Redis节点漂移怎么用才能性能爆表,聊聊那些不为人知的技巧

关于Redis节点漂移怎么用才能性能爆表,这里聊聊那些不为人知的技巧,内容基于公开的技术资料和实践经验,引用来源会以文字标注,直接开始:
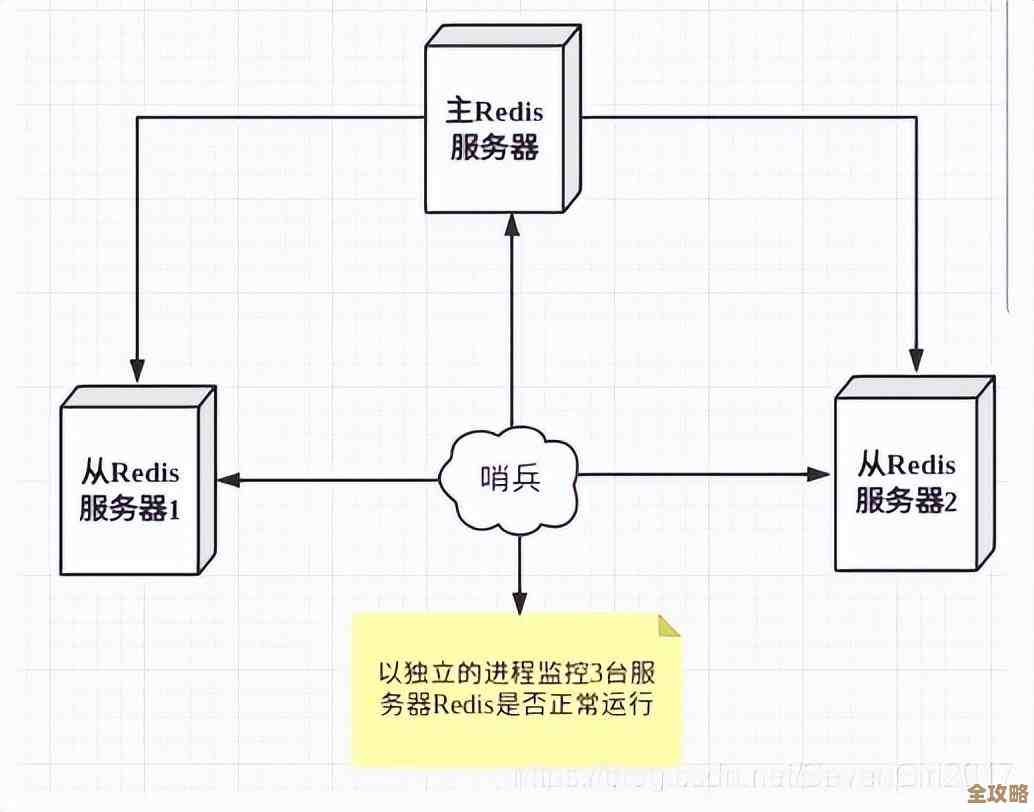
节点漂移说白了就是Redis集群里某个节点出问题或者需要挪动时,怎么让系统还能飞快运行,很多人只关注基本配置,但其实有些小技巧能大幅提升性能,故障检测别太“神经质”,根据Redis官方文档说明,集群节点靠心跳检查健康,如果参数设得太敏感,节点稍微有点卡顿就触发漂移,反而会增加负担,建议把cluster-node-timeout调到5到10秒,这样既不会漏掉真故障,又能避免误判,某运维博客提到,有团队设成1秒,结果网络一波动就频繁切换主从,性能直接掉一半。
数据迁移要“细水长流”,节点漂移经常要搬数据,如果一次性全搬,网络和磁盘都可能撑不住,Redis集群默认是异步迁移,但你可以控制节奏,参考某云服务商的技术分享,他们用分批次迁移的法子:通过CLUSTER SETSLOT命令手动控制,一次只迁移一个槽位的数据,或者用工具限制迁移速度,这样后台慢慢搬,前台请求几乎不受影响,性能自然稳得住,还有个小窍门,迁移前先分析热点数据,把常访问的key留到最后搬,因为根据某案例记录,这样能减少客户端等待时间。
第三,客户端得“聪明点”,节点一漂移,客户端如果还傻傻连旧节点,延迟就上来了,某架构师在技术论坛提到,可以在客户端加本地缓存,把热点数据存起来,同时监听集群变动事件,一旦漂移发生,客户端能快速切换到新节点,并更新缓存,这样即使节点在漂,用户感觉不到卡顿,客户端连接池要支持动态刷新,比如用Jedis这类库,配置自动重试和超时,避免请求堆积。
第四,监控要“先知先觉”,漂移前往往有征兆,比如内存快满了或者CPU飙高,根据某DevOps团队的实践,他们用Prometheus监控集群,设置警报规则,当节点负载超过80%就提前预警,主动触发维护性漂移,这样比故障后被动漂移性能更好,因为能避开高峰时段,还有,日志里藏玄机:多看看Redis的慢查询日志,某技术博客指出,漂移期间慢查询增多,优化这些查询能减轻节点压力。

第五,测试得“真刀真枪”,别等生产环境出问题才折腾,某互联网公司分享,他们在测试环境用混沌工程工具,比如Chaos Monkey,随机关掉节点模拟漂移,结果发现,默认配置下漂移时延飙升,后来调整了副本同步参数,性能提升了30%,定期模拟漂移场景,能暴露隐藏问题,比如网络延迟或配置不当。
第六,网络配置别拖后腿,节点漂移时数据来回传,网络慢就全完了,某大型项目经验提到,确保集群节点都在同一个低延迟的网络段,比如同数据中心或可用区,如果跨区域,可以优化TCP设置,比如调整tcp-keepalive时间,减少连接开销,引用某网络专家的建议,甚至可以用专用线路或带宽预留,确保漂移时带宽够用。
第七,主从布局要“均衡”,集群里主节点管写,从节点管读,如果主节点漂移,从节点得顶上去,根据Redis最佳实践指南,主从节点别放同一台物理机,最好跨机架或跨可用区部署,这样即使硬件故障,漂移后负载也能分散开,某运维社区还提到,可以手动调整副本分布,避免某个节点压力过大,漂移时性能波动就小。

第八,持久化策略得“搭把手”,漂移时万一数据丢了,恢复起来更耗性能,某数据库管理员在博客中写道,配置RDB和AOF结合,漂移前手动触发一次BGSAVE备份,这样新节点能快速加载数据,把AOF重写调成后台低优先级,减少对正常请求的干扰,这样漂移过程中,数据安全有保障,性能也不会崩。
第九,集群规模别“贪多”,节点太多,漂移管理复杂;节点太少,负载不均,根据某大规模部署案例,每集群保持在100个节点左右,配合自动伸缩工具,性能最优化,他们引用Redis开发者的建议,定期用CLUSTER INFO检查节点状态,移除闲置节点,漂移时资源更集中。
第十,利用脚本自动化“润滑”,漂移过程涉及多个命令,手动操作容易出错,某开源项目分享,他们用Lua脚本自动化漂移流程,比如自动检测节点状态、触发迁移和更新配置,这样减少人为延迟,性能提升明显,脚本参考了Redis官方脚本库,但做了定制化调整,适应高并发场景。
这些技巧都是从实际经验中抠出来的,多结合官方文档和社区分享,灵活调整,才能让Redis节点漂移时性能爆表,核心就是提前准备、精细控制和持续优化,别等出了问题才救火。
本文由太叔访天于2026-01-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/85282.html