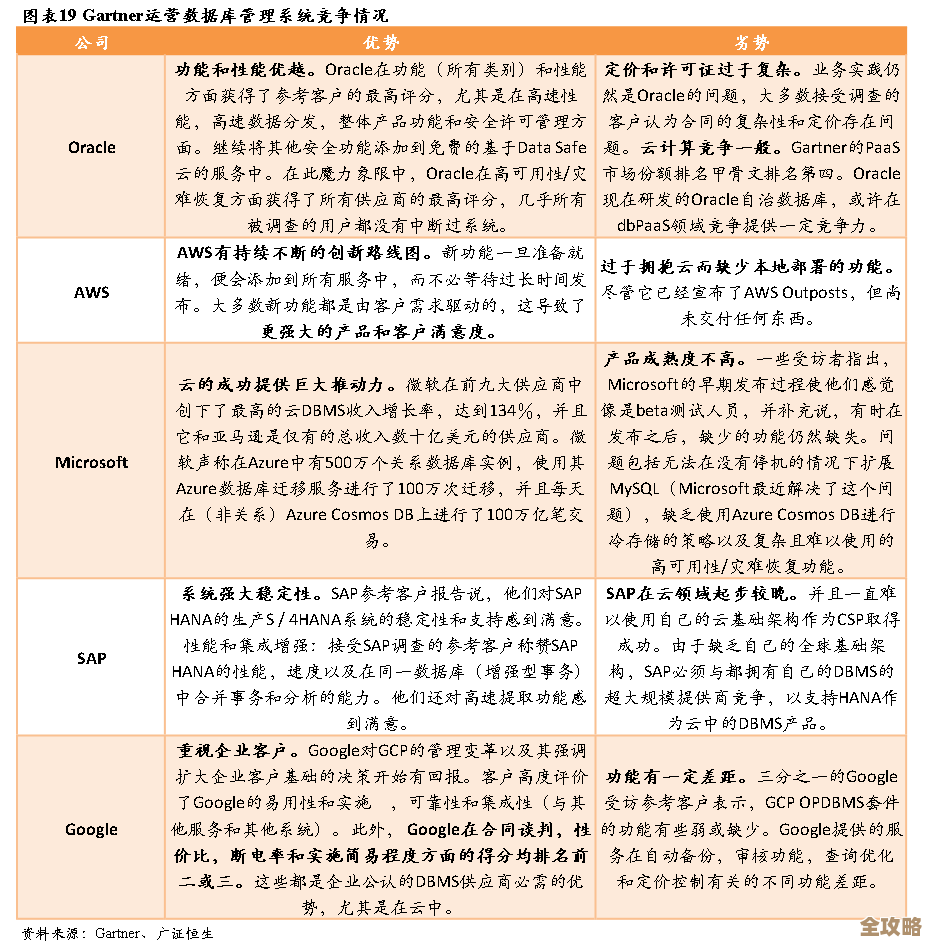
用Redis搞进程采集这事儿,怎么跑起来更顺畅点

首先得明白,用Redis做进程采集,核心是想利用它速度快、能当临时仓库和协调员的特性,但想让它顺畅跑,不卡壳、不丢数据、不打架,得在几个关键地方下功夫。
第一,连接这事儿得高效处理,别太随意。 (来源:Redis官方客户端建议及连接池最佳实践) 每个采集进程启动都去连一下Redis,用完就关,看着没问题,但进程一多,频繁连接断开对Redis服务器是负担,这就像一大群人挤一个小门,进进出出,时间都花在打招呼和告别上了,正确做法是使用连接池,简单说,就是预先建立好一批连接放着,进程需要时从池子里取一个用,用完了不是真的关闭,而是还回池子里待命,这样避免了每次建立连接的开销,速度自然就上去了,大部分成熟的Redis客户端库都自带连接池功能,配置一下最大最小连接数就行,别自己从头写。

第二,往Redis里存数据,命令要选对,别使傻劲儿。 (来源:Redis性能优化相关文档及对数据结构特性的理解)
采集的数据往往是一条条的,比如日志、监控指标,最傻的做法是每条数据都用一条SET命令,这会生成很多小命令,网络来回次数多,聪明点的话,可以用MSET一次设置多个键值,但这对结构化数据可能不太友好,更常用的方法是使用LPUSH(从左插入列表)或SADD(向集合添加),一个采集进程可以把多条数据用LPUSH your_list_key data1 data2 data3...的方式批量塞进一个列表,或者,如果数据允许重复且顺序不重要,用SADD丢进集合也行,关键是减少网络请求次数,一次多送点货,如果单条数据很大,要考虑是否在采集端先压缩一下再存,节省内存和网络带宽。
第三,进程间别打架,抢活干要有秩序。 (来源:分布式锁的常见实现方案及Redis官方对SETNX等命令的说明)
多个采集进程可能盯着同一个数据源或者任务列表,怎么避免同一个任务被多个进程重复处理?这时候需要一把“锁”,Redis可以用SET命令配合NX(不存在才设置)参数和PX(过期时间)参数来实现简单的分布式锁,进程A要处理任务X,先尝试SET lock:X "A" NX PX 10000,意思是如果锁lock:X不存在,我就设置它,值设为"A",并10秒后自动过期,设置成功了,A就去干活,如果进程B也来设这个锁,会发现已经存在,就等着或者去干别的活,干完活,A最好能主动用DEL删除锁,但为了防止A卡死导致锁一直不释放,所以设置了过期时间兜底,这样就能保证同一时间只有一个进程在处理特定任务,避免混乱。

第四,内存是有限的,不能只进不出。 (来源:Redis内存管理及数据淘汰策略)
Redis是内存数据库,采集数据如果只存不删,很快内存就爆了,然后要么写不进去,要么根据配置开始删数据,所以一定要有清理机制,有两种主要思路:一是靠Redis自身的淘汰策略,比如配置maxmemory-policy为allkeys-lru,当内存满时自动淘汰最近最少用的键,但这比较被动,更主动的方式是,根据数据特性来管理:1. 给数据设置过期时间(TTL),比如采集的临时状态数据,可能几分钟后就没用了,存的时候就用SETEX或EXPIRE设置好过期时间,让Redis自动清理,2. 对于需要持久化一段时间的数据(比如按天归档),可以由后端处理进程在成功消费并存储到永久库(如MySQL、HDFS)后,再从Redis里删除,或者写个定时脚本,定期清理老旧的数据,心里要有根弦,数据生命周期要管起来。
第五,别把鸡蛋放一个篮子里,考虑一下持久化和高可用。 (来源:Redis持久化机制(RDB/AOF)与主从复制、哨兵模式概念) 如果Redis服务器突然宕机了,内存里还没被处理完的采集数据就丢了,对于不能丢数据的场景,需要开启Redis的持久化功能,RDB是定时拍快照,AOF是记录每一条写命令,AOF的持久化更强,但性能开销也大点,可以根据能容忍的数据丢失程度来配置,比如每秒同步一次AOF,最多丢一秒的数据,单点Redis坏了整个采集就停了,所以对于重要系统,要用主从复制(Replication),搞一个备用的Redis(从库),主库的数据实时同步到从库,主库挂了,可以手动或通过哨兵(Sentinel)自动切换到从库顶上,这样服务中断时间短,采集进程能继续工作。
第六,得知道自己跑得怎么样,监控不能少。 (来源:系统可观测性基本原则)
跑起来之后,不能当黑盒子,要监控几个关键指标:1. Redis服务器的内存使用率、连接数、CPU负载,快满了要报警,2. 采集进程自身的状态:它还在正常运行吗?采集速度跟得上吗?有没有积压?可以在Redis里设个特殊键,让采集进程定期用SETEX更新一个心跳值,监控程序检查这个键如果太久没更新,就说明进程可能挂了,可以用一个列表长度来表示待处理任务数,如果这个数持续增长,说明处理速度跟不上采集速度,需要扩容或者排查瓶颈了。
一些零散但有用的点: (来源:各类技术社区的经验总结)
- Key的设计:键名最好有点规律,比如
project:module:identifier:timestamp,方便管理和批量操作,别太乱。 - 管道(Pipeline):如果确实需要连续执行多个命令,可以考虑使用管道,将多个命令打包一次发送,减少网络延迟。
- Lua脚本:对于需要原子性执行的复杂操作,可以用Lua脚本,保证在执行过程中不会被其他命令打断。
想让Redis在进程采集里跑得顺,核心思路就是:连接复用、批量操作、避免冲突、管理内存、准备后路、时刻监控,把这些点都考虑到了,并根据自己的实际场景做好配置和开发,这个流程就能稳定高效地运行。

本文由瞿欣合于2026-01-21发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/84144.html