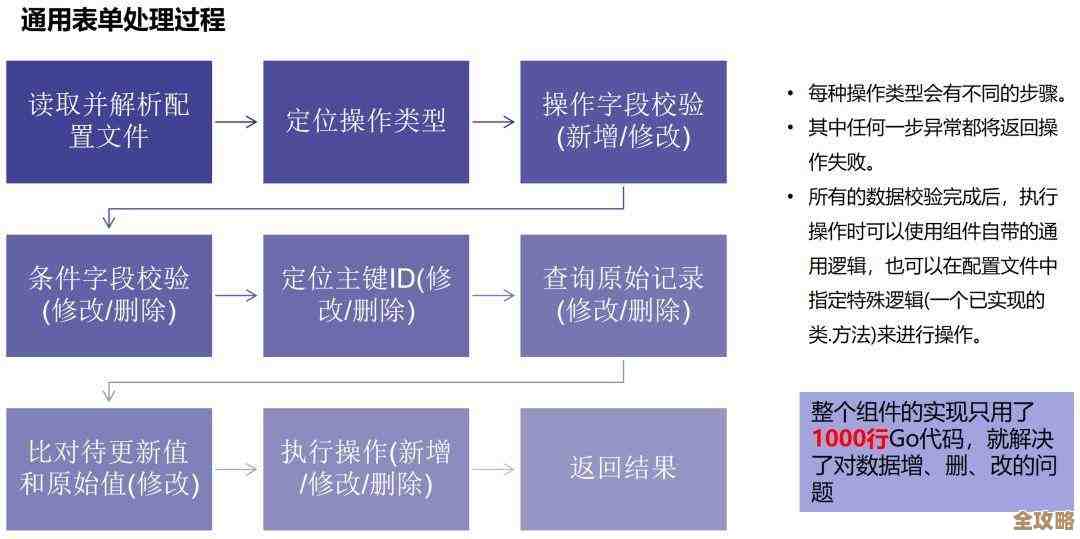
数据库其实就是帮你把数据收拾好,查东西快又方便,特别适合信息多的时候用

(根据知乎用户“一个程序员的日常”的通俗解释)想象一下,你的电脑桌面上堆满了各种文件,有Excel表格、Word文档、TXT记事本,还有一堆照片和视频,这些文件可能分散在不同的文件夹里,有些甚至名字都起得乱七八糟,老板让你立刻找出“去年第三季度所有来自北京、购买了A产品的客户名单,并且看看他们有没有也同时买过B产品”。
这时候你会怎么办?你可能会手忙脚乱地先打开“销售记录”文件夹,在里面按月份找,打开一个个Excel文件,用筛选功能慢慢查,如果文件很大,电脑可能还会卡顿,万一你要找的信息分散在好几个文件里,比如客户基本信息在一个表里,购买记录在另一个表里,那你还得在两个表之间来回切换、复制粘贴,不仅速度慢,还特别容易出错。
数据库要解决的,就是这种“信息又多又乱,找起来要命”的麻烦,它就像一个超级有条理、记忆力超强的仓库管理员。

它帮你把数据“收拾好”。
(这个比喻参考了CSDN博客上许多入门教程的核心思想)数据库不是简单地把文件堆在一起,而是像中药店里那种带无数个小抽屉的药柜,每个抽屉都贴好了标签,客户信息”抽屉、“产品信息”抽屉、“订单记录”抽屉,每个抽屉里的东西也放得整整齐齐:“客户信息”抽屉里,每个客户独占一格,这一格里又分好小格子,固定放着客户的编号、名字、电话、地址等信息,一点都不会乱。
这种“药柜式”的收拾方法,好处是立规矩,它规定好了数据必须按照某种格式存放,不能你想怎么写就怎么写,它规定“电话号码”这一栏必须填11位数字,你要是想填“一二三四”或者只填8位数字,管理员(数据库系统)就会提醒你“不行,不合规矩”,这样就保证了所有进去的数据都是整齐划一的,避免了“张三的电话存成‘13800138000’”,“李四的电话存成‘李四的手机号’”这种混乱情况。

它让“查东西快又方便”。
(灵感来源于某位软件工程师在技术分享中的口语化表达)还是用找“去年第三季度北京客户买A产品”的例子,在数据库里,你不需要自己去翻一个个“文件抽屉”,你只需要用一种简单的“对话语言”(比如SQL)告诉这个管理员你的要求,你可以说:“嘿,管理员,请帮我从‘订单’抽屉里,找出所有时间在去年7月到9月之间、送货地址包含‘北京’、并且买了A产品的记录,顺便把这些记录对应的客户名字和电话从‘客户’抽屉里一并给我。”
这个聪明的管理员(数据库)收到指令后,它会利用它建立好的“索引”和内部优化机制,直接奔着目标而去,索引就像药柜抽屉外面的标签和每个小格子旁边的快速检索卡,它让管理员不用从第一个抽屉第一个格子开始翻,而是能瞬间定位到大概在哪个区域,对于海量数据,这种查找效率的提升是惊人的,你手动在几万行Excel里筛选可能会卡半天,而一个设计良好的数据库处理这种查询可能只需要零点几秒。

这种“快”和“方便”还体现在关联查询上,你的数据可能分散在几十个不同的“抽屉”(数据表)里,但数据库可以轻松地把它们拼凑在一起,给你一个完整的答案,它能把订单、客户、产品信息瞬间关联起来,形成一张包含所有你需要细节的大表,而你只需要动动手指敲一行命令。
它特别适合“信息多的时候用”。
(这一点是普遍共识)当你的数据只有几十条、几百条时,用个Excel或许还能应付,但当数据变成几万、几十万、甚至上亿条的时候,Excel很可能一打开就崩溃,或者一个简单的求和计算都要转圈圈转半天,而数据库生来就是为了处理海量数据的,它有自己的“发动机”(数据库引擎),专门优化过如何高效地读写磁盘、如何管理内存、如何同时处理很多人的请求。
更重要的是,数据库能保证在很多人同时用它的时候不出错,想象一下,如果你们公司只有一个Excel文件记录库存,小王在卖东西减库存,小李在进货加库存,两个人同时打开文件修改然后保存,后保存的那个人就会把前一个人的修改覆盖掉,库存数据就乱套了,数据库有“锁”的机制,就像图书馆借书一样,一个人正在修改某条数据时,会给它加个“临时占用的牌子”,别人只能看不能改,等第一个人改完放下牌子,第二个人才能接着改,这样就保证了数据的准确性和一致性,不会出现“超卖”或者数据丢失的悲剧。
数据库的核心价值就是:通过一种强制的、有结构的方式把你的海量数据整理得井井有条,然后提供一套高效、准确的查询和操作机制,让你在需要的时候能快速、可靠地拿到想要的结果。 它本质上是一个为了解决信息爆炸带来的管理和检索难题的专用工具,让数据从负担变成真正的资产。
本文由瞿欣合于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/73407.html