群方案,将数据分片存储在多台机器上,实现了容量的水平扩展,他们也制定了精细的数据过期和淘汰策略,一条很久以前的、没人访问的“冷”微博,其相关数据可能会从Redis中被自动清理掉,腾出空间给新的“热”数据,这保证了有限而昂贵的内存资源总是被最需要的数据所使用。
根据其技术分享,新浪微博通过将Redis作为核心架构组件,实现了:1)缓存热点数据,极大减轻数据库读压力;2)利用丰富数据结构,实现复杂业务场景的快速查询;3)通过消息队列异步化,平滑处理高并发写请求;4)借助集群化和数据淘汰策略,管理海量数据,这一套组合拳下来,最终让用户感受到的是刷微博更流畅了,点赞评论响应更快了,即使在高峰期也不会轻易出现“服务器繁忙”的提示,用户体验自然就“飞起”了。
本文由黎家于2026-01-17发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/82626.html