从零摸索到精通Redis架构,这条成长路其实没那么简单也挺有趣

主要整合自多位资深技术专家在个人博客、技术社区如CSDN、InfoQ上的分享,以及《Redis设计与实现》等书籍中的核心理念,以一条虚构的开发者成长路径来呈现)
记得我刚工作那会儿,第一次听说Redis,前辈就甩给我一句:“这是个key-value缓存,速度贼快,你先用着。” 我当时的理解,就是把Redis当成一个超级快的HashMap,代码里需要临时存个用户会话Session,或者把一些耗时的数据库查询结果丢进去,避免每次都去查数据库,那时候觉得,这有啥难的?不就是set、get、del几个命令嘛,一下午就“学会”了。(来源:普遍新手开发者入门经历)
这种“岁月静好”的日子没过多久,问题就来了,首先是内存报警,因为我把整个用户对象序列化后不分青红皂白地往里塞,没多久内存就快撑爆了,接着是数据一致性问题,比如用户改了昵称,我有时会忘了更新Redis里的缓存,导致页面上显示的还是旧名字,最崩溃的一次是Redis服务器宕机重启,所有数据都没了,整个网站功能半瘫痪,我才意识到我没做任何持久化设置,这时我才明白,Redis不是个“傻快”的字典,用它首先得有时刻警惕的“运维意识”。(来源:常见缓存使用误区与踩坑总结)
吃了亏,我开始认真看文档,这一看,打开了新世界的大门,原来Redis不只有String类型,还有List、Set、Hash、Zset这些数据结构,我发现自己以前用String类型拼命拼接字符串来模拟列表功能是多么愚蠢,比如要做个简单的消息队列,直接用LPUSH和RPOP操作List就行了;要存一个用户的多个属性,用Hash结构不仅能节省大量内存,还能单独更新某个字段,简直太方便了,我开始学着根据业务场景选择最合适的数据结构,这是走向“精通”非常关键的一步。(来源:《Redis设计与实现》中关于数据类型的章节)
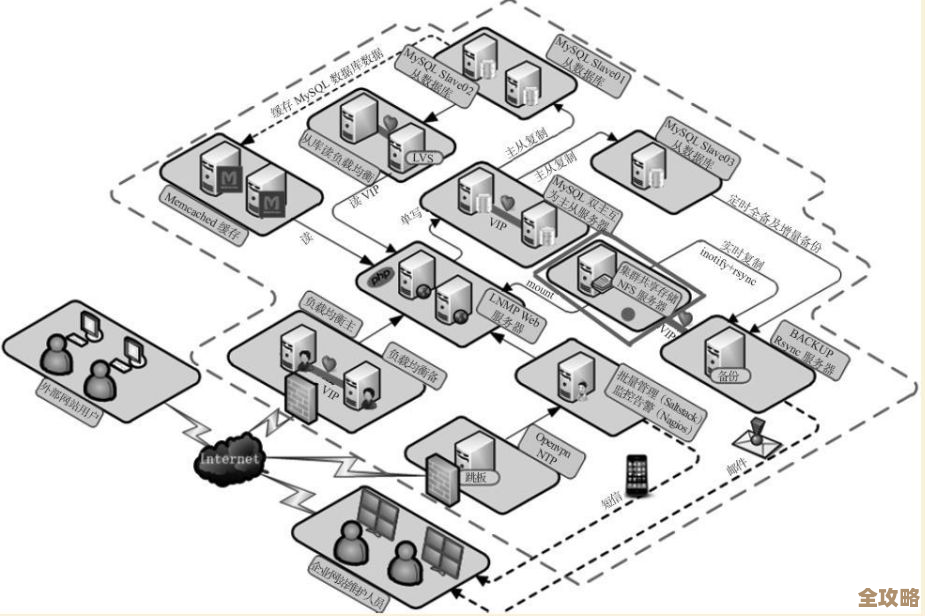
随着业务越来越复杂,单机的Redis又开始不够用了,高并发下,单个实例CPU扛不住;容量有上限,无法无限扩展,这时,我必须面对“架构”这个词了,我开始研究主从复制(Replication),弄一个备库(Slave)出来,平时做读写分离分担主库(Master)的压力,主库挂了还能手动切换成备库顶上,实现了最基本的高可用。(来源:Redis官方文档关于复制的部分)
但手动切换毕竟不靠谱,于是又引入了Sentinel(哨兵)机制,哨兵可以自动监控主从库的健康状态,并在主库宕机时自动完成故障转移,选举出新的主库,这套方案让系统的可用性提高了不少,我一度觉得已经挺完美了,但很快,新的问题又出现了:数据容量单机还是装不下,海量数据怎么办?(来源:技术社区中关于Redis高可用方案的讨论文章)
答案就是分片(Sharding),也就是Redis Cluster集群模式,这是真正意义上的分布式Redis,它把数据自动分到多个主节点上,每个节点只存储一部分数据,这样就实现了水平和扩容,学习Cluster的过程是最烧脑的,要理解数据是怎么通过哈希槽(slot)分布的,客户端又是如何直接路由到正确节点的,以及集群在节点增减时如何重新分配数据,这时候,光会敲命令已经远远不够了,得深入理解分布式系统的概念,比如一致性哈希、CAP理论、故障转移的细节等。(来源:《Redis开发与运维》等书籍中对Cluster的深入讲解)
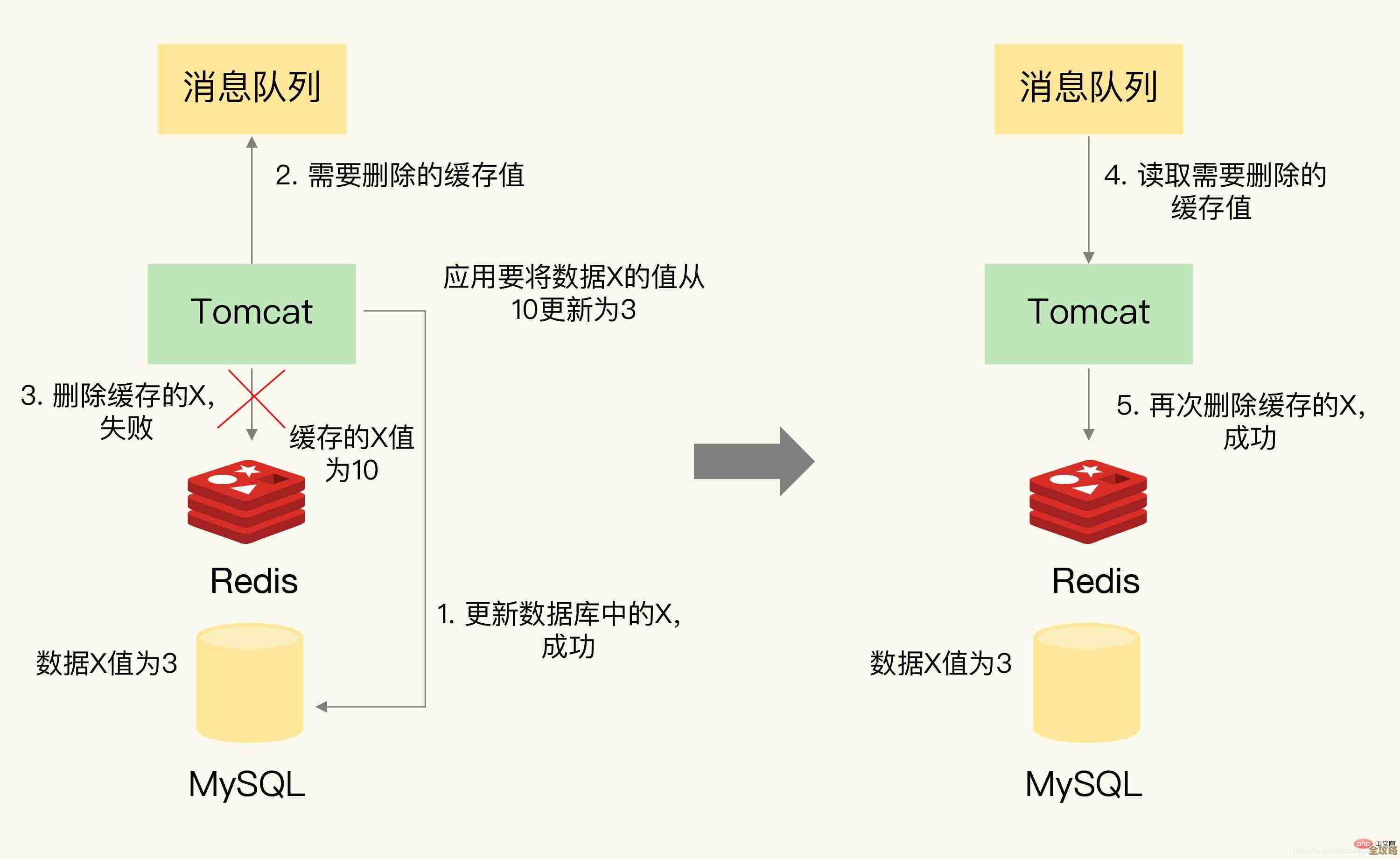
走到这里,我以为自己已经“精通”了,但一次线上事故让我清醒,当时集群一个节点网络波动,导致主从切换,但在切换的瞬间,有少量数据发生了丢失,我们排查后发现,这涉及到复制延迟、客户端重试机制、脑裂问题等一系列极端场景下的深水区问题,真正的“精通”,不仅仅是会搭建和维护一个复杂的架构,更是要理解这个架构在各种异常情况下的行为边界,并准备好应对策略,比如是否需要更严格的持久化配置,是否需要在客户端做兼容性处理等。(来源:一线大厂技术团队分享的Redis高可用实战经验与踩坑案例)
回头看这条从零到精通的路径,它真的不简单,它不是一条平滑的直线,而是一个不断遇到问题、解决问题、然后发现更大更复杂问题的螺旋式上升过程,从最初的一个简单缓存工具,到数据结构的最佳实践,再到高可用、分布式的复杂架构,每一个阶段都有新的挑战和乐趣,有趣的地方也正在于此,你总能不断发现自己的知识盲区,然后像打怪升级一样,一点点把它点亮,这条路没有终点,因为技术和业务总是在演进,但这个过程本身,对于一名开发者来说,就是最大的收获和乐趣所在。

本文由凤伟才于2026-01-04发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/74150.html