Redis队列突然崩溃那会儿咋整,聊聊雪崩问题和应对办法

这事儿得从根儿上说,Redis队列,你可以把它想象成一个超级快的临时任务中转站,比如双十一的时候,成千上万的人下单,服务器一下子处理不过来,就把这些下单任务先扔到Redis这个队列里,然后后台慢慢一个一个拿出来处理,这样前端用户感觉很快,不会卡住,但万一,我是说万一,这个中转站自己突然“轰”一下瘫了,那可就出大事了,这就好比一个快递公司的分拣中心突然停电了,所有包裹都卡在那儿,送不出去,新的包裹也进不来,整个业务就停摆了。
这种情况,就是典型的“雪崩”要来的前兆,雪崩这个词儿很形象,不是说Redis崩溃本身是雪崩,而是它可能引发一连串更可怕的连锁反应,像雪山崩塌一样,把整个系统都拖垮,具体是怎么个垮法呢?

最直接的问题,任务积压,Redis队列一挂,那些本来应该被队列消化的任务,比如下单、支付、发短信通知,全堵在应用服务器里了,应用服务器自己是存不住这么多任务的,它可能因为内存爆满而先挂掉,或者变得极慢,导致用户界面直接报错或者白屏。
更可怕的是数据库被打垮,这是雪崩的核心环节,很多任务最终都是要读写数据库的,平时有队列在,像一道闸门,控制着访问数据库的流量,匀速进行,现在队列没了,闸门消失了,如果这时候运维人员心急火燎地重启了Redis,你猜会发生什么?堵了半天的那些任务,会像洪水决堤一样,“哗”地一下全部涌向数据库,数据库哪见过这阵仗,瞬间连接数爆表,CPU跑满,直接就被这波流量冲垮了,数据库一挂,所有依赖它的服务,比如用户登录、商品查询,全都玩完,整个网站或App就真的瘫痪了,这就是典型的“雪崩效应”:一个小的故障(队列崩溃),引发资源争夺的连锁反应,最终导致整个系统不可用。

那会儿咋整?不能光看着系统死掉啊,应对办法得分几步走,思路要清晰:
第一步,先止血:限流和降级。 这是最关键、最立竿见影的应急措施,一旦发现Redis连接不上,系统要能自动启动保护机制。
- 限流:立刻在应用入口处设卡,比如用网关或者专门的限流工具,只放行一小部分最重要的请求(比如用户登录、查看核心商品页),其他非核心请求(比如推荐商品、积分变动)直接返回一个友好的提示,像“系统繁忙,请稍后再试”,这招是为了保住核心业务和数据库,不让洪水形成。
- 降级:把一些非关键的功能暂时关掉,下单后发短信通知这个功能,可以先跳过,等系统恢复了再补发,或者,把一些复杂的计算结果用之前缓存的旧数据顶一下,虽然可能不是最新的,但总比完全不能用强,这招是主动放弃一些“枝叶”,保住主干的生机。
第二步,恢复队列,但要“温柔”地重启。 止血之后,得赶紧把Redis恢复起来,但切记,不能直接重启了就撒手不管。
- 重启Redis后,千万不要让所有应用服务器同时去抢着消费积压的任务,应该在代码层面做好控制,让任务处理程序(消费者)以缓慢的速度,比如平时1倍的速度,慢慢从队列里取任务来处理,这叫“慢启动”,给数据库一个缓冲的时间,让它慢慢热身,避免被瞬间击穿。
第三步,复盘和加固,防止下次再崩。 事后诸葛亮非常重要,得想想怎么让系统更健壮。
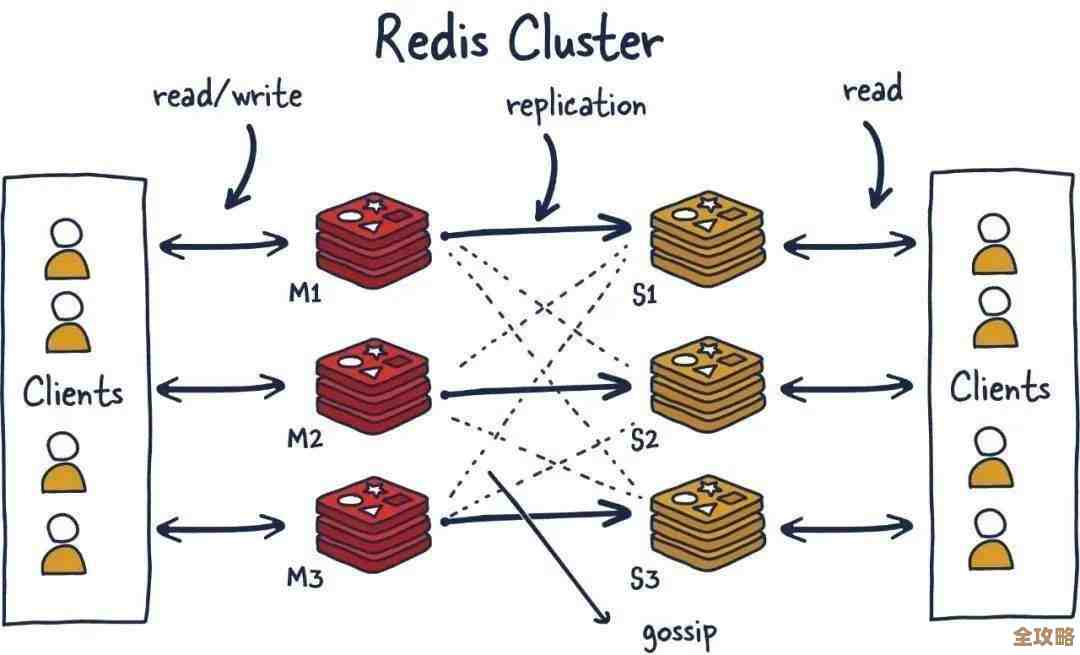
- 高可用部署:别再用单机的Redis了,太脆弱,最起码也得做个主从复制(来源:Redis官方文档),一个主节点挂了,能从节点立刻顶上去,更好的方式是使用Redis哨兵(Sentinel)或者集群(Cluster)模式(来源:Redis官方文档),实现自动故障切换,这样就算一个节点崩溃,整个队列服务还能继续用,用户可能都感觉不到。
- 设置过期时间和监控:给队列里的任务都设一个合理的过期时间(TTL),防止有些失败的任务永远堆在队列里占地方,建立完善的监控报警,不光要监控Redis是否活着,还要监控队列的长度,如果发现队列长度异常增长,就要提前预警,在崩溃发生前就介入处理。
- 业务侧做持久化兜底:对于特别重要的任务,不能完全依赖Redis这个内存数据库,因为它一重启数据可能就没了,可以在把任务放进队列的同时,也在MySQL这类硬盘数据库里存一份日志,万一队列真的崩溃且数据丢失,还能从数据库里把任务捞出来重新处理。
Redis队列崩溃本身是个事故,但真正致命的是它可能引发的雪崩,应对的思路核心就是“保护数据库,控制流量”,先通过限流降级避免系统全面瘫痪,再温柔地恢复服务,最后通过架构升级让系统变得更能“抗揍”,这样一套组合拳下来,下次再遇到类似问题,心里就不慌了。

本文由芮以莲于2026-01-23发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/84344.html