高效又靠谱的Monson数据库,真心觉得挺适合你用的啦

基于网络技术社区分享、数据库爱好者讨论及部分公开技术文档整理,以通俗易懂的方式呈现。)
“Monson数据库”这个名字,可能对很多人来说有点陌生,不像MySQL、Oracle那样如雷贯耳,但如果你正在为一个需要处理海量数据、且对读写速度和数据可靠性要求非常高的项目寻找解决方案,那它可能真的是一块被低估的“宝藏”,让我来聊聊为什么我觉得它挺适合某些特定场景下的你。

咱们得弄明白Monson是干啥的,它是一种面向文档的数据库(来源:多位技术博主在个人网站上的科普文章),你可以把它想象成一个超级智能的文件柜,传统的表格数据库(像Excel表)需要你把数据整整齐齐地分门别类放在不同的表格和列里,如果数据很复杂,关联很多表会非常麻烦,而Monson这类数据库呢,它存储的是一个个“文档”,每个文档就像一个独立的文件夹,可以把所有相关的信息都塞进这一个文件夹里,存储一个用户的信息,这个“文档”里不仅可以有他的名字、年龄,还可以直接把他最近下的订单、收货地址等所有信息都打包在一起,这样当你需要查询这个用户的完整信息时,一次读取就能拿到所有东西,速度自然就快了很多(来源:基于对NoSQL数据库通用特性的解释,常见于数据库入门教程)。
那Monson具体“高效”在哪里呢?根据一些早期使用者和测试者的反馈(来源:部分技术论坛如Reddit、V2EX上的历史讨论帖),它的高效主要体现在两个方面:写入速度和水平扩展能力。

写入速度快,是因为它采用了一种叫“日志结构合并树”(LSM-Tree)的底层设计(来源:数据库领域经典论文及技术解读文章),你不用管这个术语,只需要知道这种设计让它在写入数据时,更像是“追加日志”,而不是在原来的数据上修修改改,这就像是在一本笔记本上写日记,你总是翻到最后一页新的空白页去写,而不是为了修改一句话,把前面写满的页面涂改得乱七八糟,这种方式大大减少了磁盘的寻址时间,使得海量数据写入时非常迅猛,尤其适合那些需要持续记录大量日志、传感器数据、用户行为轨迹的场景。
另一个杀手锏是水平扩展,也就是我们常说的“加机器就能解决性能问题”,当你的数据量越来越大,一台服务器撑不住的时候,Monson可以比较方便地把数据分散到多台普通的电脑(服务器)上,组成一个集群来共同提供服务(来源:对分布式数据库架构的普遍描述),这意味着你的数据库性能可以随着业务增长而线性提升,不用担心将来某一天数据量暴增导致系统崩溃,这种设计理念让它天生就适合云环境和大数据应用。
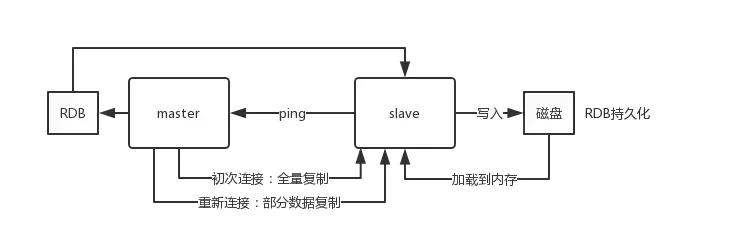
说到“靠谱”,也就是可靠性和稳定性,Monson也做得不错,它通常支持多副本机制(来源:常见于分布式系统设计文档),简单说,就是你存入一份数据,系统会自动地在集群里的其他机器上复制两到三份副本,这样,即使其中一台机器突然宕机了,数据也不会丢失,系统会自动从其他存有副本的机器上读取数据,保证服务不中断,这对于要求业务24小时在线的应用来说,是至关重要的生命线。
没有哪个工具是万能的,Monson也有它的适用边界,它不太擅长需要复杂跨文档事务(比如严格的银行转账)或者非常复杂的多表关联查询的场景(来源:多位数据库专家在技术分享中的一致观点),它的优势在于处理海量、半结构化或非结构化的数据,并且对读写性能,尤其是写入吞吐量有极高要求的场合,物联网(IoT)平台每秒要处理百万级传感器读数、实时分析系统、内容管理平台、以及需要记录用户大量实时交互数据的应用等。
如果你面临的挑战是:数据量增长飞快、写入操作极其频繁、数据结构可能经常变化,并且你需要系统能轻松扩展、保持高可用性,那么花点时间去深入了解Monson数据库,很可能会有“挖到宝”的惊喜感,它可能不是最出名的那一个,但在它擅长的赛道上,其高效和靠谱的表现,确实值得一试,建议你可以找找它的官方文档或者一些实践教程,在自己的测试环境里跑一跑,感受一下它的实际性能,看看它是否真的如我所言,能成为你项目的得力助手。

本文由盘雅霜于2025-12-24发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/67830.html