聊聊未来Redis架构那些事儿,分享一些设计思路和实践经验

今天咱们就敞开聊聊天,说说未来Redis架构可能的发展方向,以及一些在实际工作中摸爬滚打出来的设计思路和经验,这些东西不一定全对,但都是实实在在的体会。
从“单打独斗”到“团队作战”:架构的演进
以前说起Redis,很多人第一反应就是一个速度飞快的内存缓存,把它放在应用和数据库之间,扛住热点数据访问,减轻后端压力,这是最经典的用法,这种时候,Redis就像一个单打独斗的快枪手,目标明确,干就完了。

但后来业务越来越复杂,大家对Redis的期望也高了,不光要当缓存,还想用它存点会话(Session),做排行榜,搞消息队列,甚至当个简单的数据库用,这时候,单枪匹马就有点力不从心了,万一这个“快枪手”宕机了,整个系统可能就瘫了,我们开始给Redis找帮手,组建“团队”。
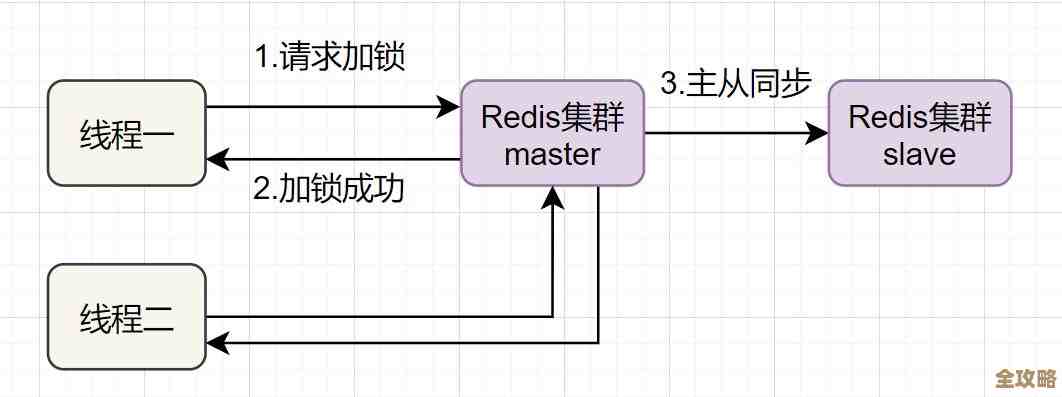
最常见的“团队”形式就是主从复制(Master-Slave),一个主节点负责写,多个从节点负责读,还能在主节点挂掉的时候顶上去,这就像给系统上了个基础保险,但这里面也有学问,比如主从之间的数据同步有延迟,在那一小段时间里,从节点上的数据可能是旧的,如果你做一个扣库存的操作,写到了主节点,但立刻去从节点读,可能读到的还是没扣之前的数量,这就出问题了,设计的时候得想清楚,哪些场景能接受短暂的数据不一致,哪些场景必须读主节点保证强一致性。
再进一步,就是集群(Cluster)模式,当数据量大到一台机器内存装不下,或者写请求多到一台机器处理不过来时,就得用集群把数据分到不同的节点上,这就像一个小队分工合作,每人负责一块,玩集群,最关键的就是数据分片的规则,是简单按照Key的哈希值来分,还是用一致性哈希?这会影响增加或减少节点时,数据迁移的量和系统稳定性,实践经验是,提前规划好容量,尽量避免在业务高峰时折腾集群的扩容缩容,那简直是给自己挖坑。

未来架构的可能模样:云原生与持久化
聊完现在,再大胆聊聊未来,我觉得有两个趋势会比较明显。
第一个是“云原生”化,现在越来越多的公司把业务搬到云上,Redis也不例外,未来的Redis架构可能会和云的基础设施结合得更紧密,云服务商提供的托管版Redis,它会帮你搞定备份、监控、扩缩容这些麻烦事,让你更专注于业务逻辑,这种模式下,架构可能对开发者更“透明”,你不用太操心底下具体是怎么部署的,把它当成一个永远在线、容量无限的黑盒子服务来用就行,但这也有代价,就是定制化的灵活性会降低,而且深度依赖云厂商。

另一个趋势是“持久化”能力的强化,传统Redis虽然也有AOF和RDB两种方式把内存数据存到硬盘,但大家心里都明白,它最擅长的还是内存操作,持久化更多是为了故障恢复,但现在出现了一些新的存储引擎,比如阿里云Tair(根据其官方博客介绍)使用的混合存储架构,它尝试在保持高性能的同时,用更经济的方式存储更大规模的数据,将冷热数据分开处理,可能会有更多Redis或类Redis的产品,在数据持久化和大容量低成本存储方面做出更多创新,让它不仅能做缓存,在某些场景下真正挑战传统数据库的地位。
一些接地气的实践经验
分享几点实实在在的经验,算是踩过坑后的总结。
- Key的设计是灵魂,Key名不要太随意,最好有规律、可读性强,比如
user:123:profile,这方便后期排查问题和做批量操作,别用太长的Key,毕竟它也占内存。 - 警惕“大Key”和“热Key”,一个Value存了几兆甚至几十兆的Hash或List,这就是“大Key”,会导致操作延迟高,网络传输压力大,某个Key的访问频率异常高,成为“热Key”,可能会打爆单个Redis实例的性能瓶颈,解决大Key可以拆分成多个小Key;解决热Key可以通过本地缓存(如Guava Cache)或者复制多份副本来分散压力。
- 设置合理的过期时间,只要是缓存,几乎都要设置过期时间(TTL),这能避免无用数据长期占用内存,也是保证数据最终一致性的简单有效手段,可以设置一个基础的过期时间,然后根据业务特点加一点随机抖动,防止大量Key同时失效导致缓存穿透,把数据库压垮。
- 监控和慢查询日志是你的眼睛,一定要配置好监控,关注内存使用率、连接数、命令耗时等指标,定期查看慢查询日志,找出那些执行时间长的命令,比如用了
KEYS *这种坑爹操作,然后去优化它。
未来的Redis架构肯定会朝着更稳定、更智能、更易用的方向发展,但无论架构怎么变,一些核心的设计思想,比如数据分片、读写分离、容灾备份,都是相通的,咱们要做的就是理解这些原理,结合自己业务的实际情况,灵活运用,才能搭建出最适合自己的那一套东西。
本文由酒紫萱于2025-12-26发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/68702.html