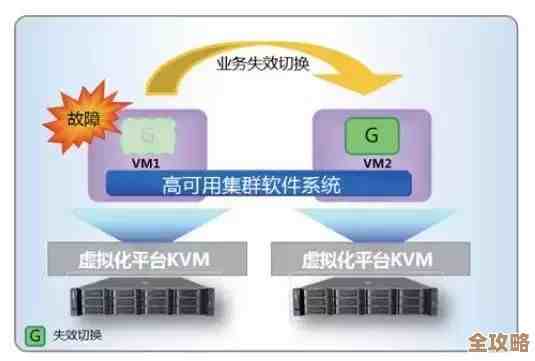
Redis 高可用集群怎么搭建,方案和思路聊聊,不是特别标准但实用

别让 Redis 挂了,或者挂了也能快速恢复,数据尽量不丢。
要达到这个目标,最经典、最实用的方案就是 主从复制 + 哨兵模式,你可以把它理解成一个“一主多仆 + 自动管家”的模式。
第一部分:基础架构——“一主多仆”(主从复制)

这个很好理解,我们弄好几个 Redis 实例(可以在一台机器上开不同端口,但最好是多台机器)。
- 主节点(Master):只有一个,所有写数据的请求(set, push 操作)都发给它,它是数据的唯一写入点。
- 从节点(Slave):可以有一个或多个,它们的主要任务就是“抄作业”,实时地从主节点那里把数据同步过来,读请求(get, lrange 操作)可以发给它们,这样就大大减轻了主节点的压力,实现了读写分离。
怎么搭建?
非常简单,几乎不用改主节点的配置,主要是在从节点的配置文件(redis.conf)里加一行:
replicaof <masterip> <masterport>
比如主节点 IP 是 192.168.1.100,端口是 6379,那你就在从节点的配置里写上 replicaof 192.168.1.100 6379,然后启动从节点就行了,它会自动去主节点那里同步数据,之后主节点有任何数据变化,都会自动流式地同步给从节点。
这样一来,我们实现了数据的多份备份,即使主节点宕机,从节点上也有一份完整的数据,但问题是,现在主节点挂了,写操作就全失败了,需要人工手动去把一个从节点“提拔”成新的主节点,还要改应用程序的配置,太麻烦,而且停机时间会很长。

第二部分:自动故障切换——“自动管家”(哨兵模式)
哨兵就是为了解决上述人工干预的问题而生的,哨兵本身是一个或多个独立的进程,它不存储数据,它的任务就是像个管家一样,时时刻刻盯着主节点和从节点是否健康。
- 哨兵在做什么?
- 监控:哨兵会定期向所有主从节点发送心跳包,检查它们是否还“活着”。
- 自动故障转移:如果主节点在规定时间内没有响应,哨兵就会“认为”主节点挂了(客观下线),多个哨兵会开会投票,选举出一个领头哨兵,由这个领头哨兵来执行自动故障转移。
- 选举新主:领头哨兵会从剩下的健康从节点中,选出一个数据最新的(复制偏移量最大的),把它升级为新的主节点。
- 通知客户端:最关键的一步,哨兵会把新的主节点地址通知给客户端(你的应用程序),这样,你的应用程序就能自动连接到新的主节点上继续写数据,整个过程对用户来说几乎是透明的。
怎么搭建哨兵? 也很简单,你需要创建哨兵的配置文件(sentinel.conf),核心配置就几行:

sentinel monitor mymaster 192.168.1.100 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 15000sentinel monitor mymaster ... 2:告诉哨兵去监控名叫mymaster的主节点(地址是192.168.1.100:6379),最后的2表示至少需要2个哨兵同意才能判定主节点下线。down-after-milliseconds:5000毫秒没响应就认为节点“主观下线”。failover-timeout:故障转移的超时时间。
重要提示:哨兵本身也要部署多个(通常建议3个或以上奇数个),并且分布在不同的机器上,避免哨兵自己成为单点故障。
第三部分:实用但“不标准”的细节和思路
- 从节点读流量分担:在应用程序端,可以把读请求随机或者轮询地分发到各个从节点上,有效降低主节点压力,但要注意,从节点同步数据有毫秒级的延迟,对一致性要求极高的读请求还是要走主节点。
- 脑裂问题与最小化数据丢失:在某个网络抖动的瞬间,哨兵可能误以为主节点挂了,选举出了新主,但实际上老主节点还活着并在接收数据,这时就会出现两个“主节点”,都接收写请求,导致数据混乱,为了解决这个问题,可以在主节点配置中增加
min-replicas-to-write 1,意思是如果主节点连接的从节点数量少于1个,它就拒绝写入,这样在网络分区时,老主节点因为联系不上从节点,就会自动变成只读状态,避免了数据冲突。 - 混合部署的考量:如果机器资源紧张,可以把一个哨兵和一个 Redis 实例(主或从)部署在同一台机器上,但要注意,如果这台机器挂了,你既失去了一个数据副本,也失去了一个哨兵。
- 不是银子弹:主从+哨兵解决了高可用和读扩展,但没有解决数据容量的问题,如果你的数据量非常大,一台机器的内存根本装不下,那就得用官方的 Redis Cluster 方案了,那个是分布式方案,数据是分片存储的,但搭建和维护起来也更复杂一些,对于绝大多数业务场景,主从+哨兵已经完全够用。
总结一下实用步骤:
- 准备至少三台服务器(或虚拟机)。
- 在一台上部署 Redis 主节点。
- 在另外两台上部署 Redis 从节点,并配置它们复制主节点。
- 在三台服务器上分别部署一个哨兵进程,并配置它们监控主节点。
- 在你的应用程序中,使用哨兵提供的客户端连接库(如 Jedis for Java),让客户端通过询问哨兵来获取当前有效的主节点地址。
这套方案虽然不是官方最复杂的 Redis Cluster,但它经过了长时间的考验,简单、稳定、实用,是构建 Redis 高可用服务最经典的路径。
本文由水靖荷于2026-01-01发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/72598.html