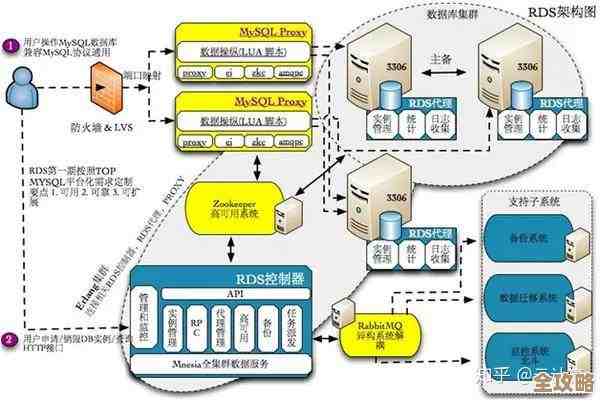
TPS数据库IO那些事儿,读写性能到底怎么才能更快点?

说到数据库的TPS和IO性能,这确实是让很多开发和运维同学头疼的大问题,TPS简单说就是数据库每秒钟能处理多少个事务,你可以把它想象成超市的收银台,TPS越高,就意味着收银台处理速度越快,排队的顾客(用户请求)就能越快完成结算,而IO,也就是输入输出,主要指的是数据库读写硬盘数据的速度,硬盘通常是整个系统里最慢的一环,就像一条高速公路突然遇到了一个狭窄的收费站,IO瓶颈就是那个收费站,车(数据)都堵在那里,CPU再快也得干等着。
怎么才能让这个“收费站”更通畅,让数据库的读写更快点呢?这事儿得从多个层面来看,不能指望一个“银弹”解决所有问题。
最直接有效的方法:升级你的硬件。
这是最“简单粗暴”但往往最见效的方法,说白了就是花钱。
- 用更快的硬盘:如果你的数据库还在用传统的机械硬盘(HDD),那首先就应该考虑换成固态硬盘(SSD),SSD的随机读写速度相比HDD有数量级的提升,对于数据库这种需要频繁随机读写小块数据的场景,效果是立竿见影的,根据腾讯云数据库的官方建议,使用高性能的SSD是保障IO能力的基石。
- 配置RAID:通过RAID技术把多块硬盘组合起来,比如RAID 10,它既能通过镜像提供数据冗余保障安全,又能通过条带化把数据分散到多块硬盘上并行读写,从而提升IO吞吐量,这相当于把单车道变成了多车道。
- 别让硬盘饿着:确保数据库服务器有足够的内存(RAM),内存的速度比硬盘快得多,数据库有一个重要的机制,就是会把经常访问的数据(称为“热数据”)缓存在内存的Buffer Pool里,当内存足够大,能装下大部分热数据时,很多读请求就直接从内存返回了,根本不用去读慢吞吞的硬盘,TPS自然就上去了,阿里云开发者社区的文章也强调,扩大Buffer Pool大小是减少物理读的关键。
在软件和架构上动动脑筋。
光有好硬件还不够,如果使用方式不对,再好的硬件也发挥不出威力。
- SQL语句的优化是根本:很多IO压力其实是“不必要的”,一条写得烂的SQL,比如没用到索引的全表扫描,可能会一下子读出几十万条数据,把硬盘IO和网络IO都占满了,而一条优化好的SQL,通过索引可能只读几条数据就搞定了,养成检查慢查询日志的习惯,看看哪些SQL是“罪魁祸首”,给它们加上合适的索引,或者重写一下逻辑,这就像是让收银员熟练操作,而不是每件商品都要翻手册查价格。
- 学会“批量”处理:频繁地提交小事务,每次都要写日志,IO效率很低,如果业务允许,可以把多个操作合并成一个批量操作,一次插入100条数据,而不是用100条SQL语句各插一条,这相当于把零散的小包裹打包成一个箱子运输,效率更高,但要注意批量不能太大,否则可能会拖慢其他事务。
- 读写分离:这是架构层面的大招,当读请求远多于写请求时,可以设置一个主数据库负责写数据,然后挂多个从数据库来分担读请求,这样写操作的IO压力集中在主库,读操作的IO压力分散到多个从库,整体吞吐量就上去了,很多云数据库服务(如华为云GaussDB的文档中也提到)都原生支持这种架构,实现起来很方便。
- 考虑分库分表:当单台数据库服务器的IO能力达到极限时,就只能“拆”了,按照某种规则(比如用户ID、时间)把一张大表的数据拆分到不同的数据库或不同的表中,这样,原本针对一个硬盘的IO压力,就被分摊到了多个硬盘上,这就像是把一个超大的超市分成几个区域,每个区域都有自己的收银台,排队压力就小了,分库分表会带来跨库查询、事务一致性等复杂问题,是最后的“大招”。
别忘了日常的运维和监控。
- 监控IO指标:必须时刻关注数据库的IOPS(每秒IO操作次数)、吞吐量(每秒读写的数据量)和IO延迟(每次IO操作的耗时)等关键指标,一旦发现这些指标持续高位运行或延迟增高,就意味着瓶颈可能出现了,需要及时处理。
- 合理配置日志文件:数据库的事务日志(如MySQL的binlog, InnoDB的redo log)写入非常频繁,应该放在性能最好的SSD盘上,并且不要和数据文件放在同一个物理硬盘上,避免它们争抢IO资源。
提升数据库的IO性能是一个系统工程,没有一劳永逸的办法,它需要你从硬件基础、SQL质量、架构设计到日常监控,进行全方位的考量和优化,通常是从最划算的SQL优化和索引入手,然后考虑升级硬件和调整架构,一步步地把那个“IO收费站”拓宽、提速,最终让你的数据库TPS跑得更快更稳。

本文由盘雅霜于2026-01-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/84334.html