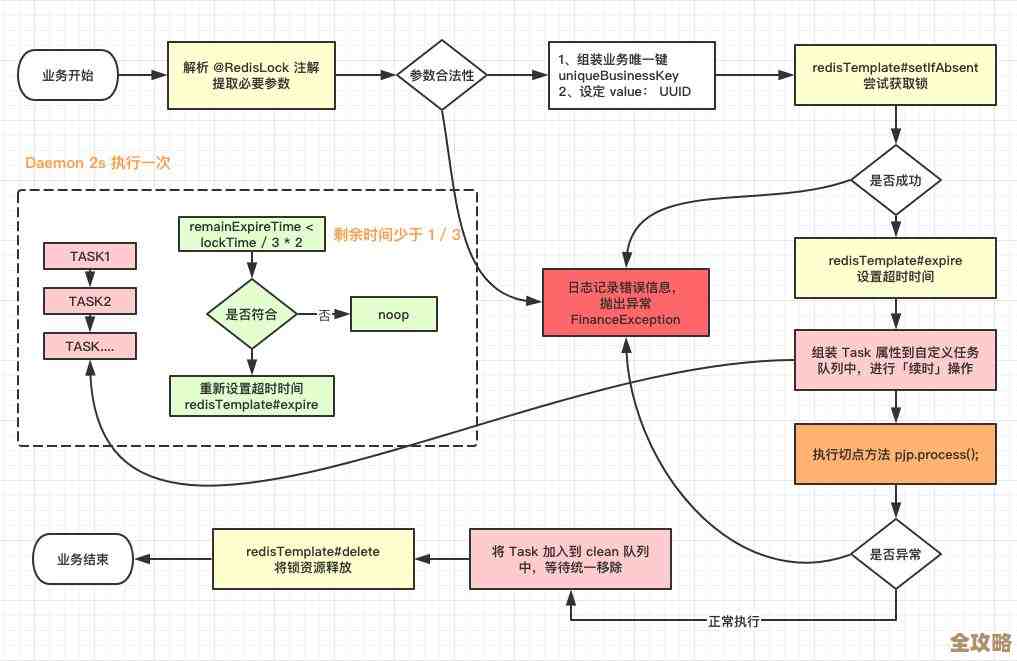
红色闪电带你扒一扒redis架构师那些面试题,深度剖析不容错过

(根据网络技术社区“红色闪电”分享的Redis架构师面试常见问题整理)
开场就是暴击:Redis为什么这么快?
这基本上是开场必问的,用来热身的,你不能只说个“内存操作”就完了,那肯定不及格,得掰开了揉碎了说。
内存操作是基础,数据都在内存里,直接读写,跟磁盘I/O比起来不是一个量级。单线程模型是关键,很多人误解单线程会慢,其实不然,Redis的单线程指的是核心的网络I/O和键值对读写是由一个线程完成的,这就避免了多线程的上下文切换和竞争条件带来的开销,是个非常清爽的设计,它使用了I/O多路复用技术(像epoll、kqueue),这个技术让单个线程能高效处理成千上万的网络连接请求,线程不会傻等着某个连接,而是哪个连接有数据来了就处理哪个,Redis自身用了C语言编写,离操作系统近,而且数据结构设计得非常精炼,比如各种压缩的链表、跳跃表等,进一步提升了效率。
数据持久化:AOF和RDB怎么选?这是个大坑
架构师面试肯定会深入到数据安全层面,Redis有两种主要的持久化方式:RDB和AOF。

- RDB(快照):就像是给数据库拍一张完整的照片,在特定时间点,把内存里所有数据生成一个快照文件(dump.rdb),优点是文件紧凑,恢复大数据集时速度很快,缺点是可能会丢失最后一次快照之后的所有数据(比如你设置5分钟拍一次,服务器在第4分钟宕机了,那这4分钟的数据就没了)。
- AOF(追加日志):更像是写日记,把每一个写操作命令都记录下来,追加到一个文件里,重启的时候就把这些命令重新执行一遍来恢复数据,优点是数据安全性高,最多丢失一秒的数据(如果配置为每秒同步一次),缺点是文件通常比RDB大,恢复速度慢。
怎么选? 这就能看出你的经验了,通常生产环境会两者结合使用,用AOF来保证数据不丢失,作为数据恢复的第一选择;同时定期用RDB来做一次冷备,因为RDB的文件更适合做灾难恢复和快速重启,面试官可能会追问如果AOF文件过大怎么办?这时候你就要提到AOF重写机制了,Redis会fork一个子进程,根据当前数据库状态生成一个新的、更小的AOF文件来替换旧的。
高可用和集群:主从、哨兵、Cluster模式到底咋回事?
单机Redis有风险,一挂全完蛋,所以高可用和扩展性是架构师必须掌握的。

- 主从复制(Replication):最简单的方式,一个主节点(Master),多个从节点(Slave),主节点负责写,数据会异步同步到从节点,从节点主要负责读,这样可以做读写分离,但主节点挂了需要手动切换,不够自动化。
- 哨兵模式(Sentinel):在主从的基础上,加了一群“哨兵”,哨兵是独立的进程,它们不提供服务,专门负责监控主节点和从节点是否健康,如果发现主节点挂了,哨兵们会开会投票,自动选出一个从节点升级为新的主节点,并通知客户端切换连接,它解决了高可用的问题,但本质上还是只有一个主节点负责写,写操作的容量和压力问题没解决。
- Cluster模式(集群):这是Redis官方提供的分布式解决方案,它把数据自动分片(sharding)到多个主节点上,每个主节点负责一部分数据槽(slot),每个主节点还可以有从节点做备份,这样既实现了负载分担(多个节点都可以写),又实现了高可用,这是应对海量数据和高并发场景的终极方案,面试官很可能会让你描述一下数据是怎么分片的,以及客户端如何知道一个键应该存到哪个节点上(通过CRC16哈希算法计算键的slot,再映射到节点)。
缓存问题:雪崩、穿透、击穿,怎么应对?
用Redis做缓存,这三个问题是绕不开的,必须要有实战解决方案。
- 缓存雪崩:指大量缓存数据在同一时间过期失效,导致所有请求都砸到数据库上,数据库压力骤增甚至崩溃。解决方案:给缓存数据的过期时间加上一个随机值,避免集体失效;或者设置热点数据永不过期。
- 缓存穿透:指查询一个根本不存在的数据,缓存里没有,数据库也没有,导致这个无效请求每次都会绕过缓存去查数据库,可能被恶意攻击。解决方案:1. 对请求参数做校验,非法请求直接过滤掉,2. 即使数据库查不到,也把这个空结果(比如null)缓存在Redis里,并设置一个较短的过期时间,3. 使用布隆过滤器(Bloom Filter)这种数据结构,在查询缓存前先经过布隆过滤器判断是否存在,如果判断不存在就直接返回,避免对数据库的压力。
- 缓存击穿:指一个非常热点的key突然过期了,此时大量并发请求这个key,瞬间击穿缓存,全部请求落到数据库。解决方案:1. 设置热点数据永不过期,2. 使用互斥锁(mutex key),当缓存失效时,不是所有人都去查数据库,而是让一个请求去查数据库并重建缓存,其他请求等待缓存重建完成后直接读取新缓存。
实战场景题:比如如何实现一个延迟队列?
这类题考察你的知识迁移能力和实际应用能力,用Redis实现延迟队列一个常见的方案是使用有序集合(ZSET),把消息内容作为member,把消息的延迟执行时间(比如当前时间戳+5秒)作为score存入ZSET,然后起一个轮询进程,用ZRANGEBYSCORE命令不断检查score小于等于当前时间戳的消息,把它们取出来执行,执行成功后从ZSET中移除,这就是一个简单可靠的延迟队列模型。
就是“红色闪电”分享中比较核心的Redis架构师面试题剖析,这些问题由浅入深,覆盖了性能、持久化、高可用、缓存经典问题和实际应用,确实是深度剖析不容错过。
本文由歧云亭于2026-01-03发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/73586.html