MSSQL里那些系统命令怎么用才顺手,分享点实操小技巧和经验

知道自己库里都有啥
刚开始用MSSQL的时候,最头疼的就是接手一个老项目,数据库里几百张表,两眼一抹黑,这时候别急着去SSMS里一个个点开看,直接用查询窗口敲命令,又快又准。
-
找表技巧:比如老板让你找个跟“用户订单”相关的表,但你不知道表具体叫啥名,别懵,用这个:
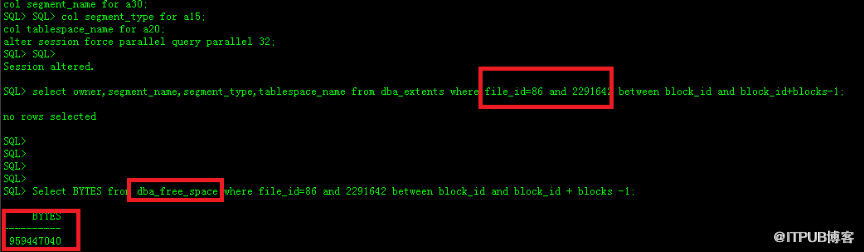
SELECT * FROM sysobjects WHERE name LIKE '%order%' AND xtype='U'
这里
sysobjects是个系统视图,算是数据库的“花名册”。name LIKE '%order%'就是找名字里带“order”的,xtype='U'是限定只找用户表,一下子就能把类似Order,OrderDetails,BackupOrder这样的表都筛出来,比在图形界面里手动翻快多了。(来源:早期版本常用,现在更推荐使用sys.tables) -
查看表结构:找到表名了,下一步就是看看它长啥样,有哪些字段。
sp_help这个存储过程是神器:sp_help '你的表名'
sp_help 'Orders',一执行,结果会分成好几个表格返回来,表的基本信息、所有列的名字、类型、是否允许空值,连上面有什么索引、约束都给你列得明明白白,对于快速了解一张陌生表,没有比这更全面的了。
日常维护:备份、看谁在捣乱
-
快速备份与还原:虽然图形界面点几下也能备份,但有时候需要写个脚本自动执行,或者备份到特定路径,基本命令很简单:
-- 完整备份 BACKUP DATABASE 你的数据库名 TO DISK = 'D:\Backup\你的数据库名.bak' WITH INIT -- 还原 RESTORE DATABASE 你的数据库名 FROM DISK = 'D:\Backup\你的数据库名.bak' WITH REPLACE
这里的
WITH INIT意思是覆盖掉备份文件里旧的内容,每次都创建一个新的。WITH REPLACE在还原时特别重要,意思是即使数据库已经存在也强制覆盖,不然经常会因为一些进程占用之类的问题还原失败。注意:用REPLACE要非常小心,除非你确定要覆盖当前数据库。 -
揪出耗资源的查询:有时候感觉数据库突然卡死了,页面转圈,肯定是哪个家伙跑了个超级慢的查询,这时候赶紧开个新查询窗口,用这个命令看看:
SELECT session_id, status, command, text, cpu_time, total_elapsed_time, reads, writes FROM sys.dm_exec_requests CROSS APPLY sys.dm_exec_sql_text(sql_handle) WHERE session_id > 50 -- 过滤掉系统进程 ORDER BY total_elapsed_time DESC
这个命令是从动态管理视图
sys.dm_exec_requests里抓取当前正在执行的请求。total_elapsed_time是总耗时,排个序,哪个查询跑得最久一目了然。text字段直接就能看到它执行的SQL代码,找到元凶后,如果确认它有问题,可以用KILL session_id命令把它强行终止掉,算是救急的一招。
提升效率:索引和查询优化
索引这东西,用好了是神器,用不好是累赘,我们不需要成为专家,但得会看个大概。
-
看看索引有没有用:建了一堆索引,到底有没有被用到?别猜,让数据说话:
SELECT OBJECT_NAME(s.object_id) AS 表名, i.name AS 索引名, user_seeks, user_scans, user_lookups, user_updates FROM sys.dm_db_index_usage_stats s INNER JOIN sys.indexes i ON s.object_id = i.object_id AND s.index_id = i.index_id WHERE OBJECT_NAME(s.object_id) = '你的表名'user_seeks(索引查找)、user_scans(索引扫描)是索引被用来查询的次数,user_updates是索引因为数据增删改而被更新的次数,如果一个索引user_updates很高,但user_seeks和user_scans都是0或者很低,说明这个索引维护的成本远大于它带来的查询收益,基本就是个摆设,可以考虑删掉了。 -
查看缺失索引:SQL Server 很智能,它会记录下“如果有个什么样的索引,我能跑得更快”这样的建议,我们可以查询这些建议:
SELECT TOP 10 * FROM sys.dm_db_missing_index_details
结果里会告诉你哪个数据库、哪张表、哪些列如果建了索引会更好。但是要注意,这个建议不能全盘照收,它只考虑查询性能,不考虑更新数据的开销,你需要自己判断,比如它建议的列是不是经常出现在
WHERE或JOIN条件里,再决定是否创建。
几个顺手的小习惯
- 永远在
SELECT里带上TOP:尤其是在查询生产环境的大表时,即使你知道数据量不大,也先习惯性地写成SELECT TOP 1000 * FROM ...,这样可以避免万一手抖忘了写条件,一个SELECT *拉出几百万行数据把网络和内存撑爆的悲剧。 - 用
SSMS的快捷键:Ctrl + R快速显示/隐藏结果面板,当你的查询结果列很多,想全屏看SQL代码时非常有用。Ctrl + T把结果以文本形式输出,有时候比网格视图更简洁。 - 动态SQL要谨慎:拼接SQL字符串(动态SQL)虽然灵活,但很容易引入SQL注入漏洞,而且不好调试,如果非用不可,一定要对输入参数做严格的检查和过滤。
这些东西都不是什么秘密,多在微软的官方文档(来源:Microsoft Docs, 现在叫 Learn)里泡一泡,或者当你遇到问题时,直接把你遇到的现象比如“SQL Server query running slow”拿去搜,总能找到类似 sys.dm_exec_requests 这样的工具,用多了,这些命令自然就顺手了。

本文由黎家于2026-01-09发表在笙亿网络策划,如有疑问,请联系我们。
本文链接:https://haoid.cn/wenda/77373.html