用Redis怎么巧妙地查数据库数量,顺便说说redis里库数到底咋看

想知道Redis里怎么巧妙地查数据库数量,以及怎么看清楚Redis到底有多少个库,这事儿其实挺有意思,咱们分开来说,先说简单的“怎么看”,再说那个“巧妙”的用法。
第一部分:Redis里库数到底咋看?
你得明白Redis一个基本概念:它默认就像一栋有16个房间(数据库)的大楼,编号从0到15,你进去的时候,默认是在0号房间,这个信息是公开的,很容易查到。
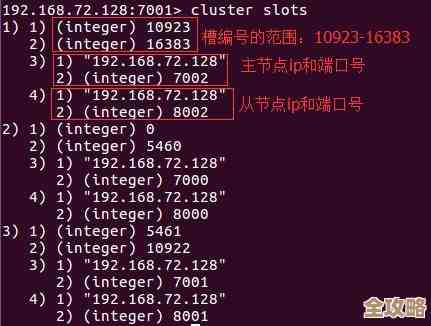
最直接的方法,就是用Redis的命令行工具,你连上Redis服务后,输入一个命令就能看到核心配置,其中就包括数据库的数量,这个命令是 CONFIG GET databases。(来源:Redis官方文档关于CONFIG GET命令的说明)

你输入之后,它会返回两行信息,第一行是"databases",第二行就是数字,比如16,这就明确告诉你,当前这个Redis服务器实例一共创建了16个数据库。
那为什么是“默认”16个呢?因为管理员可以改,这个配置写在Redis的配置文件里,通常叫redis.conf,你用文本编辑器打开这个文件,里面有一行是 databases 16。(来源:Redis官方配置文件redis.conf的默认注释和配置项)如果管理员把它改成 databases 10,然后重启Redis服务,那这栋大楼就只剩下10个房间(0到9号库)了,你用CONFIG GET databases命令看到的,永远是当前实际生效的库数量。
除了看总数,你可能还想知道“我现在在哪个库?”这就要用另一个命令了:CLIENT LIST。(来源:Redis官方文档关于CLIENT LIST命令的说明)这个命令会列出所有当前连接的客户端信息,信息量很大,你找到你自己连接的那一行(通常看addrIP地址和端口),里面会有一个db字段,比如db=0,这就表示你当前正在0号数据库里操作。
总结一下“咋看”:看总数用CONFIG GET databases,看自己在哪个库用CLIENT LIST找db字段,这都是最基础、最直接的方法。

第二部分:怎么巧妙地用Redis查数据库数量?
这里的“巧妙”,我觉得不是指用花哨的命令,而是指一种应用思路和技巧,用来解决一个实际问题:如何高效地统计所有数据库里的某个Key的数量,或者快速了解数据在各个库中的分布情况。 因为你知道了有16个库,但你的数据可能分散在其中几个里,直接查是查不到的。
经典的使用场景是:你们公司用Redis,不同业务的数据为了隔离,放在了不同的数据库里,比如用户会话存在0号库,商品缓存存在1号库,消息队列存在2号库,现在领导问你:“小张,咱们Redis里现在大概存了多少个关于用户的Key呀?” 你怎么办?
笨办法是:你一个一个库切换进去,用DBSIZE命令查看每个库的Key总数,然后自己加一起,切换库的命令是SELECT 索引号,比如SELECT 0去0号库,SELECT 1去1号库。(来源:Redis官方文档关于SELECT命令的说明)且不说手动切换16次很麻烦,关键是DBSIZE只能看总数,看不出哪些是“用户的Key”,如果你想找特定前缀的Key(比如以user:开头的),还得在每个库里面用KEYS user:*命令,这个命令在生产环境是绝对禁止使用的,因为它会阻塞整个Redis服务器,导致服务卡顿。

那“巧妙”的方法是什么呢?核心思路是:借助Redis的管道(Pipeline)技术和脚本化操作,自动化、低影响地完成跨库查询。
-
使用管道(Pipeline)批量查询DBSIZE: 你可以写一个简单的脚本(比如用Python的redis-py库),这个脚本不做危险的
KEYS操作,它只是模拟你手动操作的过程,但更快,脚本依次向Redis服务器发送16条SELECT index和DBSIZE命令(index从0到15),关键是,利用管道技术,把这16组请求一次性打包发送给Redis,减少网络往返的时间开销,然后脚本会收到16个库各自的大小,这样你就能瞬间得到一个列表,知道数据在哪个库多,哪个库少,总和是多少,这比手动快多了,而且对服务器影响极小。 -
使用内部变量或命名规范(更巧妙的办法): 最高效、最推荐的方法其实是在设计系统时就避免这种跨库统计,既然统计“所有用户Key”是常见需求,那为什么不让它们都在一个库呢?如果必须分库,还有一个巧妙的法子:用一个专用的Key来计数。 无论在哪个库,只要新增一个
user:开头的Key,你就同时在一个固定的地方(比如就在0号库)对一个叫global:user:key:count的Key执行INCR命令(加1),删除一个user:Key时,就对这个计数器执行DECR命令(减1),这样,领导问你的时候,你直接连到0号库,GET global:user:key:count,瞬间就能拿到精确的总数,根本不需要遍历所有库,这个方法的核心是“用空间换时间”,通过维护一个全局计数器,将实时统计的复杂度从O(n)降到了O(1),是最经典的优化手段。 -
使用Lua脚本(保证原子性): 对于更复杂的统计,比如你不仅要计数,还要在操作Key时同步更新计数器,为了保证“增删Key”和“更新计数”这两个动作的原子性(要么都成功,要么都失败,防止数据不一致),可以使用Redis的Lua脚本。(来源:Redis官方文档关于Eval命令和Lua脚本的说明)你可以写一个Lua脚本,把新增Key和增加计数的逻辑写在一起,Redis会保证这个脚本被执行时不会被其他命令打断。
回过头看“巧妙地查数据库数量”,它真正的精髓不在于发现Redis本身有16个库这个事实(那太简单了),而在于当你面对一个由多个Redis数据库组成的“数据大厦”时,如何运用工具和设计模式,快速、安全、高效地摸清整座大厦的“数据家底”,或者监控特定数据的流动情况,从笨拙的手动切换,到使用管道批量操作,再到通过维护元数据(计数器)实现秒级响应,这其中的思路转变,才是真正“巧妙”的地方。
本文由黎家于2026-01-21发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/84234.html