Redis爬虫复习视频帮你快速掌握重点,学习效率马上提升不少

(根据B站UP主“编程玩家小王”的《Redis爬虫实战速成》视频内容整理)
这系列视频开头就说了,别把Redis想得太复杂,在爬虫里它就是个“超能记事本”,视频里讲师用了个很形象的比喻:你爬网站的时候,需要记下“哪些网址爬过了”、“哪些还没爬”,如果只用Python的列表或字典,程序一关数据就没了,或者数据量大了特别卡,Redis就是帮你把这些“记事儿”的活儿接过来,它放在内存里,读写速度飞快,而且能永久保存。
视频第一讲重点演示了怎么用Redis做“去重”,比如你要爬一万个商品页面,很可能这些页面的网址有重复,传统方法可能用Python的set(),但数据量大或者程序重启就麻烦了,讲师在视频里敲代码(视频05:12处),展示了用Redis的集合(Set) 特性:每拿到一个新网址,就通过sadd命令往一个叫urls:visited的键里添加,如果这个网址已经存在,命令会返回0,你就知道爬过了,这个方法只需要一行代码,比用数据库查询快得多。
(视频第二讲,根据“编程玩家小王”的演示)另一个核心用途是当“任务队列”,爬虫经常是“生产者-消费者”模式:一个程序发现新链接,另一个程序负责爬取,视频里用Redis的列表(List) 模拟了一个简易队列,发现的新网址用lpush从左边推进一个叫urls:to_crawl的列表里,而爬取程序则用brpop从右边阻塞地取出任务,讲师特别强调(视频15:30处):“brpop这个命令好处是,如果队列空了,它会安静地等着,不会死循环耗CPU,非常适合爬虫这种不定时有新任务的场景。”
视频还提到了一个容易被忽略但很实用的功能:过期键(Expire),比如有些网站登录后有会话(Session),你可以把会话信息临时存到Redis,并设置30分钟过期,这样既不用自己清理,又比放文件方便,讲师在视频里说(视频24:50处):“这招也适合存验证码,或者临时存放一些需要快速共享的中间数据,比如爬到的图片链接列表,另一个程序来取,取完自动过期,省心。”
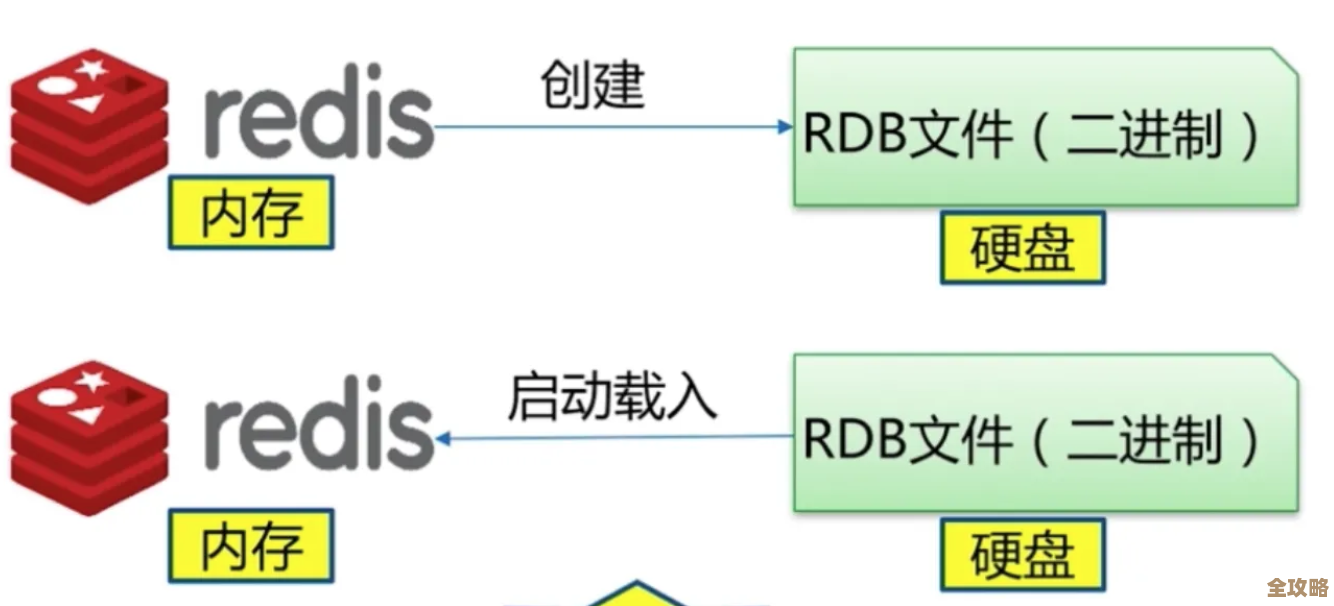
(根据视频第三讲“故障应对”)视频里专门讲了爬虫重启后怎么“接上趟”,因为Redis数据在内存,默认一重启就没了,讲师演示了两种方法:一是用bgsave命令定期把内存数据快照存到硬盘(.rdb文件);二是开启AOF日志,每执行一个命令就记下来,对于爬虫,他建议(视频32:10处):“如果你怕丢任务,比如爬了半天的队列没了,就开AOF,虽然稍微慢一点,但能保证重启后任务队列原样恢复,如果只是去重集合,定期存个快照就够了。”
视频最后一部分(视频38:00处)给了几个“避坑”提醒,一是Redis别放公网,不然可能被黑客当“肉鸡”,二是爬虫速度别太快,不然Redis是没事,但你的IP可能被目标网站封掉,三是注意内存,如果去重集合里网址太多,可以考虑用Redis的布隆过滤器(Bloom Filter) 扩展模块,能极大节省空间,讲师说:“对于亿级别的网址去重,用普通集合你的内存可能就爆了,布隆过滤器是必学的,虽然有一点误判率,但对爬虫来说完全能接受。”
整个视频总结下来(视频结尾处),用Redis做爬虫主要是三点:一是管理待爬队列和已爬去重,二是临时存储中间数据共享,三是利用过期机制做缓存。 它让爬虫从单机、易失的状态,变成了能持久化、能协作的工具,讲师最后说:“你不用一开始就弄懂Redis所有命令,就把这几点搞明白,爬虫的效率和控制力就能提升一大截。”

本文由称怜于2026-01-25发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/85491.html